python序列化与反序列化(json、pickle)-(五)
1.什么是序列化&反序列化?
序列化:将字典、列表、类的实例对象等内容转换成一个字符串的过程。
反序列化:将一个字符串转换成字典、列表、类的实例对象等内容的过程

PS:Python中常见的数据结构可以统称为容器。序列(如列表和元组)、映射(如字典)以及集合(set)是三类主要的容器。
场景一:我们在python中将一个功能给另外一段程序使用,怎么给?
方法一:功能存到文件,然后另一个python程序再从文件里读出来。
场景二:现在反过来怎么把读出来的文件字符串转换成字典?
方法二:eval()函数:将字符串str当成有效的表达式求值并返回计算结果,但存在风险,将str转换成python中的数据结构,推荐使用反序列化。
序列化就是从dic变成str(dic)的过程,反序列化就是从str(dic)变成dic的过程。
2.为什们要使用序列化?
序列化的目的:
1.以某种存储形式使自定义对象持久化(比如从内存存到硬盘)
2.将对象从一个地方传递到另一个地方
3.使程序更具维护性
序列化的2个模块:
json:用于字符串(str)和python数据类型间(比如字典、列表)进行转换
pickle:用于python特有的类型和python的数据类型间转换
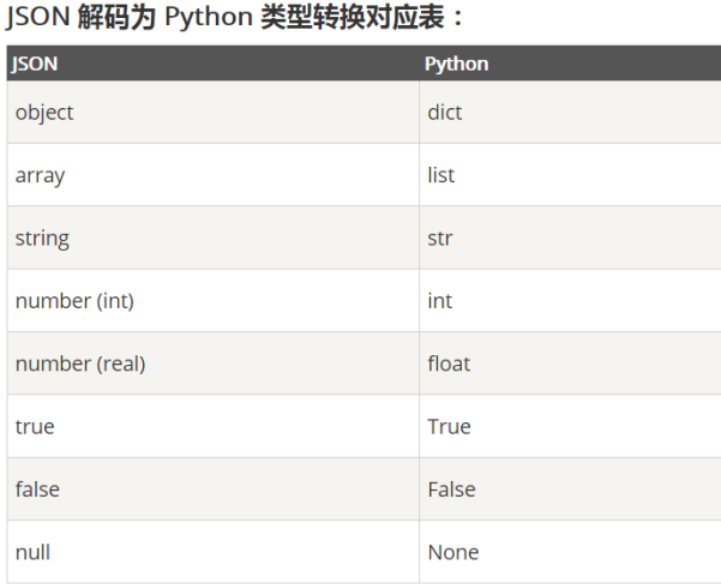
3.json
Json是一种轻量级的数据交换格式,基于ECMAScript的一个子集。Python3中可以使用json模块来对json数据进行编解码.
python本质:字符串,字符串中的值用双引号,包含了2个函数:
python对象->json:json.dumps(python对象)
json->python对象:json.loads(json字符串)
json.dumps():对数据进行编码,就是将mysql里的数据字符串或二进制的形式存储到硬盘。
dumps:输出到终端的操作方法,也就是把一个类型变量转换成str
dump:文件操作的方法,具体的操作json.dump(dict,open('test','w'))
json.loads():对数据进行解码,将抽象的数据内容(python对象)转换成字符串。
json.load和json.loads是反序列化输出的一个结果,dump和dumps是序列化输出终端或文件中去.
python对象(基本的数据类型):int、float、str、list、tuple、dict
需求:序列化,将字典info转换成字符串,存到test1.txt文件中。

ex1:用dumps()函数序列化,通过f.write()写入同级目录test1.txt文件。
import json
info={
'name':'wendy',
'age':22
}
f=open("test1.txt",'w')
#json.dumps(info)把一个字典info转换成字符串,从内存存到硬盘的过程叫序列化
#序列化dumps函数不可以序列化,只能处理简单的跨平台数据交互
f.write(json.dumps(info))
f.close()
ex2:用dump()函数序列化,直接json.dump()写入test1.txt文件。
import json
info={
'name':'wendy',
'age':22
}
f=open("test1.txt",'w')
#等于f.write(json.dumps(info))
json.dump(info,f)
f.close()
需求:用loads()函数反序列化,将字符串转换成python对象
#方式一:将字符串转换成python对象
import json
json_str1="""{"name": "wendy", "age": 22}"""
json_str3 = """12"""
name1=json.loads(json_str1) #将字符串转换成字典
name2=json.loads(json_str3) #将数字转换成数字
print(type(name1),type(name2)) #打印类型
print(name1,name2)
#显示结果如下:
<class 'dict'> <class 'int'>
{'name': 'wendy', 'age': 22} 12 #方式二:从同级目录test1.txt中取值,将字符串转换成python对象
#test1.txt中的值:{"name": "wendy", "age": 22}
import json
f=open("test1.txt",'r')
data =json.loads(f.read())#等于json.load(f)
print(data["name"])
#显示结果如下:
wendy
4.pickle
pickle的load、loads和dump、dumps的使用操作,先来说下,pickle和json的差异:
4.1 pickle和json都可以实现序列化和反序列化的操作
4.2 在写入文件的时候,pickle是以加密的方式写入的,在打开文件的时候用'rb'模式,用‘wb’模式写入(二进制的形式)
4.3 pickle可以对类创建的对象进行反序列化输入到文件中
pickle模块的4个功能:dump(序列化,存)、dumps、loads(反序列化,读)、load
import pickle
class ABC:
a=10
def __init__(self,m,n):
self.m=m
self.n=n abc=ABC(1,2)
res=pickle.dumps(abc) #pickle可序列化任意类型,比如:序列化类实例
back_res=pickle.loads(res)
print(res)
print(back_res)
print(back_res.a)
#结果显示
b'\x80\x03c__main__\nABC\nq\x00)\x81q\x01}q\x02(X\x01\x00\x00\x00mq\x03K\x01X\x01\x00\x00\x00nq\x04K\x02ub.'
