强化学习、分布式计算方向的phd毕业后去企业的要求
实验室慕师弟马上要phd毕业了,虽然我是遥遥无期,但是看到身边同学可以上岸还是提师弟高兴。由于师弟准备去企业工作,于是乎我也不免好奇起来phd毕业后去公司会有什么样的要求,于是网上找了找招聘信息,挑了几个不错的招聘岗位,这里mark下。
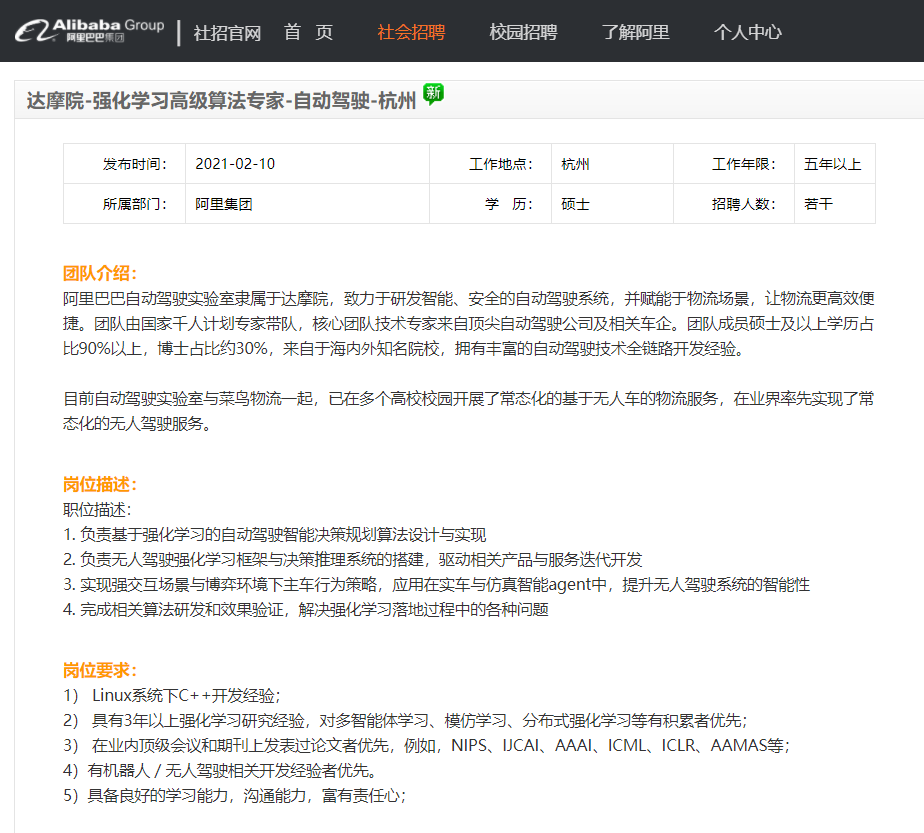
1. 强化学习方向的(自动驾驶)
虽然要求硕士学历就可以,不过看到其中的顶会论文要求便知道这个岗位也是不容易get到的。
https://job.alibaba.com/zhaopin/PositionDetail.htm?positionCode=GP705939
======================================================
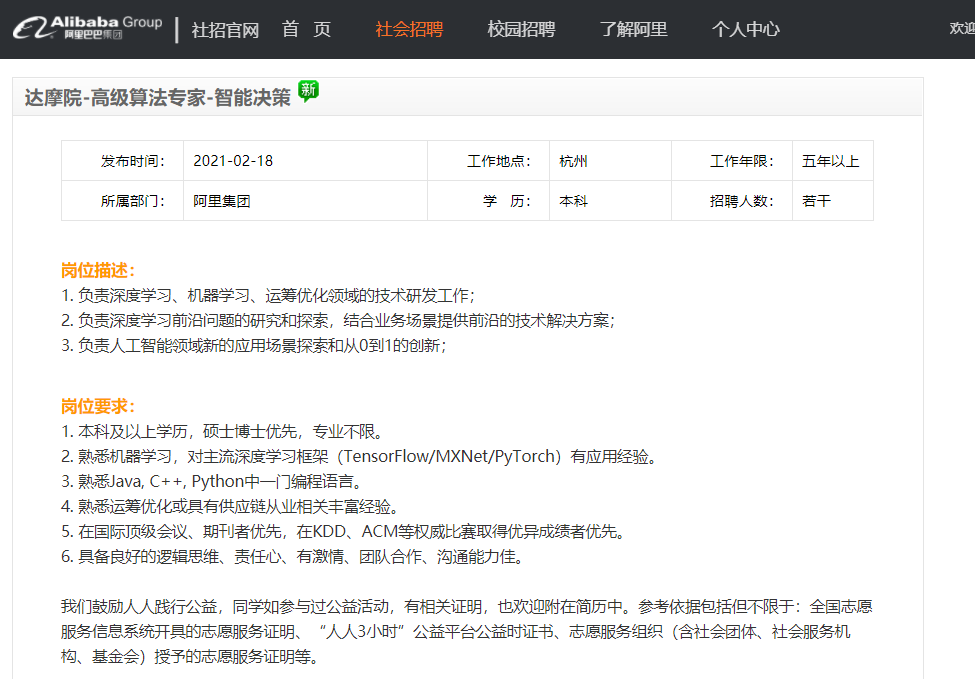
2. 智能决策方向
要求论文或比赛经历,要求比第一个貌似低些。
