第3节 mapreduce高级:12、mapreduce相关的参数调整
5.1 多job串联
一个稍复杂点的处理逻辑往往需要多个mapreduce程序串联处理,多job的串联可以借助mapreduce框架的JobControl实现
示例代码:
|
ControlledJob cJob1 = new ControlledJob(job1.getConfiguration()); ControlledJob cJob2 = new ControlledJob(job2.getConfiguration()); ControlledJob cJob3 = new ControlledJob(job3.getConfiguration()); cJob1.setJob(job1); cJob2.setJob(job2); cJob3.setJob(job3); // 设置作业依赖关系 cJob2.addDependingJob(cJob1); cJob3.addDependingJob(cJob2); JobControl jobControl = new JobControl("RecommendationJob"); jobControl.addJob(cJob1); jobControl.addJob(cJob2); jobControl.addJob(cJob3); // 新建一个线程来运行已加入JobControl中的作业,开始进程并等待结束 Thread jobControlThread = new Thread(jobControl); jobControlThread.start(); while (!jobControl.allFinished()) { Thread.sleep(500); } jobControl.stop(); return 0; |
5.3 Configuration对象高级应用
mapreduce参数优化
MapReduce重要配置参数
11.1 资源相关参数
以下调整参数都在mapred-site.xml这个配置文件当中有
//以下参数是在用户自己的mr应用程序中配置就可以生效
(1) mapreduce.map.memory.mb: 一个Map Task可使用的资源上限(单位:MB),默认为1024。如果Map Task实际使用的资源量超过该值,则会被强制杀死。
(2) mapreduce.reduce.memory.mb: 一个Reduce Task可使用的资源上限(单位:MB),默认为1024。如果Reduce Task实际使用的资源量超过该值,则会被强制杀死。
(3) mapred.child.java.opts 配置每个map或者reduce使用的内存的大小,默认是200M
(4) mapreduce.map.cpu.vcores: 每个Map task可使用的最多cpu core数目, 默认值: 1
(5) mapreduce.reduce.cpu.vcores: 每个Reduce task可使用的最多cpu core数目, 默认值: 1
//shuffle性能优化的关键参数,应在yarn启动之前就配置好
(6)mapreduce.task.io.sort.mb 100 //shuffle的环形缓冲区大小,默认100m
(7)mapreduce.map.sort.spill.percent 0.8 //环形缓冲区溢出的阈值,默认80%
//应该在yarn启动之前就配置在服务器的配置文件中才能生效
以下配置都在yarn-site.xml配置文件当中配置
(8) yarn.scheduler.minimum-allocation-mb 1024 给应用程序container分配的最小内存
(9) yarn.scheduler.maximum-allocation-mb 8192 给应用程序container分配的最大内存
以下图片是对container的说明:
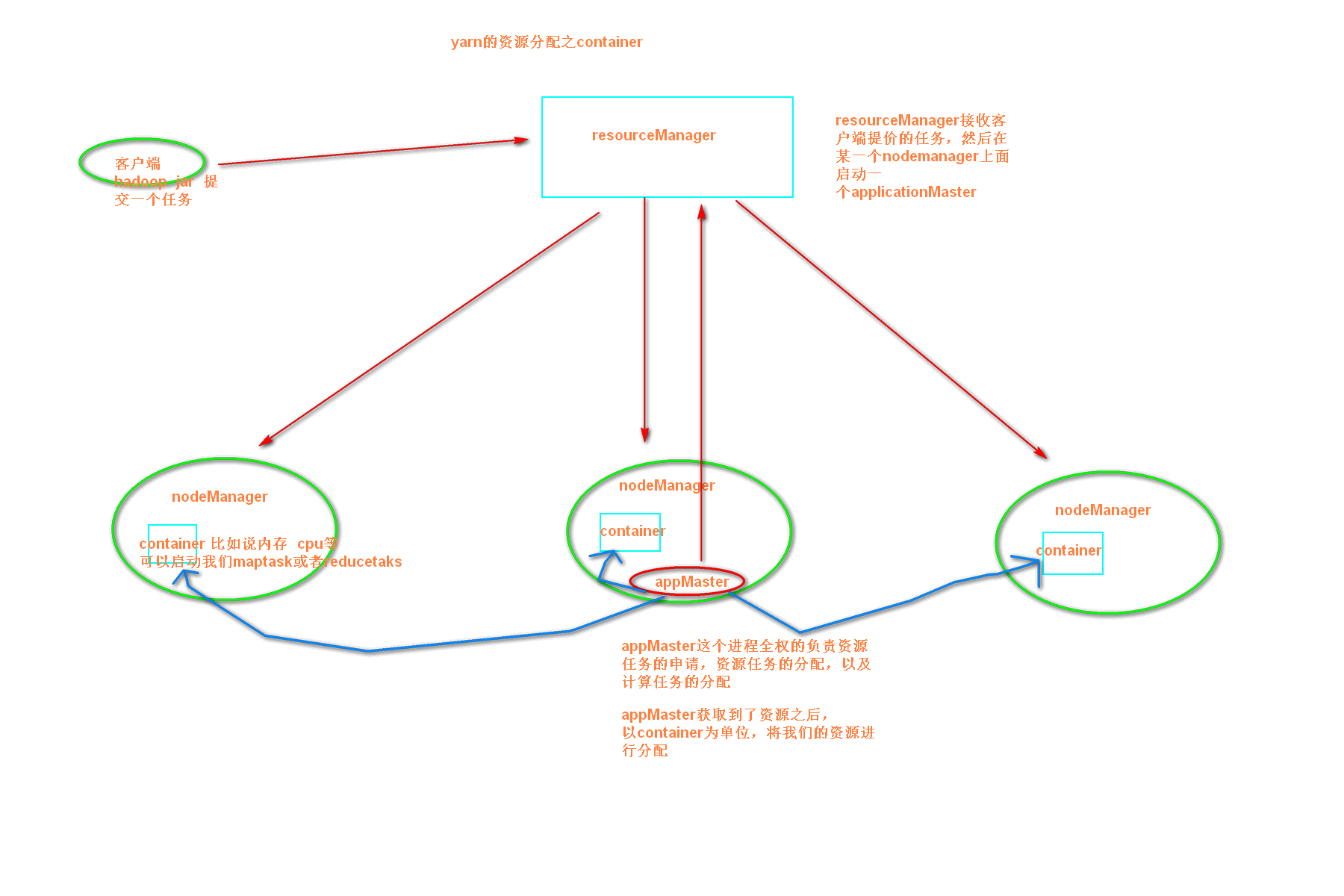
(10) yarn.scheduler.minimum-allocation-vcores 1
