超千个节点OpenStack私有云案例(1):CERN 5000+ 计算节点私有云
CERN:欧洲核子研究组织
本文根据以下几篇文章整理而来:
- https://www.openstack.org/summit/tokyo-2015/videos/presentation/unveiling-cern-cloud-architecture
- https://www.mybookworld.info/view/lcl9u/cern-cloud-architecture-february-2016.html
- http://openstack-in-production.blogspot.com/
1. 系统
(1)系统规模
- 2015 年是 5000个计算节点,16000 个在运行的虚机
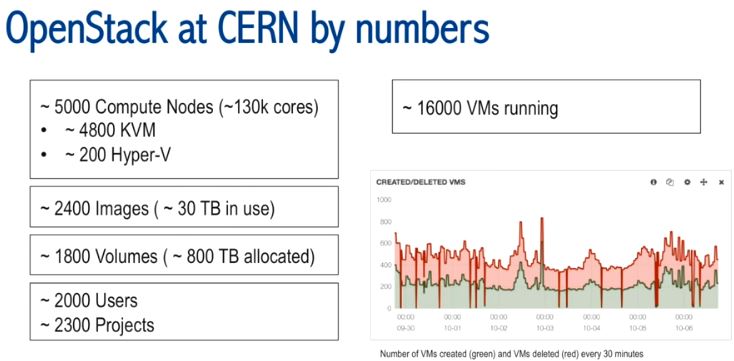
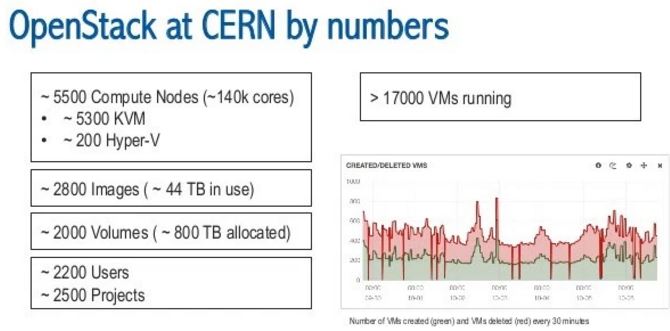
- 2016年2月是 5500 个计算节点,半年期间计算节点增加了 500 个,虚机增加了1000个
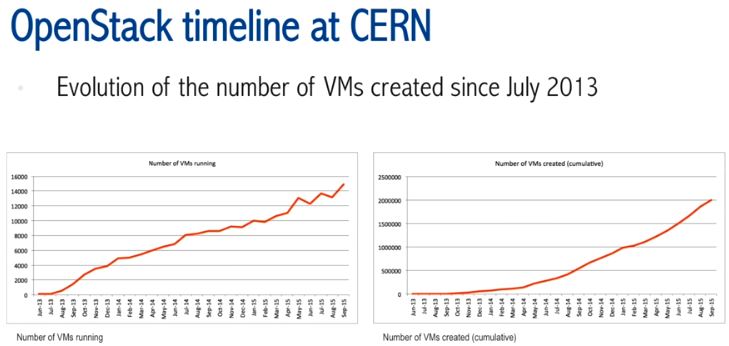
- 左边是当前正在运行的虚机的数量 16000 个,右边是被创建过的虚机的累计数量,超过 25 M。
(2)CERN 使用的 OpenStack 版本保持持续更新,基本上是延迟一个社区版本

