pyspider_初始
一、简介
1.1、简介
pyspider 是一个使用python编写,并且拥有强大功能web界面的爬虫框架。
强大的web界面可进行脚本编辑,任务监控,项目管理,结果查看等功能。
pyspider支持多种数据库进行数据存储。MySQL, MongoDB, Redis, SQLite, Elasticsearch...(保存数据,默认使用sqlit3)
并且支持多种消息队列。RabbitMQ, Beanstalk, Redis...(用于调度器进行各个组件的协调工作,数据传递等。)
通过装饰器,配置任务优先级,爬虫什么时侯再重新爬取,任务失败再从新自动抓取...
可使用phantomjs,只需要添加参数,就可对动态页面进行爬取..
支持python2,python3.
1.2、框架结构

通过上面的图,我们可以看出pyspider由四部分组成
- Scheduler:任务管理,多个模块之间的协调管理控制。
- Fetcher:发送请求,获取响应,这里还可以调用phantomjs。
- Processor:对返回的数据进行提取,保存等。
- webui/monitor:可视化的方式实现脚本编写,任务管理,监控,调度,结果展示。
1.3、pyspider工作流程:
def on_start(self):
self.crawl('https://travel.qunar.com/?from=header', callback=self.index_page)
当我们启动一个pyspider项目时,默认会调用如上方法。该方法会将第一个任务加入newtask_queue(默认使用python多进程中的队列。调度器(Scheduler)会从任务队列(newtask_queue)中拿出任务交给抓取器(Fetcher),进行页面请求。将数据发送给处理器(Processor)进行数据提取,如果有继续需要请求的url,请再次调用self.crawl方法,则该任务会被加入任务队列,等待调度器进行调度
二、安装
pip install pyspider
pip uninstall wsgidav #直接安装pyspider 默认这个库版本为3.+,会报错,要使用 2.+版本。
pip install wsgidav==2.4.1
2.1、启动命令:
pyspider #在哪里启动pyspider,数据文件就会位于哪里,可以通过配置文件进行修改。
2.2、访问界面
http://127.0.0.1:5000/
2.3、仪表盘各项功能简介
访问上面的url,我们可以进入到pyspider的管理界面
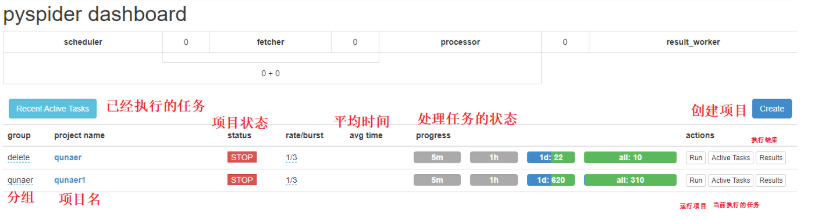
2.4、重要
项目状态有如下分类
TODO一个项目被创建,等待编写脚本执行STOP停止一个运行的项目CHECKING,如果我们需要对一个运行中的项目,进行修改,则应设置为该状态。DEBUG/RUNNING,我们想执行一个项目,则需要将状态设置为这两个状态其中之一。然后再点击右方的run按钮。
当组名设置为delete,项目状态为STOP时,24小时爬虫项目会被删除。
我们可以点击右方的Results查看抓取数据结果,抓取的数据默认保存在pyspider启动目录下/data/result.db
rate 代表每一秒发送的请求数,默认1,代表每一秒发送一个请求,数值越大,速度越快。
burst 当所有任务被执行完成后,处理数据时又出现新的任务时,此时会默认同时执行3个,但是第四个请求需要等待1秒,也就是rate的值。
三、糗事百科推荐笑话爬取
1、创建项目
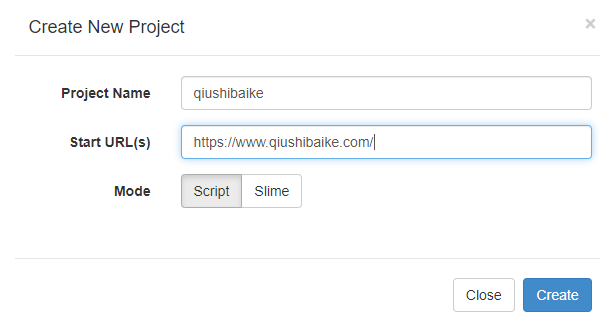
2、常用工具

3、代码
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2020-04-09 17:40:39
# Project: qiushibaike
from pyspider.libs.base_handler import *
headers={
'user_agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36',
}
class Handler(BaseHandler):
crawl_config = {
'validate_cert':False,
'headers':headers
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('https://www.qiushibaike.com/', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a.recmd-content').items():
self.crawl(each.attr.href, callback=self.detail_page)
flag=response.etree.xpath('//span[contains(text(),"下一页")]')
print(flag)
if flag:
next_url=response.doc('.pagination>li:last-child>a').attr("href")
print(next_url)
self.crawl(next_url, callback=self.index_page)
@config(priority=2)
def detail_page(self, response):
item={
"url": response.url,
"title": response.doc('h1.article-title').text(),
"content":response.etree.xpath('string(//div[@class="content"])'),
"video_source":response.doc('#article-video >source').attr("src"),
"img_urls":response.etree.xpath('//div[@class="thumb"]//img/@src')
}
return item
4、执行

