[转]Python爬虫html解析工具beautifulSoup在pycharm中安装及失败的解决办法
原文地址:https://www.cnblogs.com/yysbolg/p/9040649.html
刚开始学习一门技术最麻烦的问题就是搞定IDE环境,直接在PyCharm里安装BeautifulSoup报错,让初学者一头雾水;
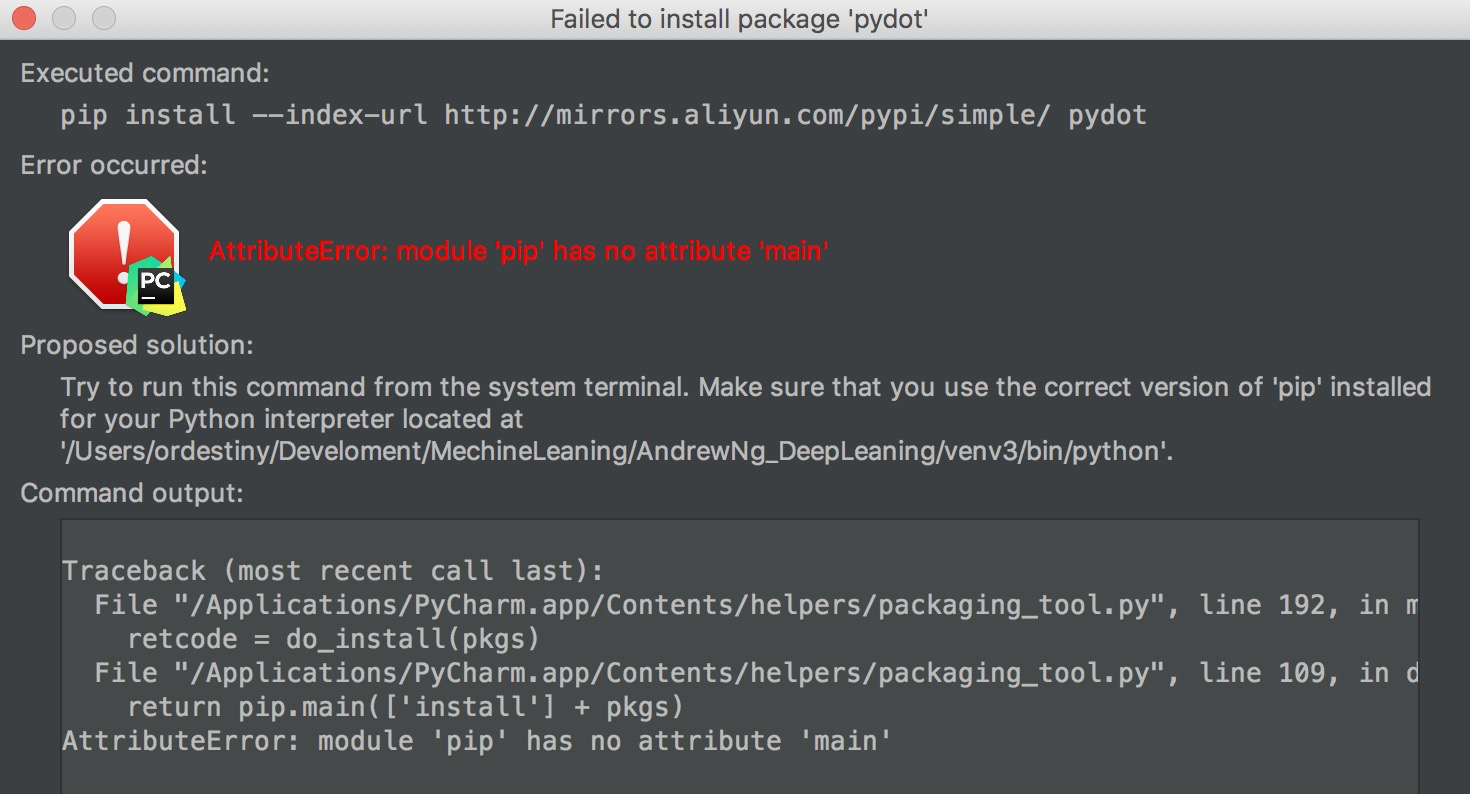
这是由于pip版本的问题,pip 10.0版本的没有main()方法, 因此更改如下代码即可:
可以考虑降个版本:python -m pip install --upgrade pip==9.0.3
解决方法:
找到C:\Program Files\JetBrains\PyCharm 2017.3.2安装目录下的 helpers/packaging_tool.py文件,找到如下代码:
def do_install(pkgs):
try:
import pip
except ImportError:
error_no_pip()
return main(['install'] + pkgs)
def do_uninstall(pkgs):
try:
import pip
except ImportError:
error_no_pip()
return main(['uninstall', '-y'] + pkgs)
修改为如下,保存即可

def do_install(pkgs):
try:
# import pip
try:
from pip._internal import main
except Exception:
from pip import main
except ImportError:
error_no_pip()
return main(['install'] + pkgs) def do_uninstall(pkgs):
try:
# import pip
try:
from pip._internal import main
except Exception:
from pip import main
except ImportError:
error_no_pip()
return main(['uninstall', '-y'] + pkgs)
再次运行,就可以安装这些扩展包啦,Yeah!!!