(3)2015 年的总体结构:一个 region,2 个数据中心,26 个 Cell,全部使用 nova-network

在 2016 年2月,已经增长到了 33 个 Cell,而且在其中一个 Cell 中使用了 Neutron。
(4)Nova 系统架构
- 使用 nova-cell
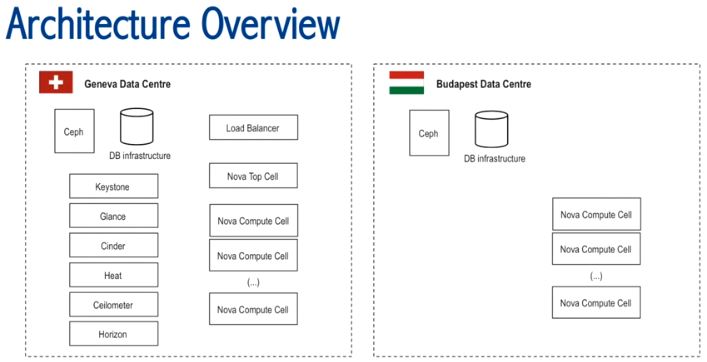
- 每个 Child Cell 有不同的 Use cases
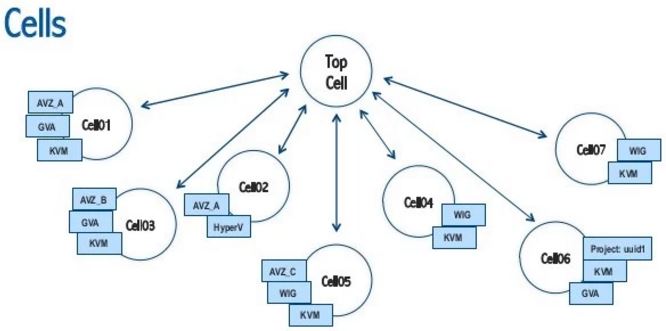
- 为什么要使用 Cell?因为不同的用户有不同的需求,因此,在每个 Child Cell 内部,可以使用不同的配置,包括 nova scheduler 等;Cell 还有助于缩小故障发生时候的影响域。

- Cell V1 的局限性

- Nova-cell 系统架构:两级 Cell 结构。只在 Nova Top Cell Controller 上使用 HA,在 Child Cell controller 上不使用HA。
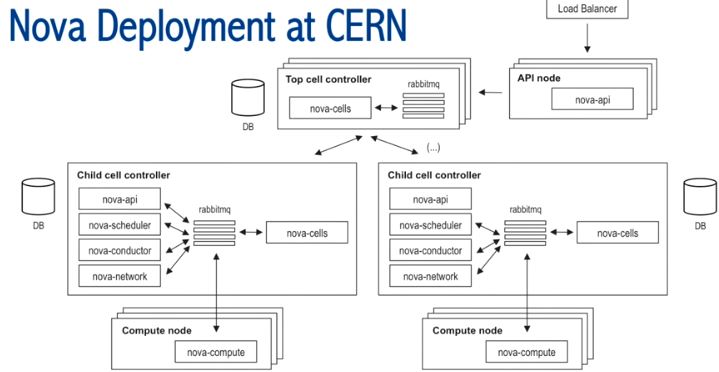
- 每个 Child Cell 大概 200 个计算节点

- CERN 自己开发了 Cell 调度器

- 如果将特定 project 的虚机调度到特定的 Child cell 上

- 如何结合 Cell 使用 AZ

- 在 2013 年的时候,只使用了一个 Cell,考虑到:(1)Nova Cell 的调度机制非常弱,只能随机调度,(2)想使用 host aggregate功能 (3)不能跨Cell 做 live migration。但是最后发现非常难于管理。

- 随后他们就将其拆分为 9 个 Child cell

- Nova 做 block live migration 遇到的问题

- Nova kilo 版本与 Python 2.6 不兼容

(5)网络架构
- CERN 使用基于 nova-network 的 网络分段技术

- CERN 自己开发了一个 Network driver

- 他们已经对 Neutron 做了大量的测试,已经在计划迁移(到2016年2月他们已经在一个Child cell 中使用 Neutron)