5、等待一会,就可以查看到数据,可直接下载json,或者csv格式的数据。

pyspider_初始的更多相关文章
- 2DToolkit官方文档中文版打地鼠教程(一):初始设置
这是2DToolkit官方文档中 Whack a Mole 打地鼠教程的译文,为了减少文中过多重复操作的翻译,以及一些无必要的句子,这里我假设你有Unity的基础知识(例如了解如何新建Sprite等) ...
- CSharpGL(38)带初始数据创建Vertex Buffer Object的情形汇总
CSharpGL(38)带初始数据创建Vertex Buffer Object的情形汇总 开始 总的来说,OpenGL应用开发者会遇到为如下三种数据创建Vertex Buffer Object的情形: ...
- ArrayList、Vector、HashMap、HashSet的默认初始容量、加载因子、扩容增量
当底层实现涉及到扩容时,容器或重新分配一段更大的连续内存(如果是离散分配则不需要重新分配,离散分配都是插入新元素时动态分配内存),要将容器原来的数据全部复制到新的内存上,这无疑使效率大大降低. 加载因 ...
- linux系统下使用xampp 丢失mysql root密码【xampp的初始密码为空】
如果在ubuntu 下面 使用xampp这个集成开发环境,却忘记mysql密码. 注:刚安装好的xampp的Mysql初始密码是空... 找回密码的步骤如下: 1.停止mysql服务器 sudo /o ...
- python基础之初始python
初始python之基础一 一.Python 介绍 1.python的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,吉多·范罗苏姆为了在阿姆斯特丹打发时间,决心开发 ...
- openfire 初始密码
openfire 初始密码 mssql2014 进入数据库,找到 ofUser 表 ,将密码字段对应的密文替换为下面的内容,则密码就是 admin ecbd03623cd819c48718db1b27 ...
- Bash 什么时候会给 HOME 赋初始值
今天无意发现下面这个表现: $ env -i bash -c cd bash: line 0: cd: HOME not set $ env -i bash -c 'echo $HOME' 这表明了 ...
- Holt-Winters原理和初始值的确定
关于模型 (来自以下PPT,从第4页开始) 关于初始值: 以下文档给出了三个模型的初始值计算的思路. 大致思路如下,建立一个p阶移动平均模型,估计出参数即为初始值,具体的根据三种不同的模型,有 ...
- 关于int,integer初始值问题
随机推荐
- 【OO第三次课下讨论】农场主的饲料分配问题
需求分析与项目设计 本思考题的设计需求是力图找到一个简单且可行的饲料分配方案,由于不涉及到饲料价格或者是营养均衡之类的优化问题,因此在假设总的饲料量必能满足所有动物的热量需求的前提下,我们只需要采 ...
- ubunto 免输入密码 登录 putty ssh-keygen
交互式密码不安全,现在改用 ssh 证书方式,不用输入密码使用公钥证书登录. 方法1, 此方法,仅试用于,仅使用win putty 来连接方式使用,如果双方都是 linux 如 rsync 同步等时, ...
- SpringBoot2整合Shiro报错 UnavailableSecurityManagerException: No SecurityManager accessible to the calling code 【已解决】
SpringBoot集成Shiro报错 UnavailableSecurityManagerException: No SecurityManager accessible to the callin ...
- Spark入门(三)--Spark经典的单词统计
spark经典之单词统计 准备数据 既然要统计单词我们就需要一个包含一定数量的文本,我们这里选择了英文原著<GoneWithTheWind>(<飘>)的文本来做一个数据统计,看 ...
- .net webapi 接收保存图片到服务器,并居中剪裁压缩图片
原文链接:https:////www.cnblogs.com/Jackyye/p/12510943.html 每天解决一些c#小问题,在写微信小程序,或者一些手机软件接口,我们经常要用到上传图片到服务 ...
- 单选框 改成 复选框 的css样式
fillEditorFakeTable.less /* add for the global title checkbox fake */ .fake-checkbox { display: inli ...
- 数据挖掘算法——K-means算法
k-means中文称为K均值聚类算法,在1967年就被提出 所谓聚类就是将物理或者抽象对象的集合分组成为由类似的对象组成的多个簇的过程 聚类生成的组成为簇 簇内部任意两个对象之间具有较高的相似度,不 ...
- java-乘法口诀表。(新手)
//创建的一个包名. package qige; //定义一个类. public class KJ { //公共静态的一个主方法. public static void main(String[] a ...
- 12. Java 获取指定字符第N次出现的位置
import java.util.regex.Matcher; import java.util.regex.Pattern; public class Demo { //判断"Ab2Ad3 ...
- gRPC (1):入门及服务端创建和调用原理
1. RPC 入门 1.1 RPC 框架原理 RPC 框架的目标就是让远程服务调用更加简单.透明,RPC 框架负责屏蔽底层的传输方式(TCP 或者 UDP).序列化方式(XML/Json/ 二进制)和 ...