认识HDFS分布式文件系统
1.设计基础目标
(1) 错误是常态,需要使用数据冗余
(2)流式数据访问。数据批量读而不是随机速写,不支持OLTP,hadoop擅长数据分析而不是事物处理。
(3)文件采用一次性写多次读的模型,文件一旦写入就无法修改。所以一致性模型非常简单。
(4)程序采用 数据就近 原则分配节点执行。(MapReduce)
2.hdf体系结构
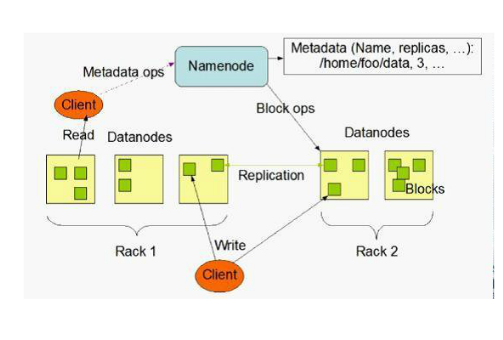
hadfs设计十分简单,在我的1个master和两个slave节点的集群中,通过jps,可以查看在master节点上运行着SecondaryNameNode ,NameNode,JobTracker
在slave结点上运行着DataNode和TaskTracker进程
1.NameNode:管理文件系统的命名空间,记录每个文件数据快在各个DataNode上的位置和副本信息,记录命名空间内的改动或空间本身属性的改动;协调客户端对文件的访问;
NameNode使 用事物日志记录HDFS元数据的变化,使用映像文件存储文件系统的命名空间,
2.DataNode:管理存储节点,一次写入,多次读取,不支持修改。文件由数据块组成,包括文件映射,文件属性。默认的数据块大小为64MB,数据块尽量散布在各个节点中,负载均衡。
3.读取数据流程:客户端要访问HDFS中的文件,首先从NameNode获取组成这个文件的数据块位置列表,根据数据块位置列表,知道存储数据块的DataNode,访问DataNode获取数据,NameNode并不参与数据实际传输。
3.HDFS分布式文件系统的可靠性
- 副本冗余:在hdfs-site.xml中可以设置副本的数量,DataNode启动时,首先会遍历本地的文件系统,产生一份hdfs数据块和本地文件的对应关系列表(blockreport)汇报给namenode。
- 机架策略:通过“机架感知”,将数据块副本存储在不同的机架中。
- 心跳机制:NameNode周期性的从datanode接受心跳信号和块报告。根据块报告验证元数据,副本数量、磁盘错误、节点宕机。
- 安全模式:NameNode启动时会经过“安全模式”阶段,安全模式不会产生数据写。可以通过命令强制集群进入安全模式。
- 校验和:文件创立的时候,每个文件都会产生校验和,校验和会作为一个隐藏文件保存在命名空间下,客户端获取数据时可以检查校验和是否相同,从而法相数据块是否损坏。
- 回收站:HDFS提供回收站功能。
- 元数据保护:映像文件和事物日志是Namenode的核心数据。可以配置为拥有多个副本,副本会降低Name的处理速度,但是增加安全性。
- 快照
4.HDFS文件操作(命令行操作和API调用的方式)
列出文件:hadoop dfs -ls 后可接上目录
文件上传:hadoop dfs -put 本地文件 hdfs目录
文件复制到本地:hadoop dfs -get
文件删除:hadoop dfs -rmr 目录或文件名
文件查看:hadoop dfs -cat 文件名
查看HDFS的基本统计信息:hadoop dfsasmin -report
进入/退出安全模式:hadoop dfsadmin -safemode enter/leave
5.增加节点
- 在新节点安装好hadoop
- 把namenode的有关配置文件复制到该节点
- 修改masters和slaves文件,增加该节点
- 设施ssh免密码进入该结点
- 单独启动该节点上的datanode和tasktracker(hadoop-daemon.sh start datanode/tasktracker)
- 运行start-balancer.sh进行负载均衡。
认识HDFS分布式文件系统的更多相关文章
- HDFS分布式文件系统资源管理器开发总结
HDFS,全称Hadoop分布式文件系统,作为Hadoop生态技术圈底层的关键技术之一,被设计成适合运行在通用硬件上的分布式文件系统.它和现有的分布式文件系统有很多共同点,但同时,它和其他的分布式 ...
- 通过Thrift访问HDFS分布式文件系统的性能瓶颈分析
通过Thrift访问HDFS分布式文件系统的性能瓶颈分析 引言 Hadoop提供的HDFS布式文件存储系统,提供了基于thrift的客户端访问支持,但是因为Thrift自身的访问特点,在高并发的访问情 ...