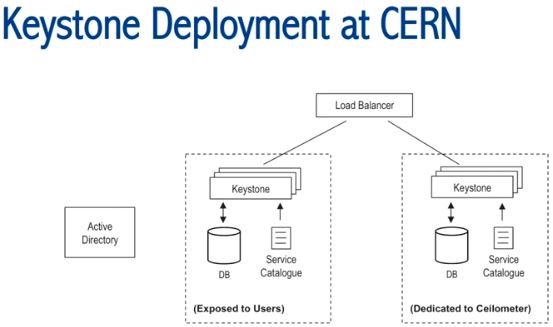
(6)Keystone
使用两个不同的 Keystone。Ceilometer 需要调用大量的 API,因此给它们一个专有的Keystone,免得影响用户使用 Keystone。

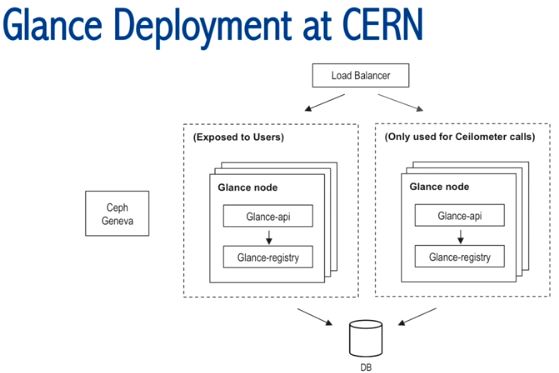
(7)Glance
Glance 服务运行在虚机中。之前,Glance registry 可以被别的 Glance API 使用,但是,这导致难于定位问题,因此,现在的 Glance registry 只和本地的 Glance API 通信。但是,Glance 不支持分 Project 设置 Quota,这对他们很重要。

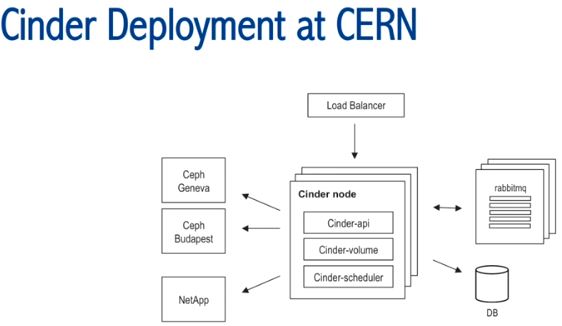
(8)Cinder
使用了 3个 backend,两个 Ceph,一个 NetApp。目前没有 Ceph Cinder driver for hyper-v,所以他们使用了 NetApp,被 Hyper-V 虚机使用。

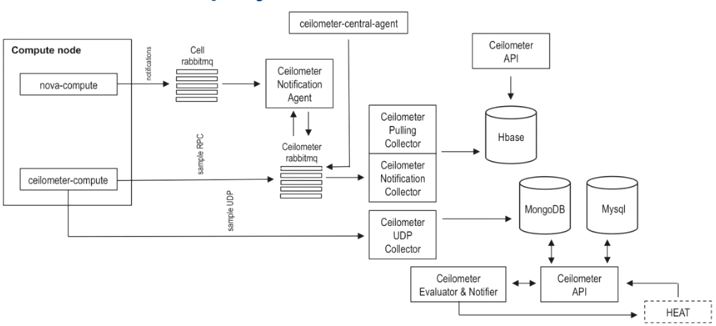
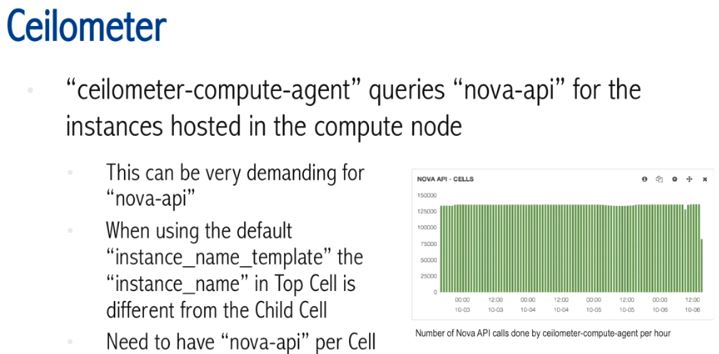
(9)Ceilometer

