使用SQL-Server分区表功能提高数据库的读写性能
首先祝大家新年快乐,身体健康,万事如意。
一般来说一个系统最先出现瓶颈的点很可能是数据库。比如我们的生产系统并发量很高在跑一段时间后,数据库中某些表的数据量会越来越大。海量的数据会严重影响数据库的读写性能。
这个时候我们会开始优化系统,一般会经过这么几个过程:
- 找出SQL慢查询,针对该SQL进行优化,比如改进SQL的写法,查看执行计划对全表扫描的字段建立索引
- 引入缓存,把一部分读压力加载到内存中
- 读写分离
- 引入队列,把并发的请求使其串行化,来减轻系统瞬时压力
- 分表/分库
对于第五点优化方案我们来细说一下。分表分库通常有两种拆分维度:1.垂直切分,垂直切分往往跟业务有强相关关系,比如把某个表的某些不常用的字段迁移出去,比如订单的明细数据可以独立成一张表,需要使用的时候才读取 2.水平切分,比如按年份来拆分,把数据库按年或者按某些规则按时间段分成多个表。
拆分表之后每个表的数据量将会变小,带来的好处是不言而喻的。不管是全表扫描,还是索引查询都会有比较高的提升。如果把不同的表文件落在多个磁盘上那数据库的IO性能还能进一步提高。
如果纯手工拆分,比如按年份拆分成多个表,那么上层业务代码也得进行调整。每次读写都得判断该使用哪张表。如果是跨多个年份的分页查询更加难搞。人肉分表基本上不可能实现的,对于上层编码简直是个噩梦。所以针对分表分库我们通常会使用某些中间件,比如Mycat,Sharding-JDBC等中间件。