- Hadoop HDFS分布式文件系统 常用命令汇总
引言:我们维护hadoop系统的时候,必不可少需要对HDFS分布式文件系统做操作,例如拷贝一个文件/目录,查看HDFS文件系统目录下的内容,删除HDFS文件系统中的内容(文件/目录),还有HDFS管理 ...
- Hadoop基础-HDFS分布式文件系统的存储
Hadoop基础-HDFS分布式文件系统的存储 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HDFS数据块 1>.磁盘中的数据块 每个磁盘都有默认的数据块大小,这个磁盘 ...
- 1、HDFS分布式文件系统
1.HDFS分布式文件系统 分布式存储 分布式计算 2.hadoop hadoop含有四个模块,分别是 common. hdfs和yarn. common 公共模块. HDFS hadoop dist ...
- 我理解中的Hadoop HDFS分布式文件系统
一,什么是分布式文件系统,分布式文件系统能干什么 在学习一个文件系统时,首先我先想到的是,学习它能为我们提供什么样的服务,它的价值在哪里,为什么要去学它.以这样的方式去理解它之后在日后的深入学习中才能 ...
- 大数据基础总结---HDFS分布式文件系统
HDFS分布式文件系统 文件系统的基本概述 文件系统定义:文件系统是一种存储和组织计算机数据的方法,它使得对其访问和查找变得容易. 文件名:在文件系统中,文件名是用于定位存储位置. 元数据(Metad ...
- hdfs(分布式文件系统)优缺点
hdfs(分布式文件系统) 优点 支持超大文件 支持超大文件.超大文件在这里指的是几百M,几百GB,甚至几TB大小的文件.一般来说hadoop的文件系统会存储TB级别或者PB级别的数据.所以在企业的应 ...
- 【史上最全】Hadoop 核心 - HDFS 分布式文件系统详解(上万字建议收藏)
1. HDFS概述 Hadoop 分布式系统框架中,首要的基础功能就是文件系统,在 Hadoop 中使用 FileSystem 这个抽象类来表示我们的文件系统,这个抽象类下面有很多子实现类,究竟使用哪 ...
随机推荐
- xaml mvvm(2)之属性绑定
通过微软INotifyPropertyChanged接口,可以实现对UI实时更新,不管是数据源或者目标对象,可以实现相互通知. 下面我们根据INotifyPropertyChanged编写一个扩展类. ...
- div自适应宽度
对于div自适应宽度,网上的说法基本上都是将要自适应宽度的div放在其它固定宽度的最后,不指定其float属性或将float属性指定为none,比如三栏布局居中的一栏为自适应宽度,就可以这样来定义三栏 ...
- Solr特性:Schemaless Mode(自动往Schema中添加field)
WiKi:https://cwiki.apache.org/confluence/display/solr/Schemaless+Mode 介绍: Schemaless Mode is a set o ...
- SSH小项目整合的简单记录
第一步.导入sprint4.struts2和hibernate4的jar包 struts2的jar包 commons-fileupload-1.3.3.jar commons-io-2.5.jar c ...
- 简述System.Windows.Forms.Timer 与System.Timers.Timer用法区别
System.Windows.Forms.Timer 基于窗体应用程序 阻塞同步 单线程 timer中处理时间较长则导致定时误差极大. System.Timers.Timer 基于服务 非阻塞异步 多 ...
- 【VS2015】故障修复之dep6100,dep6200
问题描述:把uwp程序往手机上(或者往模拟器上)部署时,vs ide提示我错误信息dep6100和dep6200,报告说“连接不到设备”. 这可把我愁坏了,各种方法都不行,最后发现问题出在Hyper- ...
- 微信浏览器禁止app下载链接的两种处理方法
最近替朋友放一个微信下载链接,通过二维码扫描下载. 通过扫描二维码下载APP已成为一个非常方便的方式,微信也成为扫描二维码重要的工具,但是扫描后微信浏览器会对APK和appStore的链接进行屏蔽,导 ...
- TortoiseGit revert failed - unable to revert local changes
TortoiseGit revert failed - unable to revert local changes 下载完按照提示一步一步安装就可以了 成功之后就是windows.1版本,如图
- [JS] 气球放气效果
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <meta name ...
- 由button标签在 IE 8.0 下的异常表现引发的一场血案
写在最前的最后:整篇文章絮絮叨叨说了半天,我得出一个最佳实践:和button标签say goodbay,用 a 标签模拟之. 首先看一个在chrome 下的简单demo 这样的布局在组件开发中再常见不 ...