Go -- LRU算法(缓存淘汰算法)(转)
1. LRU
1.1. 原理
LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
1.2. 实现
最常见的实现是使用一个链表保存缓存数据,详细算法实现如下:
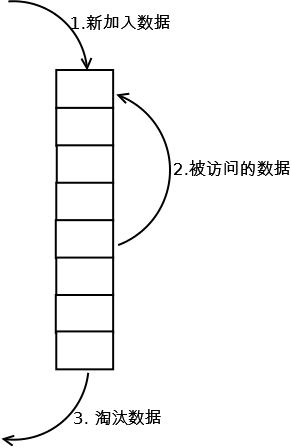
1. 新数据插入到链表头部;
2. 每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
3. 当链表满的时候,将链表尾部的数据丢弃。
1.3. 分析
【命中率】
当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
【复杂度】
实现简单。
【代价】
命中时需要遍历链表,找到命中的数据块索引,然后需要将数据移到头部。
2. LRU-K(描述有误,请勿参考)
2.1. 原理
LRU-K中的K代表最近使用的次数,因此LRU可以认为是LRU-1。LRU-K的主要目的是为了解决LRU算法“缓存污染”的问题,其核心思想是将“最近使用过1次”的判断标准扩展为“最近使用过K次”。
2.2. 实现
相比LRU,LRU-K需要多维护一个队列,用于记录所有缓存数据被访问的历史。只有当数据的访问次数达到K次的时候,才将数据放入缓存。当需要淘汰数据时,LRU-K会淘汰第K次访问时间距当前时间最大的数据。详细实现如下:
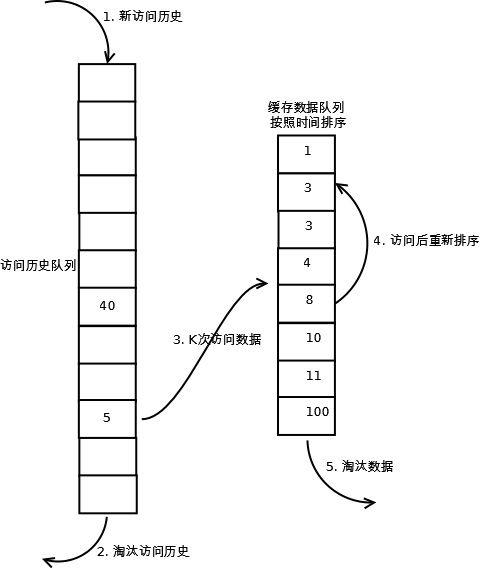
1. 数据第一次被访问,加入到访问历史列表;
2. 如果数据在访问历史列表里后没有达到K次访问,则按照一定规则(FIFO,LRU)淘汰;
3. 当访问历史队列中的数据访问次数达到K次后,将数据索引从历史队列删除,将数据移到缓存队列中,并缓存此数据,缓存队列重新按照时间排序;
4. 缓存数据队列中被再次访问后,重新排序;
5. 需要淘汰数据时,淘汰缓存队列中排在末尾的数据,即:淘汰“倒数第K次访问离现在最久”的数据。
LRU-K具有LRU的优点,同时能够避免LRU的缺点,实际应用中LRU-2是综合各种因素后最优的选择,LRU-3或者更大的K值命中率会高,但适应性差,需要大量的数据访问才能将历史访问记录清除掉。
2.3. 分析
【命中率】
LRU-K降低了“缓存污染”带来的问题,命中率比LRU要高。
【复杂度】
LRU-K队列是一个优先级队列,算法复杂度和代价比较高。
【代价】
由于LRU-K还需要记录那些被访问过、但还没有放入缓存的对象,因此内存消耗会比LRU要多;当数据量很大的时候,内存消耗会比较可观。
LRU-K需要基于时间进行排序(可以需要淘汰时再排序,也可以即时排序),CPU消耗比LRU要高。