<__main__.ABC object at 0x000001D7A0B31048>
10
python序列化与反序列化(json、pickle)-(五)的更多相关文章
- day5-python中的序列化与反序列化-json&pickle
一.概述 玩过稍微大型一点的游戏的朋友都知道,很多游戏的存档功能使得我们可以方便地迅速进入上一次退出的状态(包括装备.等级.经验值等在内的一切运行时数据),那么在程序开发中也存在这样的需求:比较简单的 ...
- Python序列化与反序列化-json与pickle
Python序列化与反序列化-json与pickle 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.json的序列化方式与反序列化方式 1>.json序列化 #!/usr ...
- Python开发之序列化与反序列化:pickle、json模块使用详解
1 引言 在日常开发中,所有的对象都是存储在内存当中,尤其是像python这样的坚持一切接对象的高级程序设计语言,一旦关机,在写在内存中的数据都将不复存在.另一方面,存储在内存够中的对象由于编程语言. ...
- python类库32[序列化和反序列化之pickle]
一 pickle pickle模块用来实现python对象的序列化和反序列化.通常地pickle将python对象序列化为二进制流或文件. python对象与文件之间的序列化和反序列化: pi ...
- python模块概况,json/pickle,time/datetime,logging
参考: http://www.cnblogs.com/wupeiqi/articles/5501365.html http://www.cnblogs.com/alex3714/articles/51 ...
- Python序列化和反序列化
Python序列化和反序列化 通过将对象序列化可以将其存储在变量或者文件中,可以保存当时对象的状态,实现其生命周期的延长.并且需要时可以再次将这个对象读取出来.Python中有几个常用模块可实现这一功 ...
- Python 序列化与反序列化
序列化是为了将内存中的字典.列表.集合以及各种对象,保存到一个文件中(字节流).而反序列化是将字节流转化回原始的对象的一个过程. json库 序列化:json.dumps() 反序列化:json.lo ...
- C#序列化及反序列化Json对象通用类JsonHelper
当今的程序界Json大行其道.因为Json对象具有简短高效等优势,广受广大C#码农喜爱.这里发一个序列化及反序列化Json对象通用类库,希望对大家有用. public class JsonHelper ...
- Jackson序列化和反序列化Json数据完整示例
Jackson序列化和反序列化Json数据 Web技术发展的今天,Json和XML已经成为了web数据的事实标准,然而这种格式化的数据手工解析又非常麻烦,软件工程界永远不缺少工具,每当有需求的时候就会 ...
- (推荐JsonConvert )序列化和反序列化Json
在Json文本和.Net对象之间转换最快的方法是试用JsonSerializer. JsonSerializer通过将.Net对象属性名称映射到Json属性名称,并为其复制值,将.Net对象转换为其J ...
随机推荐
- ExecutorService的invokeAny方法注意
package com.msxf.datasource.thirdpart.service.extface; import java.util.HashSet; import java.util.Li ...
- 经典c程序100例==11--20
[程序11] 题目:古典问题:有一对兔子,从出生后第3个月起每个月都生一对兔子,小兔子长到第三个月 后每个月又生一对兔子,假如兔子都不死,问每个月的兔子总数为多少? 1.程序分析: 兔子的规律为数列1 ...
- mysql中key和index的关系
原文链接:https://blog.csdn.net/top_code/article/details/50599840
- 虚拟DOM与diff算法
虚拟DOM与diff算法 虚拟DOM 在DOM操作中哪怕我们的数据,发生了一丢丢的变化,也会被强制重建整预DOM树.这么做,涉及到很多元素的重绘和重排,导致性能浪费严重 只要实现按需更新页面上的元素即 ...
- 01、MyBatis HelloWorld
1. MyBatis简介 1)MyBatis 是支持定制化 SQL.存储过程以及高级映射的优秀的持久层框架 2)MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集 3)MyB ...
- 精尽 MyBatis 源码分析 - 整体架构
该系列文档是本人在学习 Mybatis 的源码过程中总结下来的,可能对读者不太友好,请结合我的源码注释(Mybatis源码分析 GitHub 地址.Mybatis-Spring 源码分析 GitHub ...
- 一个工作三年左右的Java程序员和大家谈谈从业心得
转发链接地址:https://mp.weixin.qq.com/s/SSh9HcA5PgMHv7xiolQkig 貌似这一点适应的行业最广,但是我可以很肯定的说:当你从事web开发一年后,重新找工作时 ...
- Integer 错误的加锁
多线程同时访问一个Integer加锁的问题,程序运行和想要的结果相差甚远,让我百思不得其解,就下来研究了一下: 在进行多线程同步时,加锁是保证线程安全的重要手段之一.synchronized是大多数程 ...
- 人人都能学会系列之ThreadLocal
1.概览 本文我们来看下java.lang包中的ThreadLocal,它赋予我们给每个线程存储自己数据的能力. 2.ThreadLocal API ThreadLocal允许我们存储的数据只能被特定 ...
- nginx学习http_access_module模块
location ~ ^/1.html { root /opt/app/code; deny XXXXX; #这个ip不能访问1.html allow all; #其他的可以访问这个页面1.html ...