使用这些组件确实能实现分表分库,并且对业务层代码屏蔽了数据库架构的改动,但是配置略显麻烦。如果你使用的是SQL Server数据库,并且目前还不需要分库,只需要分表,那么其实使用内置的分区表功能是最简单的方案。只需要打开SQL Server Management Studio简单设置几下就可以了,对于你上层应用完全是无感的,你的代码、数据库连接串都不需要改动。
以下我们通过2个简单的测试,来简单的演示下如何进行表分区操作,以及测试下分区前后性能变化。
测试写性能
我们的测试方案:新建一张logs表,按年份写入数据。2019年写入1000000数据,2020年也写入100000数据。为了加快写入的速度,每个年份并行10个线程同时写,每个线程写100000数据,一共1000000数据。然后把logs表改成分区表再用同样的方式写入2000000数据。记录耗时 比较两次的耗时。
硬件为一台14年产的笔记本,OS为win10。挂载2块硬盘,1块为5400转的机械硬盘,1块为15年加的SSD。磁盘性能可以说极为垃圾。未分区时表文件会落在机械硬盘上。
未分区情况下测试
使用脚本建表:
CREATE TABLE [dbo].[logs](
[id] [uniqueidentifier] NOT NULL,
[log_txt] [varchar](200) NULL,
[log_time] [datetime] NULL,
