数据挖掘算法——K-means算法
k-means中文称为K均值聚类算法,在1967年就被提出 所谓聚类就是将物理或者抽象对象的集合分组成为由类似的对象组成的多个簇的过程
聚类生成的组成为簇 簇内部任意两个对象之间具有较高的相似度,不同簇的两个对象之间具有较高的相异度
相异度和相似度可以根据描述的对象的属性值来计算 对象间的距离是最常采用的相异度度量指标
常用的距离方法有

k-means是基于划分的方法 就是通过迭代将数据对象划分为k个组每个组为一个簇
每个分组至少包含一个对象
每个对象属于且仅属于某个分组
输入:簇的数目K和包含n个对象的数据集D
输出:K个簇的集合
方法:
1.从D中任意选择K个对象作为初始簇的质心;
2.计算每个对象与各簇质心的距离,并且将对象划分到距离其更近的簇
3.更新每个新簇的质心
4.重复2.3步骤,直到簇中的对象不再变化
对K-means算法的几点说明
1.簇的质心就是簇中所有对象在每一维属性的举止组合成的虚拟点 并非实际存在的数据点
2.对噪声和离群(孤立)点数据是敏感,因为它们的存在会对均值的计算产生极大的影响
3.对象到质心的距离通常使用欧式距离来计算
4.要求用户实现给出生成的数目,要求K值已直
5.算法收敛的速度和结果容易受初始质心的影响
来个例子:
数据集:
n = 8, k = 2;取1和3为初始点
|
序号 |
属性1 |
属性2 |
|
1 |
1 |
1 |
|
2 |
2 |
1 |
|
3 |
1 |
2 |
|
4 |
2 |
2 |
|
5 |
4 |
3 |
|
6 |
5 |
3 |
|
7 |
4 |
4 |
|
8 |
5 |
4 |
#include<bits/stdc++.h>
using namespace std;
struct Node
{
int id;
double a, b;
}node[];
vector<int>beginn[],endd[];
int flag = ;
double distance(pair<double,double>a, Node b){
return (b.a - a.first) * (b.a - a.first) + (b.b - a.second) * (b.b - a.second);
}
bool check(int k )
{
if(flag == )
{
flag = ;
return false;
}
for(int i = ; i < k ; i ++)
{
if(beginn[i].size() != endd[i].size())
return false;
for(int j = ; j < endd[i].size(); j++)
{
if(endd[i][j] != beginn[i][j])
return false;
}
}
return true;
}
int main()
{
int n, k;
cin >> n >> k;
for(int i = ; i <= n; i ++)
cin >> node[i].id >> node[i].a >> node[i].b;
vector<double>vec[];
vector< pair<double, double> > gg;
for(int i = ; i <= k; i ++)
{
int x;
cin >> x;
gg.push_back(make_pair(node[x].a,node[x].b));
}//只要把这些点当作是初始点就可以 与其他的点无关即可
while(true)
{
for(int i = ; i < k; i++)
{
beginn[i].assign(endd[i].begin(), endd[i].end());
endd[i].clear();
}
for(int i = ; i < k; i ++) //表示有k个堆 计算每个堆里面的值
{
vec[i].clear();
for(int j = ; j <= n ; j ++)
vec[i].push_back(distance(gg[i] , node[j]));//计算的是每个点到初始点的距离
}
for(int i = ;i < n ; i ++)
{
double minn = 0x3f3f3f3f;
int u = -;
for(int j = ; j < k; j ++){
if(vec[j][i] < minn){
minn = vec[j][i];
u = j;//表示的是哪个簇的
}
}
endd[u].push_back(i + );
}
cout<<"新计算得到的"<<endl;
for(int i = ; i < k ; i ++)
{
for(int j = ; j < endd[i].size(); j ++)
printf("%d ",endd[i][j]);
printf("\n");
}
cout<<"原本的"<<endl;
for(int i = ; i < k ; i ++)
{
for(int j = ; j < beginn[i].size(); j ++)
printf("%d ",beginn[i][j]);
printf("\n");
}
gg.clear();
for(int i = ; i < k ; i ++)
{
double sum1 = , sum2 = ;
for(int j = ; j < endd[i].size(); j ++)
{
sum1 += node[endd[i][j]].a;
sum2 += node[endd[i][j]].b;
}
sum1 = sum1 / endd[i].size();
sum2 = sum2 / endd[i].size();
gg.push_back(make_pair(sum1,sum2)); //得到的新的值
}
cout<<"新的平均值:"<<endl;
for(int i = ; i < k ;i ++)
cout<<gg[i].first <<" " << gg[i].second<<endl;
cout<<endl;
if(check(k))
return ;
}
return ;
}
结果可得
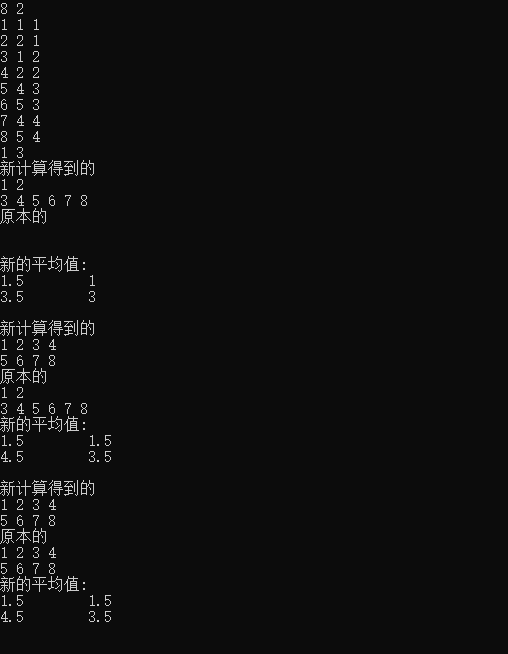
参考来自:
https://www.jianshu.com/p/4f032dccdcef
https://www.icourse163.org/course/CUG-1003556007?utm_campaign=share&utm_medium=androidShare&utm_source=
数据挖掘算法——K-means算法的更多相关文章
- 第4章 最基础的分类算法-k近邻算法
思想极度简单 应用数学知识少 效果好(缺点?) 可以解释机器学习算法使用过程中的很多细节问题 更完整的刻画机器学习应用的流程 distances = [] for x_train in X_train ...