3. Two queues(2Q)
3.1. 原理
Two queues(以下使用2Q代替)算法类似于LRU-2,不同点在于2Q将LRU-2算法中的访问历史队列(注意这不是缓存数据的)改为一个FIFO缓存队列,即:2Q算法有两个缓存队列,一个是FIFO队列,一个是LRU队列。
3.2. 实现
当数据第一次访问时,2Q算法将数据缓存在FIFO队列里面,当数据第二次被访问时,则将数据从FIFO队列移到LRU队列里面,两个队列各自按照自己的方法淘汰数据。详细实现如下:
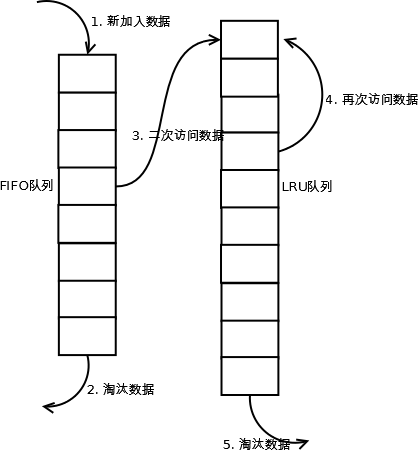
1. 新访问的数据插入到FIFO队列;
2. 如果数据在FIFO队列中一直没有被再次访问,则最终按照FIFO规则淘汰;
3. 如果数据在FIFO队列中被再次访问,则将数据移到LRU队列头部;
4. 如果数据在LRU队列再次被访问,则将数据移到LRU队列头部;
5. LRU队列淘汰末尾的数据。
注:上图中FIFO队列比LRU队列短,但并不代表这是算法要求,实际应用中两者比例没有硬性规定。
3.3. 分析
【命中率】
2Q算法的命中率要高于LRU。
【复杂度】
需要两个队列,但两个队列本身都比较简单。
【代价】
FIFO和LRU的代价之和。
2Q算法和LRU-2算法命中率类似,内存消耗也比较接近,但对于最后缓存的数据来说,2Q会减少一次从原始存储读取数据或者计算数据的操作。
4. Multi Queue(MQ)
4.1. 原理
MQ算法根据访问频率将数据划分为多个队列,不同的队列具有不同的访问优先级,其核心思想是:优先缓存访问次数多的数据。
4.2. 实现
MQ算法将缓存划分为多个LRU队列,每个队列对应不同的访问优先级。访问优先级是根据访问次数计算出来的,例如
详细的算法结构图如下,Q0,Q1....Qk代表不同的优先级队列,Q-history代表从缓存中淘汰数据,但记录了数据的索引和引用次数的队列:
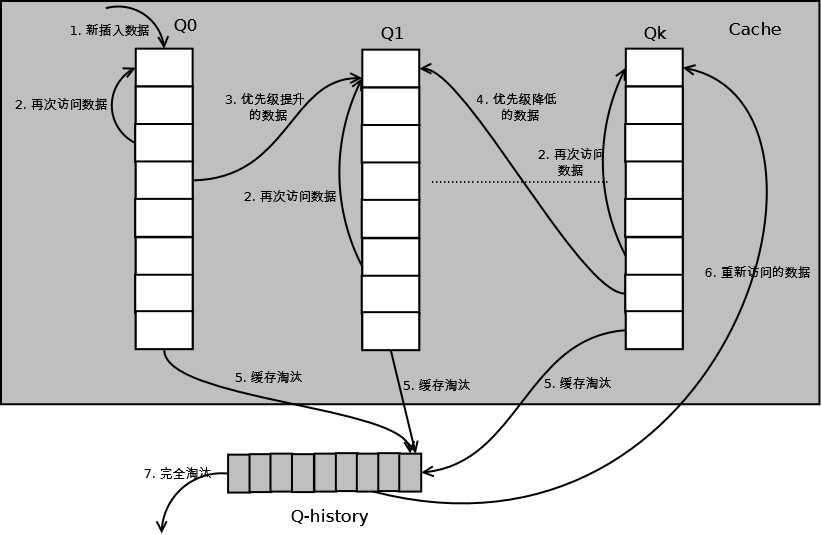
如上图,算法详细描述如下:
1. 新插入的数据放入Q0;
2. 每个队列按照LRU管理数据;
3. 当数据的访问次数达到一定次数,需要提升优先级时,将数据从当前队列删除,加入到高一级队列的头部;
4. 为了防止高优先级数据永远不被淘汰,当数据在指定的时间里访问没有被访问时,需要降低优先级,将数据从当前队列删除,加入到低一级的队列头部;
5. 需要淘汰数据时,从最低一级队列开始按照LRU淘汰;每个队列淘汰数据时,将数据从缓存中删除,将数据索引加入Q-history头部;
6. 如果数据在Q-history中被重新访问,则重新计算其优先级,移到目标队列的头部;