CONSTRAINT [PK_logs] PRIMARY KEY CLUSTERED
(
[id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
)
新建一个控制台程序编写代码:
class Program
{
static void Main(string[] args)
{
Console.WriteLine("Hello World!");
Task.Run(() =>
{
InsertData(2019);
});
Task.Run(() =>
{
InsertData(2020);
});
Console.ReadLine();
}
static void InsertData(int year)
{
var tasks = new List<Task>();
Stopwatch sw = new Stopwatch();
sw.Start();
for (int i = 0; i < 10; i++)
{
tasks.Add(Task.Run(()=> {
using (var conn = new SqlConnection())
{
conn.ConnectionString = "Persist Security Info = False; User ID =sa; Password =dev@123; Initial Catalog =fq_test; Server =.\\mssql2016";
conn.Open();
int index = 0;
for (int j = 0; j < 100000; j++)
{
var logtime = new DateTime(year, new Random().Next(1, 12), new Random().Next(1, 28));
conn.Execute("insert into logs2 values (newid(),'下订单',@logtime)", new
{
logtime
});
Console.WriteLine("logtime:{0} index {1}", logtime, index++);
}
}
}));
}
Task.WaitAll(tasks.ToArray());
sw.Stop();
Console.WriteLine("Year {0} complete , total time: {1}.", year, sw.ElapsedMilliseconds);
}
}
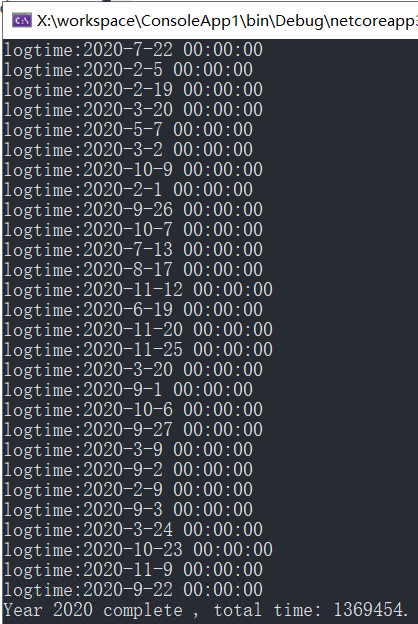
写完2000000数据耗时1369454毫秒。
分区情况下进行测试
开始分区
把一个表设置为分区表大概有5个步骤:
- 添加文件组
- 在文件组添加文件
- 新建分区函数
- 新建分区方案
- 开始分区
以下演示下如何使用SQL SERVER Management Studio管理器进行表分区:
