关联规则之Aprior算法
关联规则挖掘在电商、零售、大气物理、生物医学已经有了广泛的应用,本篇文章将介绍一些基本知识和Aprori算法。
啤酒与尿布的故事已经成为了关联规则挖掘的经典案例,还有人专门出了一本书《啤酒与尿布》,虽然说这个故事是哈弗商学院杜撰出来的,但确实能很好的解释关联规则挖掘的原理。我们这里以一个超市购物篮迷你数据集来解释关联规则挖掘的基本概念:
| TID | Items |
| T1 | {牛奶,面包} |
| T2 | {面包,尿布,啤酒,鸡蛋} |
| T3 | {牛奶,尿布,啤酒,可乐} |
| T4 | {面包,牛奶,尿布,啤酒} |
| T5 | {面包,牛奶,尿布,可乐} |
一、关联规则、自信度、自持度的定义 表中的每一行代表一次购买清单(注意你购买十盒牛奶也只计一次,即只记录某个商品的出现与否)。数据记录的所有项的集合称为总项集,上表中的总项集S={牛奶,面包,尿布,啤酒,鸡蛋,可乐}。
关联规则就是有关联的规则,形式是这样定义的:两个不相交的非空集合X、Y,如果有X-->Y,就说X-->Y是一条关联规则。举个例子,在上面的表中,我们发现购买啤酒就一定会购买尿布,{啤酒}-->{尿布}就是一条关联规则。关联规则的强度用支持度(support)和自信度(confidence)来描述,
支持度的定义:support(X-->Y) = |X交Y|/N=集合X与集合Y中的项在一条记录中同时出现的次数/数据记录的个数。例如:support({啤酒}-->{尿布}) = 啤酒和尿布同时出现的次数/数据记录数 = 3/5=60%。
自信度的定义:confidence(X-->Y) = |X交Y|/|X| = 集合X与集合Y中的项在一条记录中同时出现的次数/集合X出现的个数 。例如:confidence({啤酒}-->{尿布}) = 啤酒和尿布同时出现的次数/啤酒出现的次数=3/3=100%;confidence({尿布}-->{啤酒}) = 啤酒和尿布同时出现的次数/尿布出现的次数 = 3/4 = 75%。
这里定义的支持度和自信度都是相对的支持度和自信度,不是绝对支持度,绝对支持度abs_support = 数据记录数N*support。
支持度和自信度越高,说明规则越强,关联规则挖掘就是挖掘出满足一定强度的规则。
二、关联规则挖掘的定义与步骤
关联规则挖掘的定义:给定一个交易数据集T,找出其中所有支持度support >= min_support、自信度confidence >= min_confidence的关联规则。
有一个简单而粗鲁的方法可以找出所需要的规则,那就是穷举项集的所有组合,并测试每个组合是否满足条件,一个元素个数为n的项集的组合个数为2^n-1(除去空集),所需要的时间复杂度明显为O(2^N),对于普通的超市,其商品的项集数也在1万以上,用指数时间复杂度的算法不能在可接受的时间内解决问题。怎样快速挖出满足条件的关联规则是关联挖掘的需要解决的主要问题。
仔细想一下,我们会发现对于{啤酒-->尿布},{尿布-->啤酒}这两个规则的支持度实际上只需要计算{尿布,啤酒}的支持度,即它们交集的支持度。于是我们把关联规则挖掘分两步进行:
1)生成频繁项集
这一阶段找出所有满足最小支持度的项集,找出的这些项集称为频繁项集。
2)生成规则
在上一步产生的频繁项集的基础上生成满足最小自信度的规则,产生的规则称为强规则。
关联规则挖掘所花费的时间主要是在生成频繁项集上,因为找出的频繁项集往往不会很多,利用频繁项集生成规则也就不会花太多的时间,而生成频繁项集需要测试很多的备选项集,如果不加优化,所需的时间是O(2^N)。
三、Apriori定律
为了减少频繁项集的生成时间,我们应该尽早的消除一些完全不可能是频繁项集的集合,Apriori的两条定律就是干这事的。
Apriori定律1):如果一个集合是频繁项集,则它的所有子集都是频繁项集。举例:假设一个集合{A,B}是频繁项集,即A、B同时出现在一条记录的次数大于等于最小支持度min_support,则它的子集{A},{B}出现次数必定大于等于min_support,即它的子集都是频繁项集。
Apriori定律2):如果一个集合不是频繁项集,则它的所有超集都不是频繁项集。举例:假设集合{A}不是频繁项集,即A出现的次数小于min_support,则它的任何超集如{A,B}出现的次数必定小于min_support,因此其超集必定也不是频繁项集。