7. Q-history按照LRU淘汰数据的索引。
4.3. 分析
【命中率】
MQ降低了“缓存污染”带来的问题,命中率比LRU要高。
【复杂度】
MQ需要维护多个队列,且需要维护每个数据的访问时间,复杂度比LRU高。
【代价】
MQ需要记录每个数据的访问时间,需要定时扫描所有队列,代价比LRU要高。
注:虽然MQ的队列看起来数量比较多,但由于所有队列之和受限于缓存容量的大小,因此这里多个队列长度之和和一个LRU队列是一样的,因此队列扫描性能也相近。
5. LRU类算法对比
由于不同的访问模型导致命中率变化较大,此处对比仅基于理论定性分析,不做定量分析。
|
对比点 |
对比 |
|
命中率 |
LRU-2 > MQ(2) > 2Q > LRU |
|
复杂度 |
LRU-2 > MQ(2) > 2Q > LRU |
|
代价 |
LRU-2 > MQ(2) > 2Q > LRU |
实际应用中需要根据业务的需求和对数据的访问情况进行选择,并不是命中率越高越好。例如:虽然LRU看起来命中率会低一些,且存在”缓存污染“的问题,但由于其简单和代价小,实际应用中反而应用更多。
Go -- LRU算法(缓存淘汰算法)(转)的更多相关文章
- LRU算法---缓存淘汰算法
计算机中的缓存大小是有限的,如果对所有数据都缓存,肯定是不现实的,所以需要有一种淘汰机制,用于将一些暂时没有用的数据给淘汰掉,以换入新鲜的数据进来,这样可以提高缓存的命中率,减少磁盘访问的次数. LR ...
- 04 | 链表(上):如何实现LRU缓存淘汰算法?
今天我们来聊聊“链表(Linked list)”这个数据结构.学习链表有什么用呢?为了回答这个问题,我们先来讨论一个经典的链表应用场景,那就是+LRU+缓存淘汰算法. 缓存是一种提高数据读取性能的技术 ...
- 数据结构与算法之美 06 | 链表(上)-如何实现LRU缓存淘汰算法
常见的缓存淘汰策略: 先进先出 FIFO 最少使用LFU(Least Frequently Used) 最近最少使用 LRU(Least Recently Used) 链表定义: 链表也是线性表的一种 ...
- 链表:如何实现LRU缓存淘汰算法?
缓存淘汰策略: FIFO:先入先出策略 LFU:最少使用策略 LRU:最近最少使用策略 链表的数据结构: 可以看到,数组需要连续的内存空间,当内存空间充足但不连续时,也会申请失败触发GC,链表则可 ...
- 《数据结构与算法之美》 <04>链表(上):如何实现LRU缓存淘汰算法?
今天我们来聊聊“链表(Linked list)”这个数据结构.学习链表有什么用呢?为了回答这个问题,我们先来讨论一个经典的链表应用场景,那就是 LRU 缓存淘汰算法. 缓存是一种提高数据读取性能的技术 ...