(11)yarn.scheduler.maximum-allocation-vcores 32
(12)yarn.nodemanager.resource.memory-mb 8192
11.2 容错相关参数
(1) mapreduce.map.maxattempts: 每个Map Task最大重试次数,一旦重试参数超过该值,则认为Map Task运行失败,默认值:4。
(2) mapreduce.reduce.maxattempts: 每个Reduce Task最大重试次数,一旦重试参数超过该值,则认为Map Task运行失败,默认值:4。
(3) mapreduce.job.maxtaskfailures.per.tracker: 当失败的Map Task失败比例超过该值为,整个作业则失败,默认值为0. 如果你的应用程序允许丢弃部分输入数据,则该该值设为一个大于0的值,比如5,表示如果有低于5%的Map Task失败(如果一个Map Task重试次数超过mapreduce.map.maxattempts,则认为这个Map Task失败,其对应的输入数据将不会产生任何结果),整个作业仍认为成功。
(5) mapreduce.task.timeout: Task超时时间,默认值为600000毫秒,经常需要设置的一个参数,该参数表达的意思为:如果一个task在一定时间内没有任何进入,即不会读取新的数据,也没有输出数据,则认为该task处于block状态,可能是卡住了,也许永远会卡主,为了防止因为用户程序永远block住不退出,则强制设置了一个该超时时间(单位毫秒)。如果你的程序对每条输入数据的处理时间过长(比如会访问数据库,通过网络拉取数据等),建议将该参数调大,该参数过小常出现的错误提示是“AttemptID:attempt_14267829456721_123456_m_000224_0 Timed out after 300 secsContainer killed by the ApplicationMaster.”。
11.3 本地运行mapreduce 作业
设置以下几个参数:
mapreduce.framework.name=local
mapreduce.jobtracker.address=local
fs.defaultFS=local
11.4 效率和稳定性相关参数
(1) mapreduce.map.speculative: 是否为Map Task打开推测执行机制,默认为true,如果为true,如果Map执行时间比较长,那么集群就会推测这个Map已经卡住了,会重新启动同样的Map进行并行的执行,哪个先执行完了,就采取哪个的结果来作为最终结果,一般直接关闭推测执行
(2) mapreduce.reduce.speculative: 是否为Reduce Task打开推测执行机制,默认为true,如果reduce执行时间比较长,那么集群就会推测这个reduce已经卡住了,会重新启动同样的reduce进行并行的执行,哪个先执行完了,就采取哪个的结果来作为最终结果,一般直接关闭推测执行
(3) mapreduce.input.fileinputformat.split.minsize: FileInputFormat做切片时的最小切片大小,默认为0
(4)mapreduce.input.fileinputformat.split.maxsize: FileInputFormat做切片时的最大切片大小(已过时的配置,2.7.5当中直接把这个配置写死了,写成了Integer.maxValue的值)
(切片的默认大小就等于blocksize,即 134217728)
==================================================================================
mapreduce的参数优化:
使用的是虚拟内核的概念,实体机的一个cpu核数,可能虚拟出来好多个虚拟内核
mapreduce.map.cpu.vcores: 每个Map task可使用的最多cpu core数目, 默认值: 1