利用这两条定律,我们抛掉很多的候选项集,Apriori算法就是利用这两个定理来实现快速挖掘频繁项集的。
四、Apriori算法
Apriori是由a priori合并而来的,它的意思是后面的是在前面的基础上推出来的,即先验推导,怎么个先验法,其实就是二级频繁项集是在一级频繁项集的基础上产生的,三级频繁项集是在二级频繁项集的基础上产生的,以此类推。
Apriori算法属于候选消除算法,是一个生成候选集、消除不满足条件的候选集、并不断循环直到不再产生候选集的过程。
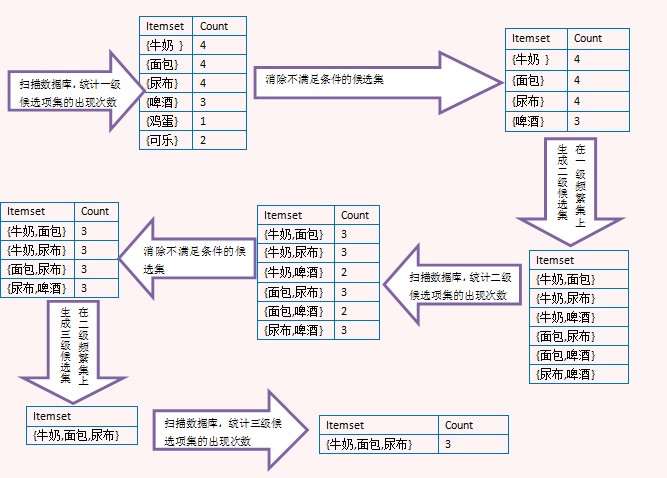
上面的图演示了Apriori算法的过程,注意看由二级频繁项集生成三级候选项集时,没有{牛奶,面包,啤酒},那是因为{面包,啤酒}不是二级频繁项集,这里利用了Apriori定理。最后生成三级频繁项集后,没有更高一级的候选项集,因此整个算法结束,{牛奶,面包,尿布}是最大频繁子集。
算法的思想知道了,这里也就不上伪代码了,我认为理解了算法的思想后,子集去构思实现才能理解更深刻,这里贴一下我的关键代码:
public static void main(String[] args) {
// TODO Auto-generated method stub
record = getRecord();// 获取原始数据记录
List<List<String>> cItemset = findFirstCandidate();// 获取第一次的备选集
List<List<String>> lItemset = getSupportedItemset(cItemset);// 获取备选集cItemset满足支持的集合
while (endTag != true) {// 只要能继续挖掘
List<List<String>> ckItemset = getNextCandidate(lItemset);// 获取第下一次的备选集
List<List<String>> lkItemset = getSupportedItemset(ckItemset);// 获取备选集cItemset满足支持的集合
getConfidencedItemset(lkItemset, lItemset, dkCountMap, dCountMap);// 获取备选集cItemset满足置信度的集合
if (confItemset.size() != 0)// 满足置信度的集合不为空
printConfItemset(confItemset);// 打印满足置信度的集合
confItemset.clear();// 清空置信度的集合
cItemset = ckItemset;// 保存数据,为下次循环迭代准备
lItemset = lkItemset;
dCountMap.clear();
dCountMap.putAll(dkCountMap);
}
如果想看完整的代码,可以查看我的github,数据集的格式跟本文所述的略有不通,但不影响对算法的理解。
下一篇将介绍效率更高的算法--FP-Grow算法。
参考文档:http://www.cnblogs.com/fengfenggirl/p/associate_apriori.html
关联规则之Aprior算法的更多相关文章
- 关联规则之Aprior算法(购物篮分析)
0.支持度与置信度 <mahout实战>与<机器学习实战>一起该买的记录数占所有商品记录总数的比例——支持度(整体) 买了<mahout实战>与<机器学习实战 ...
- 数据挖掘系列 (1) 关联规则挖掘基本概念与 Aprior 算法
转自:http://www.cnblogs.com/fengfenggirl/p/associate_apriori.html 数据挖掘系列 (1) 关联规则挖掘基本概念与 Aprior 算法 我计划 ...
- 数据关联分析 association analysis (Aprior算法,python代码)
1基本概念 购物篮事务(market basket transaction),如下表,表中每一行对应一个事务,包含唯一标识TID,和购买的商品集合.本文介绍一种成为关联分析(association a ...