- 昨天面试被问到的 缓存淘汰算法FIFO、LRU、LFU及Java实现
缓存淘汰算法 在高并发.高性能的质量要求不断提高时,我们首先会想到的就是利用缓存予以应对. 第一次请求时把计算好的结果存放在缓存中,下次遇到同样的请求时,把之前保存在缓存中的数据直接拿来使用. 但是, ...
- 图解缓存淘汰算法二之LFU
1.概念分析 LFU(Least Frequently Used)即最近最不常用.从名字上来分析,这是一个基于访问频率的算法.与LRU不同,LRU是基于时间的,会将时间上最不常访问的数据淘汰;LFU为 ...
- 缓存淘汰算法之FIFO
前段时间去网易面试,被这个问题卡住,先做总结如下: 常用缓存淘汰算法 FIFO类:First In First Out,先进先出.判断被存储的时间,离目前最远的数据优先被淘汰. LRU类:Least ...
- 缓存淘汰算法--LRU算法
1. LRU1.1. 原理 LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是"如果数据最近被访问过,那么将来被访问的几率也 ...
随机推荐
- JAVA、JDK等入门概念,下载安装JAVA并配置环境变量
一.概念 Java是一种可以撰写跨平台应用程序的面向对象的程序设计语言,具体介绍可查阅百度JAVA百科,这里不再赘述. Java分为三个体系,分别为: Java SE(J2SE,Java2 Platf ...
- c++ override 关键字
描述:override保留字表示当前函数重写了基类的虚函数. 目的:1.在函数比较多的情况下可以提示读者某个函数重写了基类虚函数(表示这个虚函数是从基类继承,不是派生类自己定义的):2.强制编译器检查 ...
- HDU 5371 Manacher Hotaru's problem
求出一个连续子序列,这个子序列由三部分ABC构成,其中AB是回文串,A和C相同,也就是BC也是回文串. 求这样一个最长的子序列. Manacher算法是在所有两个相邻数字之间插入一个特殊的数字,比如- ...
- idea Live Template 快速使用
善用LiveTemplates,好用到没朋友,我凑揍 , 尊重原创,原文链接: https://blog.csdn.net/u012721933/article/details/52461103#co ...
- Jquery+Ajax+asp.net+sqlserver-编写的通用邮件管理(源码)
开始 邮件管理通常用在各个内部系统中,为了方便快捷的使用现有的代码开发一个邮件管理系统而诞生的. 准备条件 这是我的设计表结构,大家一看就懂了 --邮件接收表CREATE TABLE [dbo]. ...
- gdb调试手册 一 gdb概述
一 gdb概述 gdb调试器的目的是让你了解其他的程序在执行的时候发生了什么或者其他程序崩溃时正在做什么 gdb主要能够在运行中做四类事情(包括这些事情中的一些附加的事情)来帮助你获取bugs a 运 ...
- TOJ 3581: 最简IPv6表示
3581: 最简IPv6表示 Time Limit(Common/Java):1000MS/3000MS Memory Limit:65536KByteTotal Submit: 121 ...
- [错误解决]Ubuntu中使用dpkg安装deb文件提示依赖关系问题,仍未被配置
使用dpkg进行软件安装时,提示:dpkg:处理软件包XXX时出错:依赖关系问题,仍未被配置 使用如下命令,sudo apt-get install -f 等分析完之后,重新使用dpkg –i XXX ...
- pip安装超时,更换国内镜像源安装
pip安装超时问题 pip install --index 源地址 安装包 常用镜像源地址: http://pypi.douban.com/ 豆瓣 http://pypi.mirrors.ustc.e ...
- 异常详细信息: System.Data.SqlClient.SqlException: 用户 'NT AUTHORITY\IUSR' 登录失败解决办法
最近在做.net项目,因为本人以前做java较多,所以对.net不熟悉,在项目完成后部署到IIS服务器上出现诸多问题,以上其中之一,若有时间,在更新其他问题的解决办法! 异常详细信息: System. ...