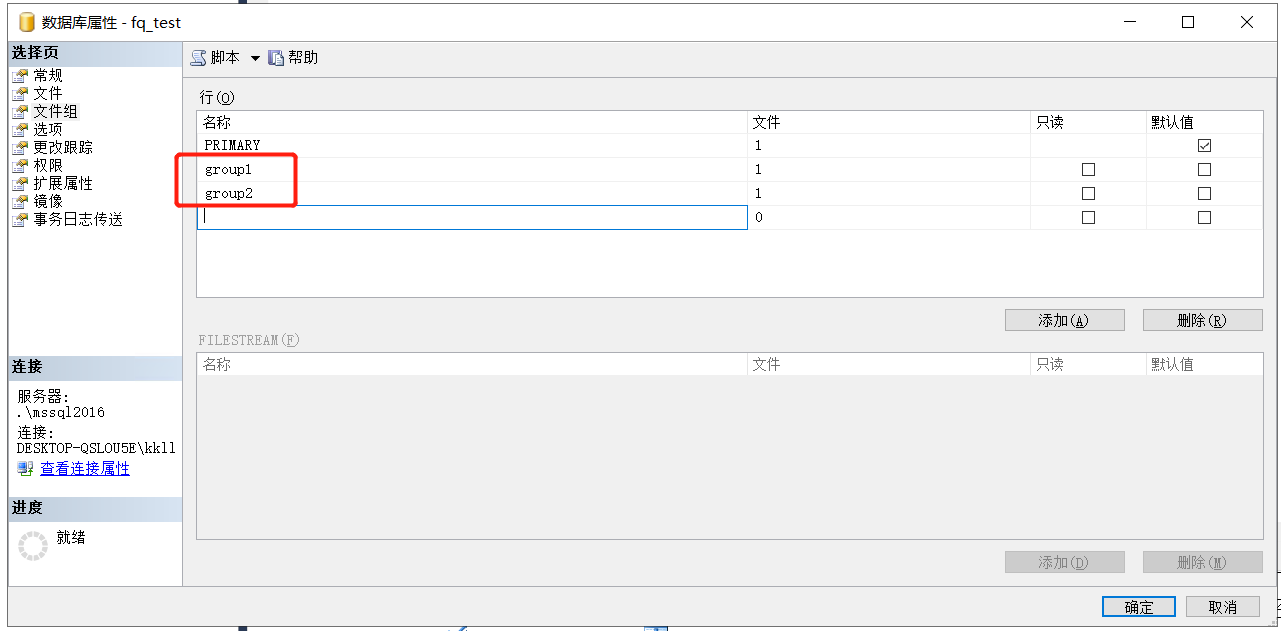
选中数据库=>属性=>文件组,添加group1,group2两个文件组。
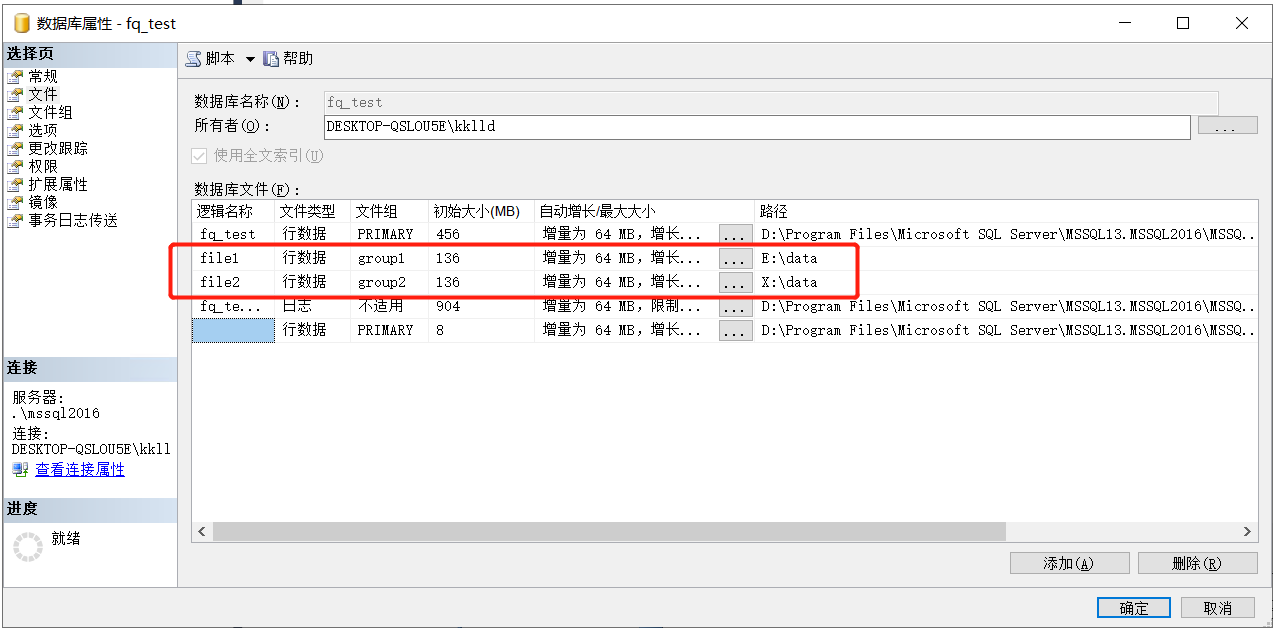
选中数据库=>属性=>文件。添加file1,文件组选group1,路径选择一个文件目录。这里选择E盘data目录。添加file2,文件组选择group2,路径选择一个文件目录。这里选择X盘的data目录。这样当分区的时候数据就会落在这2个目录下。这里的路径可以选择在同一个硬盘,但是为了更高的读写性能,如果有条件建议直接指定在不同的硬盘下。
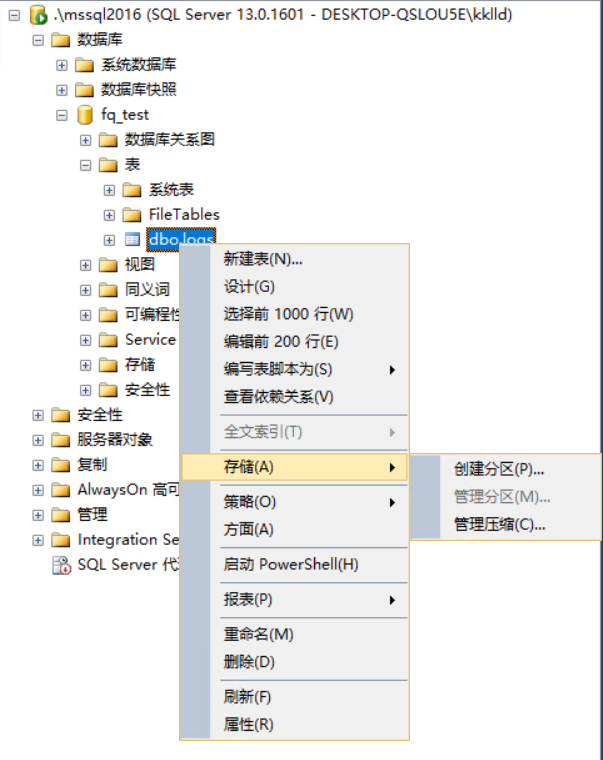
选中logs表=>存储=>创建分区,启动分区向导工具。
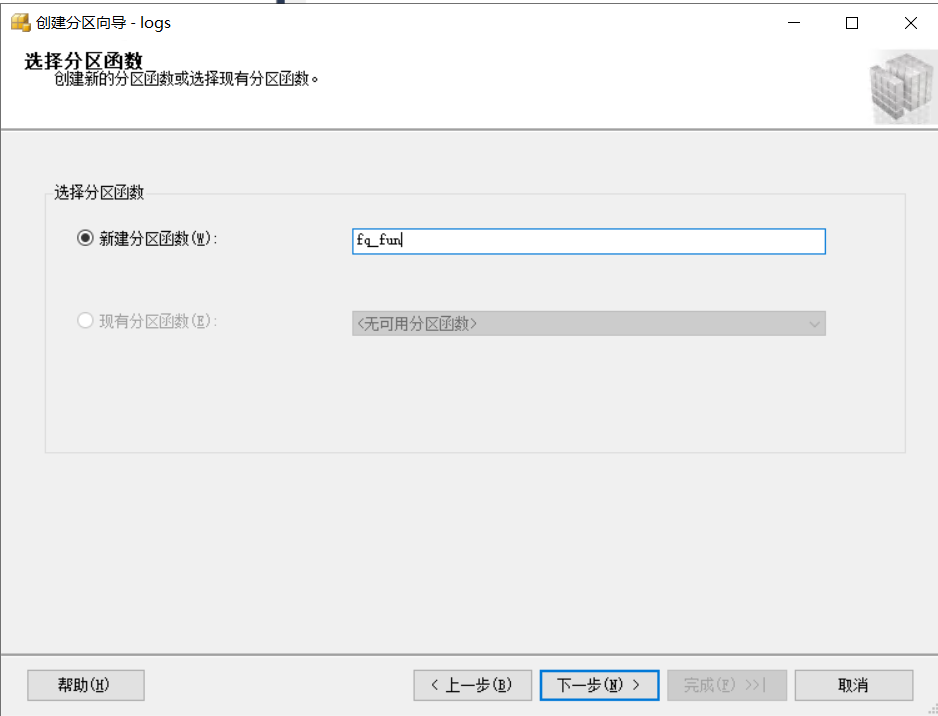
新建一个分区函数,点击下一步。
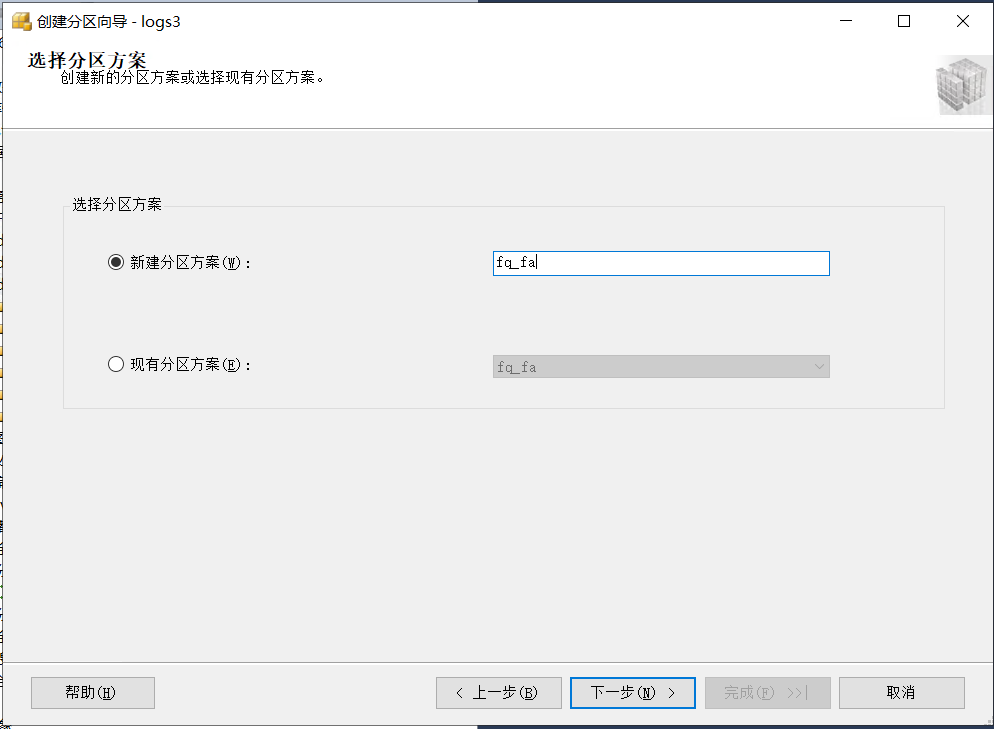
新建一个分区方案,点击下一步。
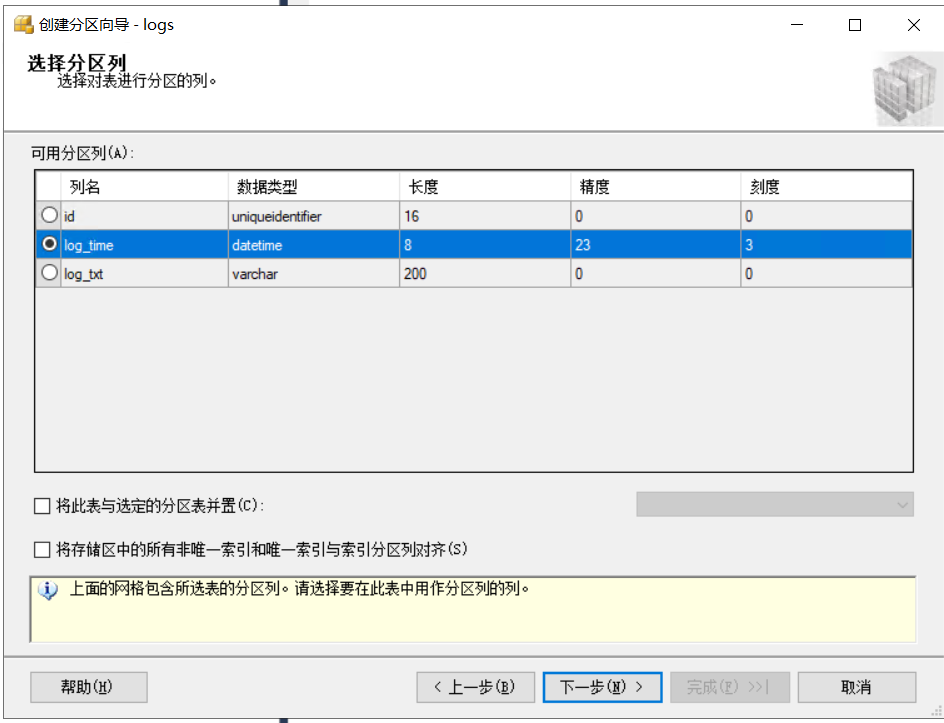
选择一个分区列,数据会根据该列进行水平拆分。这里选择logtime,因为时间是比较适合水平切分的一个维度。
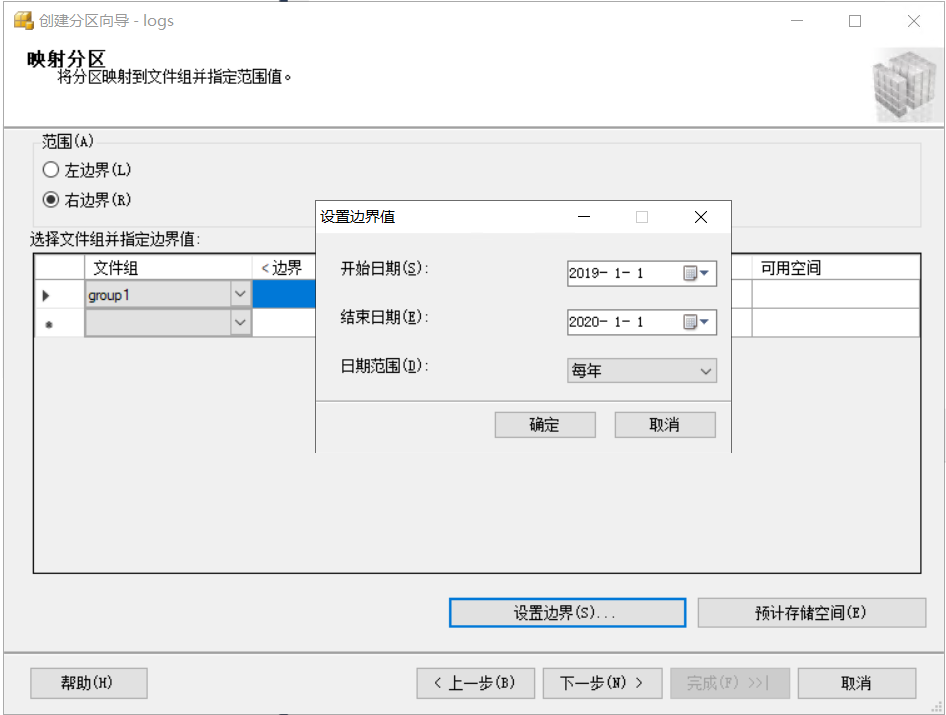