- 基于FP-Tree的关联规则FP-Growth推荐算法Java实现
基于FP-Tree的关联规则FP-Growth推荐算法Java实现 package edu.test.ch8; import java.util.ArrayList; import java.util ...
- 数据挖掘进阶之关联规则挖掘FP-Growth算法
数据挖掘进阶之关联规则挖掘FP-Growth算法 绪 近期在写论文方面涉及到了数据挖掘,需要通过数据挖掘方法实现软件与用户间交互模式的获取.分析与分类研究.主要涉及到关联规则与序列模式挖掘两块.关联规 ...
- 数据挖掘:关联规则的apriori算法在weka的源码分析
相对于机器学习,关联规则的apriori算法更偏向于数据挖掘. 1) 测试文档中调用weka的关联规则apriori算法,如下 try { File file = new File("F:\ ...
- 数据挖掘Aprior算法详解及c++源码
[算法大致描述] Aprior算法主要有两个操作,扫描数据库+统计.计算每一阶频繁项集都要扫描一次数据库并且统计出满足支持度的n阶项集. [算法主要步骤] 一.频繁一项集 算法开始第一步,通过扫描数据 ...
- 数据挖掘系列(1)关联规则挖掘基本概念与Aprior算法
整理数据挖掘的基本概念和算法,包括关联规则挖掘.分类.聚类的常用算法,敬请期待.今天讲的是关联规则挖掘的最基本的知识. 关联规则挖掘在电商.零售.大气物理.生物医学已经有了广泛的应用,本篇文章将介绍一 ...
- 增量关联规则挖掘—FUP算法
一.背景介绍 关联规则( Association rule)概念最初由Agrawal提出,是数据挖掘的一个重要研究领域, 其目的是发现数据集中有用的频繁模式. 静态关联规则挖掘,是在固定数据集和支持度 ...
随机推荐
- VC++ DLL 1 一点概念
1.在写代码的时候,我们可能会经常要用到一些封装好的函数或者类,这些可能是C/C++的标准库提供的,也可能是由别人开发的非标准库,这个时候就会涉及到动态链接库或者静态链接库的使用了. 举个例子,做图像 ...
- adaboost 基于错误提升分类器
引自(机器学习实战) 简单概念 Adaboost是一种弱学习算法到强学习算法,这里的弱和强学习算法,指的当然都是分类器,首先我们需要简单介绍几个概念. 1:弱学习器:在二分情况下弱分类器的错误率会低于 ...
- 直击JDD | 陈生强:京东数科的底层是数字化操作系统
11月19日,由京东集团主办的JDD-2019京东全球科技探索者大会在京开幕,京东数字科技集团CEO陈生强作了题为"以科技为美,为价值而生"的主旨发言,再论"数字科技&q ...
- 查看docker的挂载目录
docker inspect container_name | grep Mounts -A 20docker inspect container_id | grep Mounts -A 20
- sync实现windows与nginx主机端文件同步(参考文档)
资源 Rsync官网:http://rsync.samba.org/ 简介 Rsync(remote sync)是类unix系统下的远程(LAN/WAN)数据镜像备份工具.可以实现Linux与linu ...
- IDEA常用技巧以及快捷键总结
一.常用快捷键 快捷键 描述 Ctrl+o 复写父类方法 Alt+7 查看类所有方法实现 Ctrl+Alt+H 方法调用链
- python刷LeetCode:2.两数相加
难度等级:中等 题目描述: 给出两个 非空 的链表用来表示两个非负的整数.其中,它们各自的位数是按照 逆序 的方式存储的,并且它们的每个节点只能存储 一位 数字. 如果,我们将这两个数相加起来,则会返 ...
- 梯度消失、梯度爆炸以及Kaggle房价预测
梯度消失.梯度爆炸以及Kaggle房价预测 梯度消失和梯度爆炸 考虑到环境因素的其他问题 Kaggle房价预测 梯度消失和梯度爆炸 深度模型有关数值稳定性的典型问题是消失(vanishing)和爆炸( ...
- bfs--奇怪的电梯P1135
计院有一个bug电梯,可能是hyk造的,很多bug,电梯只有两个按钮,“上”和“下”,电梯每层都可以停,每层都有一个数字Ki(0<=Ki<=n),当你在一层楼,你按“上”键会到1+K1层, ...
- 将元素平分成差值最小的两个集合(DP)
现有若干物品,要分成较为平均的两部分,分的规则是这样的: 1)两部分物品的个数最多只能差一个. 2)每部分物品的权值总和必须要尽可能接近. 现在请你编写一个程序,给定现在有的物品的个数以及每个物品的权 ...