机器学习笔记簿 降维篇 LDA 01
机器学习中包含了两种相对应的学习类型:无监督学习和监督学习。无监督学习指的是让机器只从数据出发,挖掘数据本身的特性,对数据进行处理,PCA就属于无监督学习,因为它只根据数据自身来构造投影矩阵。而监督学习将使用数据和数据对应的标签,我们希望机器能够学习到数据和标签的关系,例如分类问题:机器从训练样本中学习到数据和类别标签之间的关系,使得在输入其它数据的时候,机器能够把这个数据分入正确的类别中。线性鉴别分析(Linear Discriminant Analysis, LDA)就是一个监督学习算法,它和PCA一样是降维算法,但LDA是阵对于分类问题所提出的。
1. 一个投影的LDA
设训练样本矩阵为\(X=[x_1,x_2,\cdots,x_n]\in \mathbb R^{m\times n}\),其中样本向量\(x_j\in\mathbb R^m(j=1,2,\cdots,n)\)。假设样本被分为\(c\)个类,编号为\(1,2,\cdots,c\),定义属于第\(i\)个类的样本的集合为\(X_i\),第\(i\)个类的样本个数为\(N_i\)。我们首先定义第\(i\)个类样本的均值为
\]
所有样本的均值为
\]
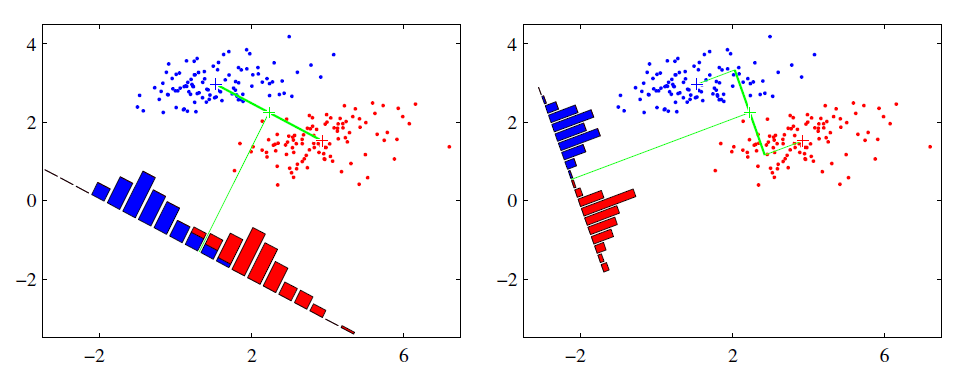
LDA的原理基于Fisher鉴别准则(Fisher Discriminant Criterion),这个准则做出了一个假设:投影后的样本集合,类间散度最大、类内散度最小,其意义在于让投影之后,类和类之间的距离尽量拉开,但是类中的个样本尽量聚集在一起,这就是LDA能够解决分类问题的精髓。设投影向量为\(w\in\mathbb R^m\),那么投影后样本的类间散度可以用总均值和各个类的均值的方差来表示:
&&\max_{w}\sum_{i=1}^cN_i\left(w^T\mu_i-w^T\mu\right)^2\\
&=&\max_{w}\sum_{i=1}^cN_iw^T(\mu_i-\mu)(\mu_i-\mu)^Tw\\
&=&\max_{w}w^T\left[\sum_{i=1}^cN_i(\mu_i-\mu)(\mu_i-\mu)^T\right]w\tag1\\
\end{eqnarray*}\\
\]
同理,类内散度是每一个类中的样本方差之和:
&&\min_w\sum_{i=1}^c\sum_{x\in X_i} \left(w^Tx-w^T\mu_i\right)^2\\
&=&\min_w\sum_{i=1}^c\sum_{x\in X_i}{w^T(x-\mu_i)(x-\mu_i)^Tw}\\
&=&\min_w{w^T\left[\sum_{i=1}^c\sum_{x\in X_i}(x-\mu_i)(x-\mu_i)^T\right]w}\tag{2}
\end{eqnarray*}
\]
因此,为了方便表示,我们定义类间散度矩阵\(S_b\)和类内散度矩阵\(S_w\):
S_b=\sum_{i=1}^cN_i(\mu-\mu_i)(\mu-\mu_i)^T\\
S_w=\sum_{i=1}^c\sum_{x\in X_i}(x-\mu_i)(x-\mu_i)^T
}
\]
则\((1)\)和\((2)\)就可以变为
\]
LDA中通过二者相比,把它们统一成了一个优化问题:
\]
\((3)\)中的目标函数是一个瑞利商(Rayleigh Quotient)(以后会有更多涉及到它的算法)的形式,这里我们先假定\(S_w\)是非奇异的(\(S_w\)是奇异的情况以后会专门讨论),这类优化问题的一般解法是变为以下形式
\]