值得数据拆分的范围。范围选择“右边界”。右边界跟左边界的差异在于对边界值的处理。右边界是<,左边界是<=,也就是包含边界值。
我们这里设置group1存储2019的数据,group2存储2020的数据。所以group1的边界值设置为2020-01-01,group2的边界值设置为2021-01-01 。
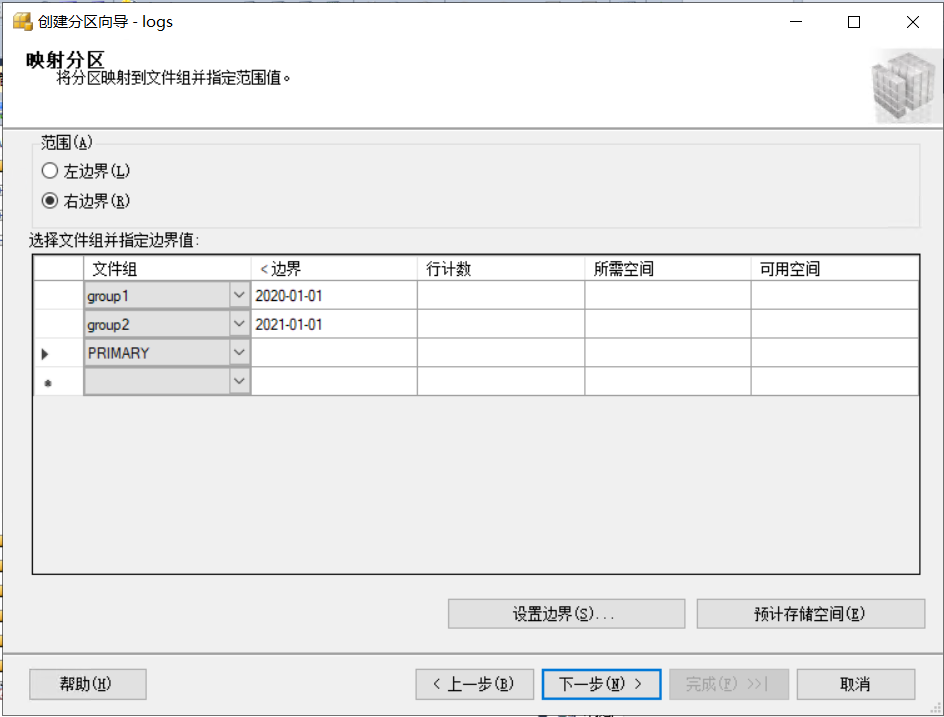
设置完是这个样子,需要3个文件组。当出现不在group1,group2范围内的数据就会存储在第三个文件组内。
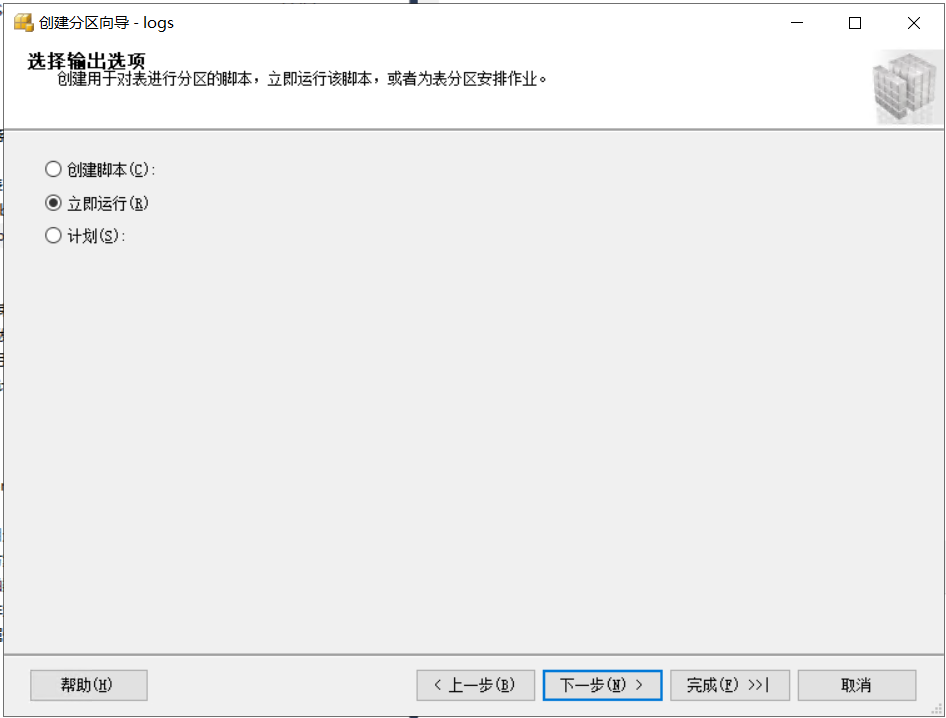
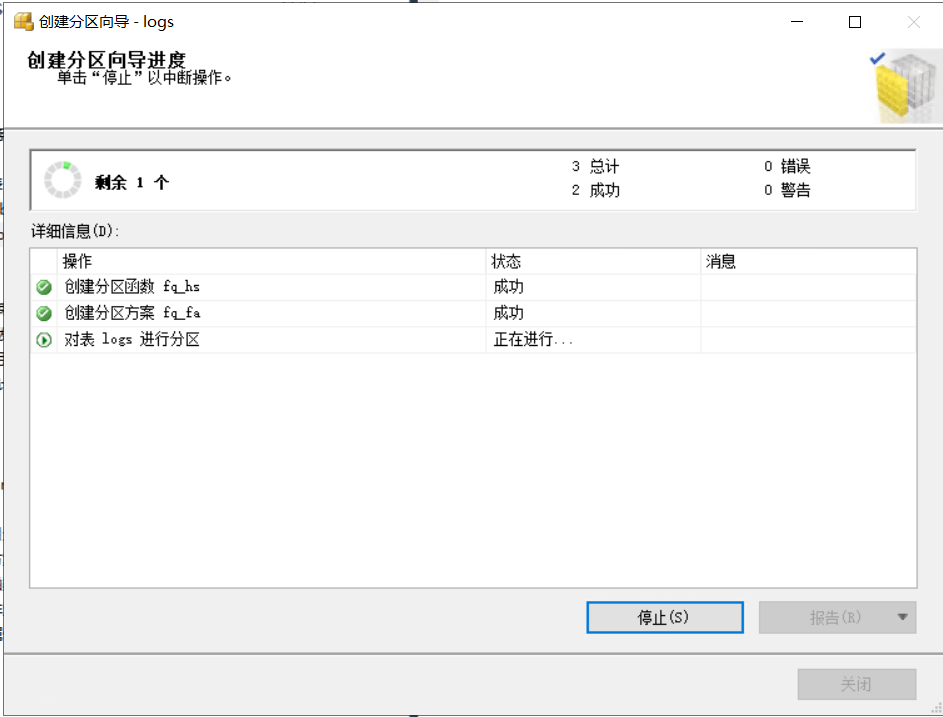
建好分区函数、分区方案后,可以选择生成脚本或者立即执行。这里选择“立即执行”。当执行完成后,表里的数据会按照分区方案设置的边界分散到多个文件上。
在分区情况下进行测试
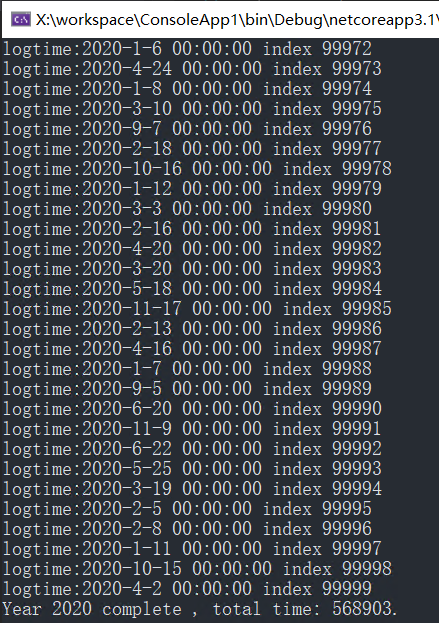
先清空logs表所有的数据,然后使用同样的代码进行测试。测试结果显示写完2000000数据耗时:568903毫秒。可以看到数据库写性能大副提高,大概提高了1倍不止的性能。这也比较符合两块磁盘同时IO的预期。
测试读性能
我们的测试方案:新建一张log2表,使用上面的代码按年份写入2000000数据。然后使用select语句同时读取2019,2020年的数据。把log表转换成分区表,重新测试select的时间。比较两次读取数据的时间。