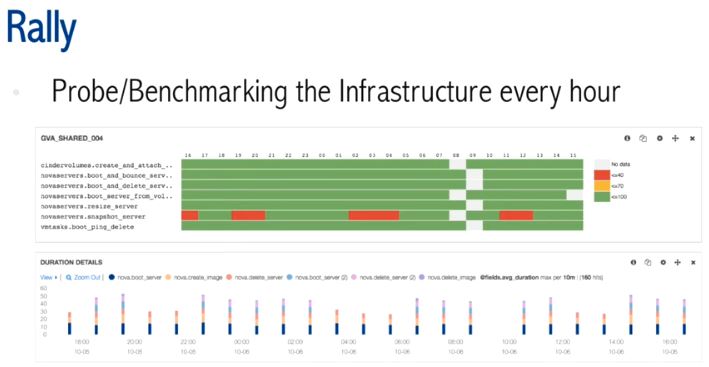
(10)Rally
不仅用于 benchmarking 测试,还用于 FVT。
(11)新的挑战

2. 简单分析
2.1 CERN 对 Nova Cell 的看法
对大规模的部署,Nova Cell 有几个优势:
- 能够保持对用户只有单端点可见(single endpoint to users)
- 能够增加基础架构的可用性和弹性(increase the availability and resilience of the Infrastructure)
- 能够避免超出 Nova 和其它外部模块(比如 DB,MQ 等)的上限 (avoid that Nova and external components (DBs, message brokers) reach their limits)
- 能够隔离不同用户 (isolate different user cases)
但是,Cell 目前还是有不少的局限,如下的功能不能和 Nova Cell 一起使用:
- Security Groups;
- Manage aggregates on Top Cell;
- Availability Zone support;
- Server groups;
- Cell scheduler limited functionality;
2.2 本人的一点看法
- 使用现有的 OpenStack 来支持 5000 个计算节点,那是非常牛的事情!这可能是目前最大的 OpenStack 生产系统私有云部署规模。
- 计算扩展性方面,使用 Nova cell 是一个解决方案,但是目前它的 V1 版本已经被冻结,V2 还在开发中,因此,要使用的话,需要做大量的开发和问题定位;而且,它还存在大量的局限性。
- 网络扩展性方面,Neutron 的扩展性和稳定性依然问题很大,CERN 也在一步步尝试,期待他们使用 Neutron 的心得
- 存储扩展性方面,Ceph 居然能做到支撑 30PB 的数据量,这也是非常非常牛的事情!
- Ceilometer 扩展性方面,以及性能和开销等方面,默认情况下依然问题很大,CERN 做出了改进的非常好的示范
- 谢谢 CERN 团队的超强工作和无私分享
超千个节点OpenStack私有云案例(1):CERN 5000+ 计算节点私有云的更多相关文章
- 政务私有云盘系统建设的工具 – Mobox私有云盘
序言 这几年,智慧政务已经成为了政府行业IT建设发展的重要进程.传统办公方式信息传递速度慢.共享程度低.查询利用难,早已成为政府机关获取和利用信息的严重制约因素.建立文档分享共用机制,加强数据整合,避 ...
- 四种方案:将OpenStack私有云部署到Hadoop MapReduce环境中
摘要:OpenStack与Hadoop被誉为继Linux之后最有可能获得巨大成功的开源项目.这二者如何结合成为更猛的新方案?业内给出两种答案:Hadoop跑在OpenStack上或OpenStack部 ...
- CentOS7安装OpenStack(Rocky版)-05.安装一个nova计算节点实例
上一篇文章分享了控制节点的nova计算服务的安装方法,在实际生产环境中,计算节点通常会安装一些单独的节点提供服务,本文分享单独的nova计算节点的安装方法 ---------------- 完美的分 ...
- openstack Q版部署-----nova服务配置-计算节点(6)
一.服务安装(计算节点) 安装软件: yum install openstack-nova-compute -y 编辑/etc/nova/nova.conf文件并设置如下内容: [DEFAULT] e ...
- S1_搭建分布式OpenStack集群_07 nova服务配置 (计算节点)
一.服务安装(计算节点)安装软件:# yum install openstack-nova-compute -y 编辑/etc/nova/nova.conf文件并设置如下内容:# vim /etc/n ...
- openstack私有云布署实践【13.2 网络Neutron-compute节点配置(办公网环境)】
所有compute节点 下载安装组件 # yum install openstack-neutron openstack-neutron-linuxbridge ebtables ipset -y ...