[转]Python爬虫html解析工具beautifulSoup在pycharm中安装及失败的解决办法的更多相关文章
- Python爬虫html解析工具beautifulSoup在pycharm中安装及失败的解决办法
1.安装步骤: 首先,你要先进入pycharm的Project Interpreter界面,进入方法是:setting(ctrl+alt+s) ->Project Interpreter,Pro ...
- python爬虫数据解析之BeautifulSoup
BeautifulSoup是一个可以从HTML或者XML文件中提取数据的python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式. BeautfulSoup是python爬虫三 ...
- 【XPath Helper:chrome爬虫网页解析工具 Chrome插件】XPath Helper:chrome爬虫网页解析工具 Chrome插件下载_教程_安装 - 开发者插件 - Chrome插件网
[XPath Helper:chrome爬虫网页解析工具 Chrome插件]XPath Helper:chrome爬虫网页解析工具 Chrome插件下载_教程_安装 - 开发者插件 - Chrome插 ...
- python爬虫网页解析之lxml模块
08.06自我总结 python爬虫网页解析之lxml模块 一.模块的安装 windows系统下的安装: 方法一:pip3 install lxml 方法二:下载对应系统版本的wheel文件:http ...
- python爬虫网页解析之parsel模块
08.06自我总结 python爬虫网页解析之parsel模块 一.parsel模块安装 官网链接https://pypi.org/project/parsel/1.0.2/ pip install ...
- 【Python】在Pycharm中安装爬虫库requests , BeautifulSoup , lxml 的解决方法
BeautifulSoup在学习Python过程中可能需要用到一些爬虫库 例如:requests BeautifulSoup和lxml库 前面的两个库,用Pychram都可以通过 File--> ...
- web报表工具FineReport使用中遇到的常见报错及解决办法(二)
web报表工具FineReport使用中遇到的常见报错及解决办法(二) 这里写点抛砖引玉,希望大家能把自己整理的问题及解决方法晾出来,Mark一下,利人利己. 出现问题先搜一下文档上有没有,再看看度娘 ...
- Ubuntu“无法解析或打开软件包的列表或是状态文件”的解决办法。_StarSasumi_新浪博客
Ubuntu"无法解析或打开软件包的列表或是状态文件"的解决办法. (2011-04-30 14:56:14) 转载▼ 标签: ubuntu apt 分类: Ubuntu/Linu ...
- Python爬虫学习三------requests+BeautifulSoup爬取简单网页
第一次第一次用MarkDown来写博客,先试试效果吧! 昨天2018俄罗斯世界杯拉开了大幕,作为一个伪球迷,当然也得为世界杯做出一点贡献啦. 于是今天就编写了一个爬虫程序将腾讯新闻下世界杯专题的相关新 ...
随机推荐
- redis在windows上安装+RedisDesktopManager
redis我就不在这里介绍了,这里直接介绍windows安装redis服务,网上有很多介绍windows版,我这边安装的是一个极简版的. redis官方下载地址:https://redis.io/do ...
- 计算Pan手势到指定点的角度
计算Pan手势到指定点的角度 效果图: 源码: // // RootViewController.m // Circle // // Copyright (c) 2014年 Y.X. All righ ...
- bmp制作自定义字体(cocostudio使用)
工具需求:bmpfont 1.步骤 (1)制作 * 把自己的字体放到一个txt文件中,写个脚本抽离出来, 重复了没有关系 * Edit->Select chars from fils(注意:Ed ...
- HAProxy负载均衡保持客户端和服务器Session亲缘性的3种方式
1 用户IP 识别 haroxy 将用户IP经过hash计算后 指定到固定的真实服务器上(类似于nginx 的IP hash 指令) 配置指令: balance source 配置实例: backe ...
- 小J学python--Exception-异常
现在我们要打开一个名为fuck的文件,fuck是不存在的,看看异常是怎么工作的 不捕获异常的情况 #打开文件 open('fuck') 执行结果 捕获所有异常 Exception是所有异常类的父类,所 ...
- Chapter 1 Secondary Sorting:Introduction
开始学习<数据算法:Hadoop/Spark大数据处理技巧>第1-5章,假期有空就摘抄下来,毕竟不是纸质的可以写写画画,感觉这样效果好点,当然复杂的东西仍然跳过.写博客越发成了做笔记的感觉 ...
- Linux和Unix的区别
Linux Unix 免费 收费 开源 不开源 硬件无要求 有要求 IBM Sun Hp 主流的Linux的发型版本: RedHat Fedora Mand ...
- Angular2 Pipe
AngularJs 1.x 中使用filters来帮助我们转换templates中的输出,但在Angular2中使用的是pipes,以下展示Angular 1.x and Angular 2中filt ...
- Kali-linux控制Meterpreter
Meterpreter是Metasploit框架中的一个杀手锏,通常作为利用漏洞后的攻击载荷所使用,攻击载荷在触发漏洞后能够返回给用户一个控制通道.当使用Armitage.MSFCLI或MSFCONS ...
- 20165302 实验一 java开发环境的熟悉
20165302实验一 java开发环境的熟悉 一,实验内容与步骤 1.命令行下java程序开发 ①待编译运行代码 package csj; import java.util.Scanner; pub ...