【机器学习算法-python实现】协同过滤(cf)的三种方法实现
(转载请注明出处:http://blog.csdn.net/buptgshengod)
1.背景
icf指的是item collaborative filtering,是将商品进行分析推荐。同理ucf的u指的是user,他是找出知趣类似的人,进行推荐。
通常来讲icf的准确率可能会高一些。通过这次參加天猫大数据比赛。我认为仅仅有在数据量很庞大的时候才适合用cf,假设数据量很小。cf的准确率会很可怜。
博主在比赛s1阶段,大概仅仅有几万条数据的时候,尝试了icf,准确率不到百分之中的一个。
。。
。。
2.经常用法

(1)欧氏距离法
数值越小。表示类似的越高。
def OsDistance(vector1, vector2):
sqDiffVector = vector1-vector2
sqDiffVector=sqDiffVector**2
sqDistances = sqDiffVector.sum()
distance = sqDistances**0.5
return distance
(2)皮尔逊相关系数
两个变量之间的相关系数越高。从一个变量去预測还有一个变量的准确度就越高,这是由于相关系数越高,就意味着这两个变量的共变部分越多,所以从当中一个变量的变化就可越多地获知还有一个变量的变化。
假设两个变量之间的相关系数为1或-1,那么你全然可由变量X去获知变量Y的值。
· 当相关系数为0时。X和Y两变量无关系。
· 当X的值增大。Y也增大。正相关关系,相关系数在0.00与1.00之间
· 当X的值减小,Y也减小,正相关关系。相关系数在0.00与1.00之间
· 当X的值增大。Y减小,负相关关系。相关系数在-1.00与0.00之间
当X的值减小。Y增大,负相关关系,相关系数在-1.00与0.00之间
相关系数的绝对值越大。相关性越强,相关系数越接近于1和-1,相关度越强,相关系数越接近于0,相关度越弱。

在python中用函数corrcoef实现。详细方法见http://infosec.pku.edu.cn/~dulz/doc/Numpy_Example_List.htm
(3)余弦类似度
0度角的余弦值是1,而其它不论什么角度的
在比較过程中。向量的规模大小不予考虑,仅仅考虑到向量的指向方向。余弦相
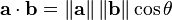
def cosSim(inA,inB):
num = float(inA.T*inB)
denom = la.norm(inA)*la.norm(inB)
return 0.5+0.5*(num/denom)
【机器学习算法-python实现】协同过滤(cf)的三种方法实现的更多相关文章
- python每次处理一个字符的三种方法
python每次处理一个字符的三种方法 a_string = "abccdea" print 'the first' for c in a_string: print ord(c) ...
- Python 文件行数读取的三种方法
Python三种文件行数读取的方法: #文件比较小 count = len(open(r"d:\lines_test.txt",'rU').readlines()) print c ...
- Python 判断文件是否存在的三种方法
通常在读写文件之前,需要判断文件或目录是否存在,不然某些处理方法可能会使程序出错.所以最好在做任何操作之前,先判断文件是否存在. 这里将介绍三种判断文件或文件夹是否存在的方法,分别使用os模块.Try ...
- python webdriver api-上传文件的三种方法
上传文件: 第一种方式,sendkeys(),最简单的 #encoding=utf-8 from selenium import webdriver import unittest import ti ...
- Python 中删除列表元素的三种方法
列表基本上是 Python 中最常用的数据结构之一了,并且删除操作也是经常使用的. 那到底有哪些方法可以删除列表中的元素呢?这篇文章就来总结一下. 一共有三种方法,分别是 remove,pop 和 d ...
- python列表删除重复元素的三种方法
给定一个列表,要求删除列表中重复元素. listA = ['python','语','言','是','一','门','动','态','语','言'] 方法1,对列表调用排序,从末尾依次比较相邻两个元素 ...
- 用Python获取Linux资源信息的三种方法
方法一:psutil模块 #!usr/bin/env python # -*- coding: utf-8 -*- import socket import psutil class NodeReso ...
- Python判断文件是否存在的三种方法
通常在读写文件之前,需要判断文件或目录是否存在,不然某些处理方法可能会使程序出错.所以最好在做任何操作之前,先判断文件是否存在. 这里将介绍三种判断文件或文件夹是否存在的方法,分别使用os模块.Try ...
- Python判断文件是否存在的三种方法【转】
转:http://www.cnblogs.com/jhao/p/7243043.html 通常在读写文件之前,需要判断文件或目录是否存在,不然某些处理方法可能会使程序出错.所以最好在做任何操作之前,先 ...
- python删除list中元素的三种方法
a.pop(index):删除列表a中index处的值,并且返回这个值. del(a[index]):删除列表a中index处的值,无返回值. del中的index可以是切片,所以可以实现批量删除. ...
随机推荐
- 【php】 检测 ie ie11 edge浏览器
来源 php.net 官网评论截取 -- Declan kelly Please note that Internet Explorer 11 no longer contains MSIE in i ...
- Java并发编程的艺术 记录(一)
模拟死锁 package com.gjjun.concurrent; /** * 模拟死锁,来源于<Java并发编程的艺术> * @Author gjjun * @Create 2018/ ...
- PAT Basic 1052
1052 卖个萌 萌萌哒表情符号通常由“手”.“眼”.“口”三个主要部分组成.简单起见,我们假设一个表情符号是按下列格式输出的: [左手]([左眼][口][右眼])[右手] 现给出可选用的符号集合,请 ...
- Android自动化测试Uiautomator--UiObject接口简介
UiObject可以理解为控件的对象,主要对对象进行操作.按照一定条件(UiSelector)获取UiObject对象,之后对对象进行相应的操作,如下图所示. 对于对象的操作主要有点击/长按.拖动/滑 ...
- php expat+DOM+SimpleXML XML读取
XML 文件 将在我们的例子中使用下面的 XML 文件: <?xml version="1.0" encoding="ISO-8859-1"?> & ...
- 00036_private
1.私有private 描述人.Person: 属性:年龄: 行为:说话:说出自己的年龄. class Person { int age; String name; public void show( ...
- Linux 文件/文件夹重命名
mv命令既可以重命名,又可以移动文件或文件夹. 例子:将目录A重命名为Bmv A B 例子:将/a目录移动到/b下,并重命名为cmv /a /b/c 其实在文本模式中要重命名文件或目录,只需要使用mv ...
- xtu数据结构 C. Ultra-QuickSort
C. Ultra-QuickSort Time Limit: 7000ms Memory Limit: 65536KB 64-bit integer IO format: %lld Java ...
- SQLSERVER 差异备份、全备份
--exec BackUPDatabase_LeeHG语句参数说明: -- 示例:exec BackUPDatabase_LeeHG '参数一','参数二','参数三','参数四','参数五',' 参 ...
- Codeforces Round #361 (Div. 2)——B. Mike and Shortcuts(BFS+小坑)
B. Mike and Shortcuts time limit per test 3 seconds memory limit per test 256 megabytes input standa ...