- openstack私有云布署实践【13.1 网络Neutron-compute节点配置(科兴环境)】
所有kxcompute节点 下载安装组件 # yum install openstack-neutron openstack-neutron-linuxbridge ebtables ipset ...
- openstack私有云布署实践【12.2 网络Neutron-controller节点配置(办公网环境)】
网络这一块推荐使用的是 Neutron--LinuxBirdge的Ha高可用,此高可用方案对Public作用不是很大,Public只用到DHCP,而Private则会用到L3 Agent,则此方案是有 ...
- openstack私有云布署实践【12.1 网络Neutron-controller节点配置(科兴环境)】
网络这一块推荐使用的是 Neutron--LinuxBirdge的Ha高可用,此高可用方案对Public作用不是很大,Public只用到DHCP,而Private则会用到L3 Agent,则此方案是有 ...
随机推荐
- 总结:Mac前端开发环境的搭建(配置)
新年新气象,在2016年的第一天,我入手了人生中第一台自己的电脑(大一时好友赠送的电脑在一次无意中烧坏了主板,此后便不断借用别人的或者网站的).macbook air,身上已无分文...接下来半年的房 ...
- java中servlet的各种路径
1. web.xml中<url-pattern>路径,(叫它Servlet路径!) > 要么以“*”开关,要么为“/”开头 2. 转发和包含路径 > *****以“/”开头:相 ...
- redux学习
redux学习: 1.应用只有一个store,用于保存整个应用的所有的状态数据信息,即state,一个state对应一个页面的所需信息 注意:他只负责保存state,接收action, 从store. ...
- [C#] 简单的 Helper 封装 -- SQLiteHelper
using System; using System.Data; using System.Data.SQLite; namespace SqliteConsoleApp { /// <summ ...
- Windows 常用运行库下载 (DirectX、VC++、.Net Framework等)
经常听到有朋友抱怨他的电脑运行软件或者游戏时提示缺少什么 d3dx9_xx.dll 或 msvcp71.dll.msvcr71.dll又或者是 .Net Framework 初始化之类的错误而无法正常 ...
- node中的Stream-Readable和Writeable解读
在node中,只要涉及到文件IO的场景一般都会涉及到一个类-Stream.Stream是对IO设备的抽象表示,其在JAVA中也有涉及,主要体现在四个类-InputStream.Reader.Outpu ...
- myeclipse 内存不够用报错PermGen space 和 An internal error has occurred.
最近项目中又增加了新的模块,项目的代码又多了不少.运行的时候总是报如下错误 Exception in thread "http-apr-80-exec-6" java.lang.O ...
- Register-SPWorkflowService 404
最近需要做一个SharePoint 2013工作流演示环境. 于是在自己的本子上安装了一个虚拟机. 虚拟机操作系统是Windows Server 2012 R2,计划把AD.SQL Server 20 ...
- 【一起学OpenFOAM】03 OpenFOAM基本使用流程
OpenFOAM初学者常常对于软件的使用流程感到很迷惑,与其他的具有GUI的CFD软件不同,OpenFOAM的所有操作均为基于文本操作,譬如说里面各种计算模型.计算参数.流程控制参数等,均为通过修改对 ...
- Storm
2016-11-14 22:05:29 有哪些典型的Storm应用案例? 数据处理流:Storm可以用来处理源源不断流进来的消息,处理之后将结果写入到某个存储中去.不像其它的流处理系统,Storm不 ...