mapreduce.reduce.cpu.vcores: 每个Reduce task可使用的最多cpu core数目, 默认值: 1
环形缓冲区的大小 其实就是搞了一个100M内存的数组
mapreduce.task.io.sort.mb 100 //shuffle的环形缓冲区大小,默认100m
mapreduce.map.sort.spill.percent 0.8 //环形缓冲区溢出的阈值,默认80%
yarn的资源调度配置参数
(8) yarn.scheduler.minimum-allocation-mb 1024 每个container最小的内存
(9) yarn.scheduler.maximum-allocation-mb 8192 每个container最大的内幕才能
(10) yarn.scheduler.minimum-allocation-vcores 1 每个container给定的最小的虚拟内核数
(11)yarn.scheduler.maximum-allocation-vcores 32 每个container给定的最大的虚拟内核数
yarn.nodemanager.resource.memory-mb 8192 每个nodemanager分配的最大内存是多少
容错相关的参数
) mapreduce.job.maxtaskfailures.per.tracker: 当失败的Map Task失败比例超过该值为,整个作业则失败,默认值为0.
如果你的应用程序允许丢弃部分输入数据,则该该值设为一个大于0的值,比如5,
表示如果有低于5%的Map Task失败(如果一个Map Task重试次数超过mapreduce.map.maxattempts,
则认为这个Map Task失败,其对应的输入数据将不会产生任何结果),整个作业仍认为成功。
默认值是0,表示maptask不允许任何的数据处理失败
效率和稳定性相关的参数:
mapreduce.map.speculative: map端的推测执行 如果一个maptask很长时间没有运行完成,集群可能会认为这个maptask由于某些原因卡住了
集群会启动同样的一个maptaks去执行相同的任务,哪个maptask先执行完成就以哪个maptask的结果为准,杀死另外一个没有执行完的maptask
推测执行会造成集群的资源更加紧张。一般都直接关闭推测执行
mapreduce.reduce.speculative: reduce端的推测执行 一般直接关闭reduce端的推测执行
切片的最大值和最小值的调整:可以调整我们的切片文件的大小,默认的切片文件128M
第3节 mapreduce高级:12、mapreduce相关的参数调整的更多相关文章
- MapReduce教程(二)MapReduce框架Partitioner分区<转>
1 Partitioner分区 1.1 Partitioner分区描述 在进行MapReduce计算时,有时候需要把最终的输出数据分到不同的文件中,按照手机号码段划分的话,需要把同一手机号码段的数据放 ...
- ASP.NET MVC深入浅出(被替换) 第一节: 结合EF的本地缓存属性来介绍【EF增删改操作】的几种形式 第三节: EF调用普通SQL语句的两类封装(ExecuteSqlCommand和SqlQuery ) 第四节: EF调用存储过程的通用写法和DBFirst模式子类调用的特有写法 第六节: EF高级属性(二) 之延迟加载、立即加载、显示加载(含导航属性) 第十节: EF的三种追踪
ASP.NET MVC深入浅出(被替换) 一. 谈情怀-ASP.NET体系 从事.Net开发以来,最先接触的Web开发框架是Asp.Net WebForm,该框架高度封装,为了隐藏Http的无状态 ...
- 第3节 hive高级用法:16、17、18
第3节 hive高级用法:16.hive当中常用的几种数据存储格式对比:17.存储方式与压缩格式相结合:18.总结 hive当中的数据存储格式: 行式存储:textFile sequenceFile ...