- 聚类算法:K-means 算法(k均值算法)
k-means算法: 第一步:选$K$个初始聚类中心,$z_1(1),z_2(1),\cdots,z_k(1)$,其中括号内的序号为寻找聚类中心的迭代运算的次序号. 聚类中心的向量值可任意设 ...
- 分类算法----k近邻算法
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一.该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的 ...
- 机器学习(四) 机器学习(四) 分类算法--K近邻算法 KNN (下)
六.网格搜索与 K 邻近算法中更多的超参数 七.数据归一化 Feature Scaling 解决方案:将所有的数据映射到同一尺度 八.scikit-learn 中的 Scaler preprocess ...
- 机器学习(四) 分类算法--K近邻算法 KNN (上)
一.K近邻算法基础 KNN------- K近邻算法--------K-Nearest Neighbors 思想极度简单 应用数学知识少 (近乎为零) 效果好(缺点?) 可以解释机器学习算法使用过程中 ...
- python 机器学习(二)分类算法-k近邻算法
一.什么是K近邻算法? 定义: 如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别. 来源: KNN算法最早是由Cover和Hart提 ...
- KNN 与 K - Means 算法比较
KNN K-Means 1.分类算法 聚类算法 2.监督学习 非监督学习 3.数据类型:喂给它的数据集是带label的数据,已经是完全正确的数据 喂给它的数据集是无label的数据,是杂乱无章的,经过 ...
- 分类算法——k最近邻算法(Python实现)(文末附工程源代码)
kNN算法原理 k最近邻(k-Nearest Neighbor)算法是比较简单的机器学习算法.它采用测量不同特征值之间的距离方法进行分类,思想很简单:如果一个样本在特征空间中的k个最近邻(最相似)的样 ...
- 【学习笔记】分类算法-k近邻算法
k-近邻算法采用测量不同特征值之间的距离来进行分类. 优点:精度高.对异常值不敏感.无数据输入假定 缺点:计算复杂度高.空间复杂度高 使用数据范围:数值型和标称型 用例子来理解k-近邻算法 电影可以按 ...
- 【机器学习】聚类算法——K均值算法(k-means)
一.聚类 1.基于划分的聚类:k-means.k-medoids(每个类别找一个样本来代表).Clarans 2.基于层次的聚类:(1)自底向上的凝聚方法,比如Agnes (2)自上而下的分裂方法,比 ...
随机推荐
- JAVA WEB期末项目第二阶段成果
我们做的系统是一个基于Java web与MySQL的食堂订餐系统 班级: 计科二班 小组成员:李鉴宣.袁超 1.开发环境 开发编辑器使用:Visual Studio Code 数据库使用:MySQL8 ...
- node新人
node 使用 http和express创建服务器环境 如 apache iis等 不需要配置一堆文件 为啥使用node 省事 v8引擎 异步js 不影响浏览者浏览网站 redis ...
- C# 输出&输入&类型强制转换
输入字符串 String s; s=Console.ReadLine(); 输出字符串 Console.WritrLine(s); 输出分两种 ①占位符输出:Console.WriteLine(&qu ...
- Python实现线程交替打印字符串
import threading con = threading.Condition() word = u"12345上山打老虎" def work(): global word ...
- 使用Google App Engine开始新的网站开发学习
继长时间的迷茫后,我发现还是回归php网站开发更适合我,或者没有那么深刻,但至少要做点事情.不知道以后将从事什么样的工作,但现在找点事情做还是很好的.所以,为了激发我学习的热情,我在网上搜了一下免费云 ...
- 杂记:VMware中为mac虚拟机扩容
之前在VMware中安装Mac虚拟机时,硬盘选的是默认的40G,后来用的过程中随着软件的安装,特别是安装完Xcode和QT5.9之后,可用空间只剩不到3G,每次开机之后都会提醒空间不足,需要清理空间, ...
- ip修改成域名
将ip修改成域名,这样的话可以使程序变得更加健壮,别人不能直接看见你的ip地址. 后来总结下分享给大家.首先找到hosts文件的位置,这个文件是系统dns默认查找的文件. windows 系统:C:\ ...
- webpack中打包拷贝静态文件CopyWebpackPlugin插件
copyWebpackPlugin: 作用:用于webpack打包时拷贝文件的插件包 安装:npm install copyWebpackPlugin@版本号 使用:// copy custom st ...
- 一个简单的爬取b站up下所有视频的所有评论信息的爬虫
心血来潮搞了一个简单的爬虫,主要是想知道某个人的b站账号,但是你知道,b站在搜索一个用户时,如果这个用户没有投过稿,是搜不到的,,,这时就只能想方法搞到对方的mid,,就是 space.bilibil ...
- 54-with管理文件操作上下文
目录 with管理文件操作上下文 with管理文件操作上下文 之前我们使用open()方法操作文件,但是open打开文件后我们还需要手动释放文件对操作系统的占用.其实我们可以更方便的打开文件,即Pyt ...