这个变换是合理的,假设\(w_0\)是\((3)\)中最优的投影向量,由于\(S_w\)非奇异(换句话说,\(S_w\)是正定的),则总存在一个正数\(k\):
\]
那么总存在一个\(w_*=w_0/\sqrt k\),有
\]
这就说明存在一个\(w_*\),使得
\]
也就是说\(w\)的长度不对\((3)\)的求解产生任何影响,因此显然\((3)\)和\((4)\)在这种情况下是等价的。根据\((4)\),使用拉格朗日乘数法得到:
\]
这是一个广义特征方程,由于\(S_w\)正定,所以\(w\)实际上就是\(S_w^{-1}S_b\)最大特征值对应的特征向量。
我们得到了\(w\),就可以将样本投影到一个子空间中,即\(X'=w^TX\),对于训练样本以外的未知数据\(x\),如何辨认它属于哪个类呢?首先把它投影到子空间中:
\]
然后采用K近邻算法(K-Nearest Neighbor, KNN),即找到离\(x'_w\)最近的\(k\)个训练样本(欧式距离),然后统计这\(k\)个样本都是哪个类的,不妨设这些样本的类编号为\(L=[l_1,l_2,\cdots,l_k]\),最后选择\(L\)中的众数作为\(x'\)的分类结果。
KNN是一个十分简易且常用的分类算法,往往取\(k=1,3,5\)进行分类。由于计算高维数据的欧式距离十分耗时,因此KNN常与降维算法配合使用。当然,不只是在使用LDA时才可以使用KNN,PCA以及其它降维算法也可以配合KNN对未知样本进行分类,但PCA的分类效果一般没有LDA好(因为PCA是无监督的)。
2. 多个投影的LDA
现在我们要求的是一个投影矩阵\(W\in\mathbb R^{m\times d}\),优化问题中的类间、类内散度矩阵没有变,优化问题\((3)\)变为:
\]
同样当\(S_w\)是非奇异的时候,我们令\(W^TS_wW=I\),类似的就可以得到,\(W\)即为\(S_w^{-1}S_b\)最大的\(d\)个特征值对应的特征向量组成。在这里我们需要注意,类间散度矩阵的秩总是不大于\(c-1\),即:
\]
所以\(S_w^{-1}S_b\)的非零特征值也最多只有\(c-1\)个,也就是说投影向量的个数\(d\)最多只能有\(c-1\)个,即
\]
因为之后得到的投影向量都将在\(S_b\)的零空间中,假设这个投影向量是\(w'\),则\(S_bw'=0\),对优化没有产生任何帮助,所以这些向量应当舍弃。也就是说LDA中,我们最多只能获取到\(c-1\)个有效的投影。
总结一下,LDA的步骤为:
计算类间、类内散度矩阵\(S_b,S_w\)
计算\(S_b^{-1}S_w\)的特征分解,取前\(d\ (\leq c-1)\)个最大特征值对应的特征向量作为投影矩阵\(W\)
对训练样本投影\(X'=W^TX\),对于未知样本\(x\)也投影:\(x'=W^Tx\),然后使用KNN进行分类。
机器学习笔记簿 降维篇 LDA 01的更多相关文章
- 机器学习笔记簿 降维篇 PCA 01
降维是机器学习中十分重要的部分,降维就是通过一个特定的映射(可以是线性的或非线性的)将高维数据转换为低维数据,从而达到一些特定的效果,所以降维算法最重要的就是找到这一个映射.主成分分析(Princip ...
- iOS开发Swift篇(01) 变量&常量&元组
iOS开发Swift篇(01) 变量&常量&元组 说明: 1)终于要写一写swift了.其实早在14年就已经写了swift的部分博客,无奈时过境迁,此时早已不同往昔了.另外,对于14年 ...
- ML: 降维算法-LDA
判别分析(discriminant analysis)是一种分类技术.它通过一个已知类别的“训练样本”来建立判别准则,并通过预测变量来为未知类别的数据进行分类.判别分析的方法大体上有三类,即Fishe ...