- java大数据最全课程学习笔记(6)--MapReduce精通(二)--MapReduce框架原理
目前CSDN,博客园,简书同步发表中,更多精彩欢迎访问我的gitee pages 目录 MapReduce精通(二) MapReduce框架原理 MapReduce工作流程 InputFormat数据 ...
- HDFS设计思路,HDFS使用,查看集群状态,HDFS,HDFS上传文件,HDFS下载文件,yarn web管理界面信息查看,运行一个mapreduce程序,mapreduce的demo
26 集群使用初步 HDFS的设计思路 l 设计思想 分而治之:将大文件.大批量文件,分布式存放在大量服务器上,以便于采取分而治之的方式对海量数据进行运算分析: l 在大数据系统中作用: 为各类分布式 ...
- Linux 内核参数 和 Oracle相关参数调整
Linux 内核参数 和 Oracle相关参数调整 分类: Oracle Basic Knowledge2009-10-14 12:23 9648人阅读 评论(0) 收藏 举报 oraclelinux ...
- 认识loadrunner及相关性能参数
认识loadrunner及相关性能参数 LoadRunner,是一种预测系统行为和性能的负载测试工具.通过以模拟上千万用户实施并发负载及实时性能监测的方式来确认和查找问题,LoadRunner能够对整 ...
- MySQL索引统计信息更新相关的参数
MySQL统计信息相关的参数: 1. innodb_stats_on_metadata(是否自动更新统计信息),MySQL 5.7中默认为关闭状态 仅在统计信息配置为非持久化的时候生效. 也就是说在i ...
- Linux vm运行参数 - OOM相关的参数
一.前言 本文是描述Linux virtual memory运行参数的第二篇,主要是讲OOM相关的参数的.为了理解OOM参数,第二章简单的描述什么是OOM.如果这个名词对你毫无压力,你可以直接进入第三 ...
随机推荐
- BZOJ4814,几何
对每个关键点i,将每个三角形缩成一个线段(因为三角形不相交),然后把线段两端点 和其他关键点一起 以i为中心点 极角排序. 扫一圈.扫到一个关键点j时, 判断当前最靠近i的线段是否遮盖i到j的路径, ...
- python 闭包 Closure 函数作为返回值
一.函数作为返回值 高阶函数除了可以接受函数作为参数外,还可以把函数作为结果值返回. >>> def lazy_sum(*args): ... def sum(): ... ax = ...
- Ocelot(八)- Ocelot不支持的几个方面
不支持 Ocelot不支持的几个方面 Chunked Encoding - Ocelot将始终获取正文大小并返回Content-Length标头.很抱歉,如果这对您的用例不起作用! 转发主机标头 - ...
- JavaScript 数组相关基础方法
文章来源于:https://www.cnblogs.com/dolphinX/p/3353590.html 创建数组 构造函数 1.无参构造函数,创建一空数组 var a1=new Array(); ...
- DevStack部署OpenStack开发环境 - 问题总结
建议在使用DevStack搭建OpenStack开发环境前,先安装好开发工具包组.特别是gcc,主要一定是在yum update -y 之前,否则更新完系统后,在安装开发工具包会出现很多依赖包因为版本 ...
- SQL标量函数-日期函数
select day(createtime) from life_unite_product --取时间字段的天值 select month(createtime) from life_uni ...
- [CERC2017]Buffalo Barricades
这个题目,扫描线+玄学** 大概操作就是用个扫描线从上往下扫. 博主有点懒,就直接贴代码了,但是我还是给大家贴个比较详细的博客,除了代码都可以看wym的博客,我基本上就是按wym大佬的思路来的,当然, ...
- 贪心 Codeforces Round #273 (Div. 2) C. Table Decorations
题目传送门 /* 贪心:排序后,当a[3] > 2 * (a[1] + a[2]), 可以最多的2个,其他的都是1个,ggr,ggb, ggr... ans = a[1] + a[2]; 或先2 ...
- 454 4Sum II 四数相加 II
给定四个包含整数的数组列表 A , B , C , D ,计算有多少个元组 (i, j, k, l) ,使得 A[i] + B[j] + C[k] + D[l] = 0.为了使问题简单化,所有的 A, ...
- 程序猿工具——svn
一个项目的产生,都需要团队中的开发人员互相协作.它的简单,方便深深吸引了我. svn的使用,有2部分组成--svn服务器.svn客户端.svn服务器一般团队之间只要有一个安装就可以了. 在学习安装sv ...