sql语句:
select * from log2 where (logtime > '2019-05-01' and logtime < '2019-06-01') or (logtime > '2020-05-01' and logtime < '2020-06-01')
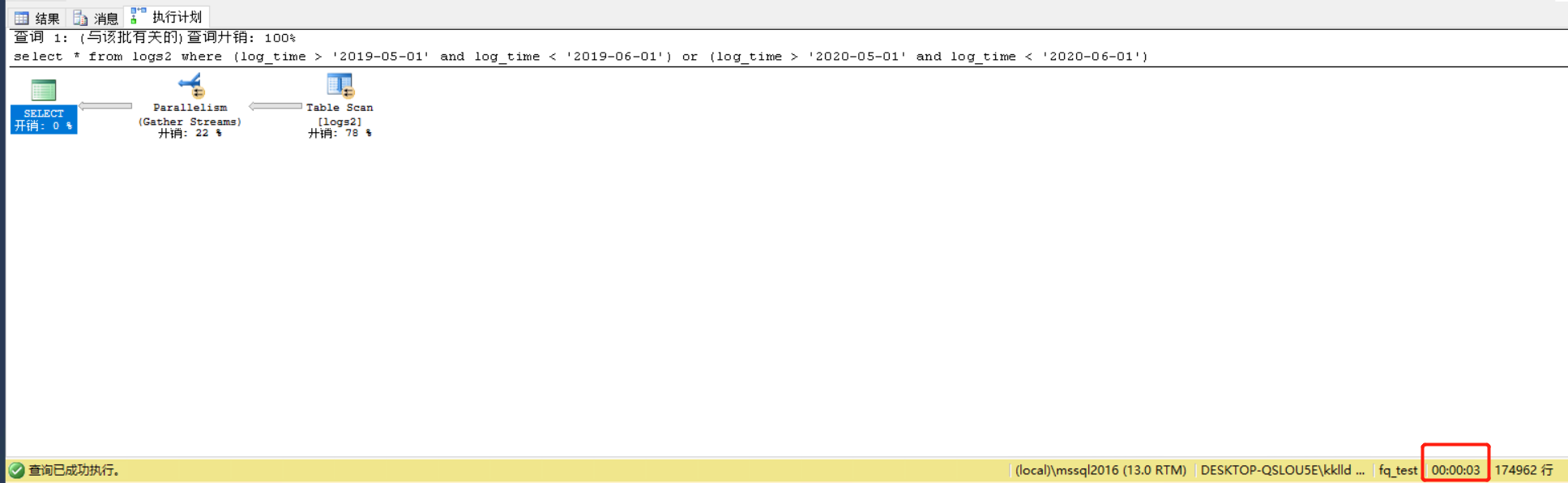
首先在未分区的表上测试查询性能,花费时间为3s。
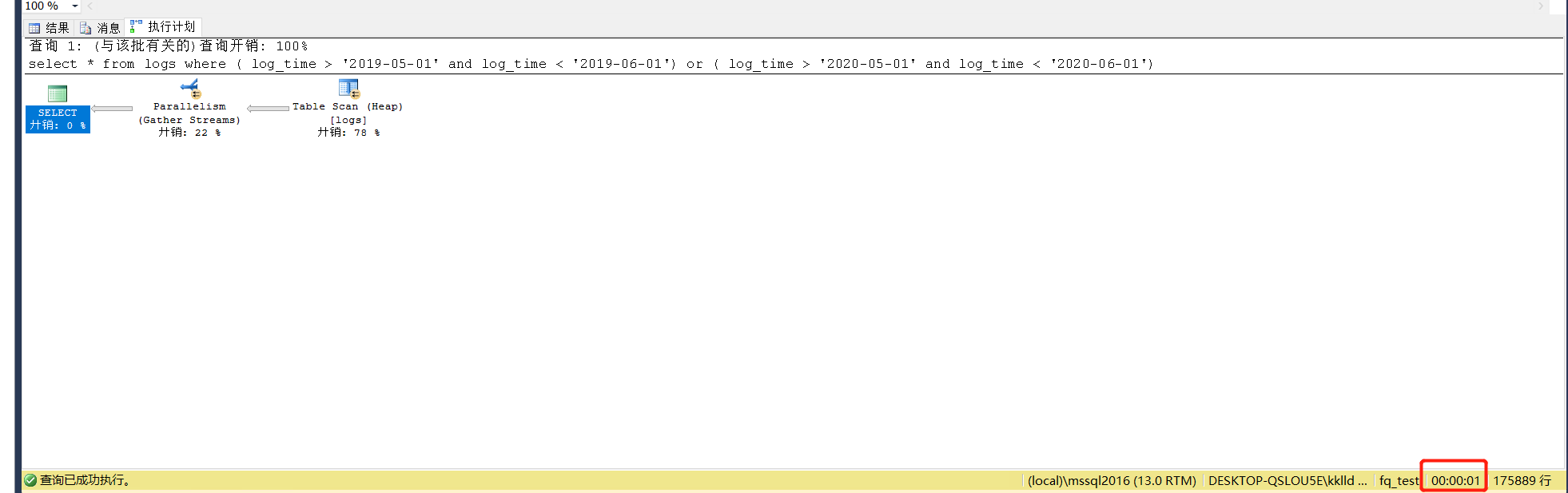
把表按前面的方法进行分区拆分,查询花费时间为1s。读性能大概为未分区时的3倍。
总结
经过简单的测试,SQL Server的分区表功能能大副提高数据库的读写性能。通过SQL Server Management Stduio的简单设置就可以对数据库表进行分区操作,并且对应用层的代码完全是无感的,比用分表分库中间件来说简单多了。
关注我的公众号一起玩转技术

使用SQL-Server分区表功能提高数据库的读写性能的更多相关文章
- 走向DBA[MSSQL篇] 从SQL语句的角度 提高数据库的访问性能
原文:走向DBA[MSSQL篇] 从SQL语句的角度 提高数据库的访问性能 最近公司来一个非常虎的dba 10几年的经验 这里就称之为蔡老师吧 在征得我们蔡老同意的前提下 我们来分享一下蔡老给我们 ...