- 机器学习常用算法(LDA,CNN,LR)原理简述
1.LDA LDA是一种三层贝叶斯模型,三层分别为:文档层.主题层和词层.该模型基于如下假设:1)整个文档集合中存在k个互相独立的主题:2)每一个主题是词上的多项分布:3)每一个文档由k个主题随机混合 ...
- Spark机器学习7·降维模型(scala&python)
PCA(主成分分析法,Principal Components Analysis) SVD(奇异值分解法,Singular Value Decomposition) http://vis-www.cs ...
- 量化投资学习笔记27——《Python机器学习应用》课程笔记01
北京理工大学在线课程: http://www.icourse163.org/course/BIT-1001872001 机器学习分类 监督学习 无监督学习 半监督学习 强化学习 深度学习 Scikit ...
- [机器学习 ]PCA降维--两种实现 : SVD或EVD. 强力总结. 在鸢尾花数据集(iris)实做
PCA降维--两种实现 : SVD或EVD. 强力总结. 在鸢尾花数据集(iris)实做 今天自己实现PCA,从网上看文章的时候,发现有的文章没有搞清楚把SVD(奇异值分解)实现和EVD(特征值分解) ...
- java多线程系类:基础篇:01基本概念:
这个系类的内容全部来源于http://www.cnblogs.com/skywang12345/p/3479024.html.特别在此声明!!! 本来想直接看那位作家的博客的,但还是复制过来. 多线程 ...
- Python机器学习(基础篇---监督学习(线性分类器))
监督学习经典模型 机器学习中的监督学习模型的任务重点在于,根据已有的经验知识对未知样本的目标/标记进行预测.根据目标预测变量的类型不同,我们把监督学习任务大体分为分类学习与回归预测两类.监督学习任务的 ...
随机推荐
- 编译运行Zookeeper源码
GitHub地址: https://github.com/apache/zookeeper 最新版本的 zookeeper 已经使用了 maven 进行管理了.不再需要安装 Ant 下载完成之后.使用 ...
- 服务消费者(Ribbon)
上一篇文章,简单概述了服务注册与发现,在微服务架构中,业务都会被拆分成一个独立的服务,服务之间的通讯是基于http restful的,Ribbon可以很好地控制HTTP和TCP客户端的行为,Sprin ...
- Sharepoint 编辑WebPart时,WebPart属性为灰色不可用
一般在客户端设置就是灰色的,解决方法就是,要在服务器上进行设置,就可以了.:)
- 每日一题 - 剑指 Offer 52. 两个链表的第一个公共节点
题目信息 时间: 2019-07-03 题目链接:Leetcode tag: 单链表 难易程度:简单 题目描述: 输入两个链表,找出它们的第一个公共节点. 示例: A: a1 -> a2 \ - ...
- 详解GaussDB bufferpool缓存策略,这次彻底懂了!
摘要:华为云GaussDB(for mysql)是华为云自主研发的最新一代云原生数据库,采用计算存储分离.日志即数据的架构设计.具备极致可靠.极致性价比.多为扩展.完全可信等诸多特性. 一 .Gaus ...
- BZOJ 2200 道路与航线(图论)
BZOJ 2200 道路与航线 题目大意 有两种路,一种没负数,一种没环,求单源最短路. solution 存在负边权Dij一定不能用嘛,显然不是 根据题意能看出来是tarjan,将双向边缩点,得到的 ...
- Docker-教你如何通过 Docker 快速搭建各种测试环境
今天给大家分享的主题是,如何通过 Docker 快速搭建各种测试环境,本文列举的,也是作者在工作中经常用到的,其中包括 MySQL.Redis.Elasticsearch.MongoDB 安装步骤,通 ...
- CSS3 实现复杂的背景图案
灵活的背景定位 实现效果: 将背景图定位到距离容器底边 10px 且距离右边 20px 的位置. background-position 方案 代码: <div>海盗密码</div& ...
- Pop!_OS下安装C++编程工具
Pop!_OS下C++编程 #0x0 Visual Studio Code #0x1 C++ 0x11 code::blocks #0x0 Visual Studio Code 下载安装vscode ...
- 数据可视化之powerBI技巧(十六)采悟:PowerBI作图技巧:动态显示可视化标题
默认情况下,PowerBI图表的标题是静态的,为了增强图表的可读性,通过设置动态标题,可快速展示关键信息.提升沟通效率.本文通过两个简单的例子来看看PowerBI中如何创建动态标题. /01/ 拿之前 ...