- 走向DBA[MSSQL篇] - 从SQL语句的角度提高数据库的访问性能(转)
最近公司来一个非常虎的DBA,10几年的经验,这里就称之为蔡老师吧,在征得我们蔡老同意的前提下 ,我们来分享一下蔡老给我们带来的宝贵财富,欢迎其他的DBA来拍砖. 目录 1.什么是执行计划?执行计划 ...
- 智能SQL优化工具--SQL Optimizer for SQL Server(帮助提升数据库应用程序性能,最大程度地自动优化你的SQL语句 )
SQL Optimizer for SQL Server 帮助提升数据库应用程序性能,最大程度地自动优化你的SQL语句 SQL Optimizer for SQL Server 让 SQL Serve ...
- [MSSQL]从SQL语句的角度 提高数据库的访问性能
1.什么是执行计划?执行计划是依赖于什么信息. 2. 统一SQL语句的写法减少解析开销 3. 减少SQL语句的嵌套 4. 使用“临时表”暂存中间结果 5. OLTP系统SQL语句必须采用绑定变量 6. ...
- 腾讯云数据库团队:SQL Server 数据加密功能解析
数据加密是数据库被破解.物理介质被盗.备份被窃取的最后一道防线:数据加密,一方面解决数据被窃取安全问题,另一方面有关法律要求强制加密数据:SQL Server 的数据加密相较于其他数据库,功能相对完善 ...
- 数据库SQL Server 2016“功能选择”详细说明及精简安装选择
前言 在平时大家安装数据库的时候,一般默认功能选择都会选择全选.但是前两天公司同事问我:"那么多功能为什么都能用到嘛?"顿时,我思考了一下确实没有详细了解每个功能的详细作用,于是花 ...
- SQL Server 数据加密功能解析
SQL Server 数据加密功能解析 转载自: 腾云阁 https://www.qcloud.com/community/article/194 数据加密是数据库被破解.物理介质被盗.备份被窃取的最 ...
- SQL Server 安装 功能详解
安装 SQL Server 功能 在“功能选择”页上,SQL Server 功能分为以下两个主要部分:实例功能和共享功能. “实例功能”表示为每个实例安装一次的组件,这样,您将具有它们的多个副 ...
- Sql Server来龙去脉系列之四 数据库和文件
在讨论数据库之前我们先要明白一个问题:什么是数据库? 数据库是若干对象的集合,这些对象用来控制和维护数据.一个经典的数据库实例仅仅包含少量的数据库,但用户一般也不会在一个实例上创建太多 ...
随机推荐
- 自翻------Office 2013 RT 使用说明
Office Home and Student 2013 RT Preview的更新 介绍 Microsoft已发布Microsoft Office Home and Student 2013 RT ...
- JavaScript中创建对象的三种方式!
JavaScript中创建对象的三种方式! 第一种 利用对象字面量! // 创建对象的三种方式! // 1 对象字面量. var obj = { // 对象的属性和方法! name: 'lvhang' ...
- ArchLinux安装后所需要的环境和工具
ArchLinux安装后所需要的环境和工具 工具: Dolphin 文件管理器 ntfs-3G 移动硬盘挂载 octopi 实时检查更新 KDE Connect 手机电脑远程连接 DBeaver Co ...
- Manachar’s Algorithm
Manachar's Algorithm Longest palindromic substring - Wikipedia https://en.wikipedia.org/wiki/Longes ...
- ETL调优的一些分享(下)(转载)
如在上篇文章<ETL调优的一些分享(上)>中已介绍的,ETL是构建数据仓库的必经一环,它的执行性能对于数据仓库构建性能有重要意义,因此对它进行有效的调优将十分重要.ETL业务的调优可以从若 ...
- https://github.com/golang/go/wiki/CommonMistakes
CommonMistakes https://golang.org/doc/faq#closures_and_goroutines Why is there no goroutine ID? ¶ Go ...
- 收集整理Idea常用配置及插件
收集整理Idea常用配置及插件 一.IDEA配置 1.1 代码智能提示,忽略大小写 二.IDEA插件 2.1 Background Image Plus 2.2 Codota-代码智能提示 2.3 S ...
- Web信息收集之搜索引擎-Zoomeye Hacking
Web信息收集之搜索引擎-Zoomeye Hacking https://www.zoomeye.org ZoomEye(钟馗之眼)是一个面向网络空间的搜索引擎,"国产的Shodan&quo ...
- NATAPP--实现SSH内网穿透
NATAPP--实现SSH内网穿透 1. 关于Natapp 2. 使用Natapp 3. Natapp安装和配置 4. XShell连接 相关参考博文原文地址: CSDN:KevenPotter:NA ...
- socket套接字编程(1)——基本函数
TCP交互流程: 服务器:1. 创建socket:2. 绑定socket和端口号:3. 监听端口号:4. 接收来自客户端的连接请求:5. 从socket中读取字符:6. 关闭socket. 客户端:1 ...