https://job.alibaba.com/zhaopin/PositionDetail.htm?positionCode=GP635511
=============================================
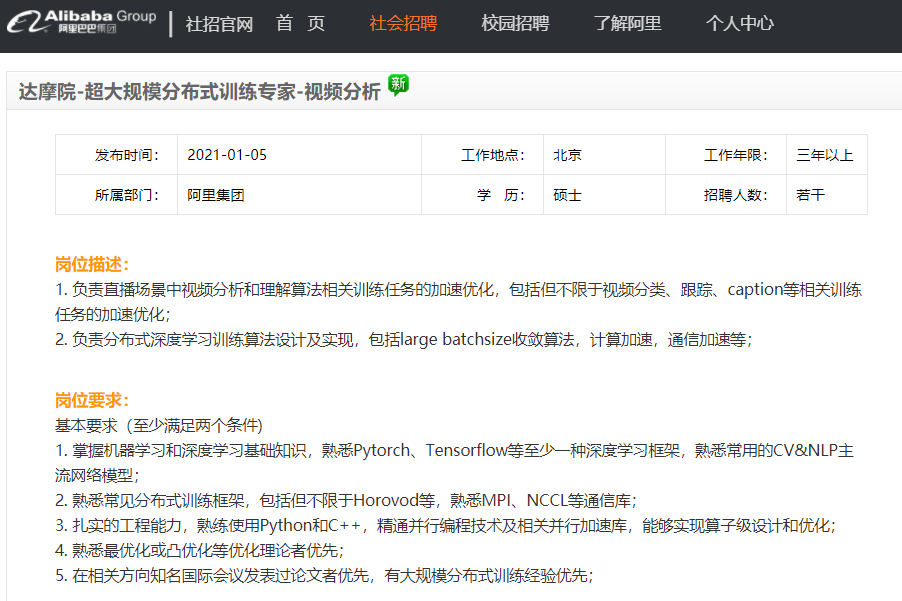
3. 分布式人工智能算法工程师
在对论文等有要求外还希望有较好的相关编程经验(分布式:MPI,NCCL等)
https://job.alibaba.com/zhaopin/PositionDetail.htm?positionCode=GP630418
============================================
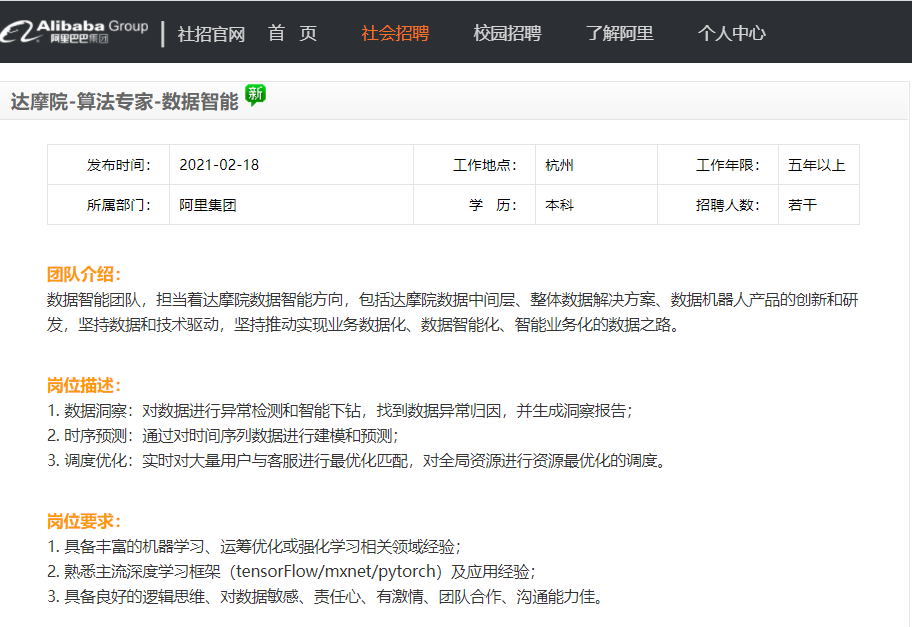
4. 数据智能
要求较低。
https://job.alibaba.com/zhaopin/PositionDetail.htm?positionCode=GP626894
===============================================
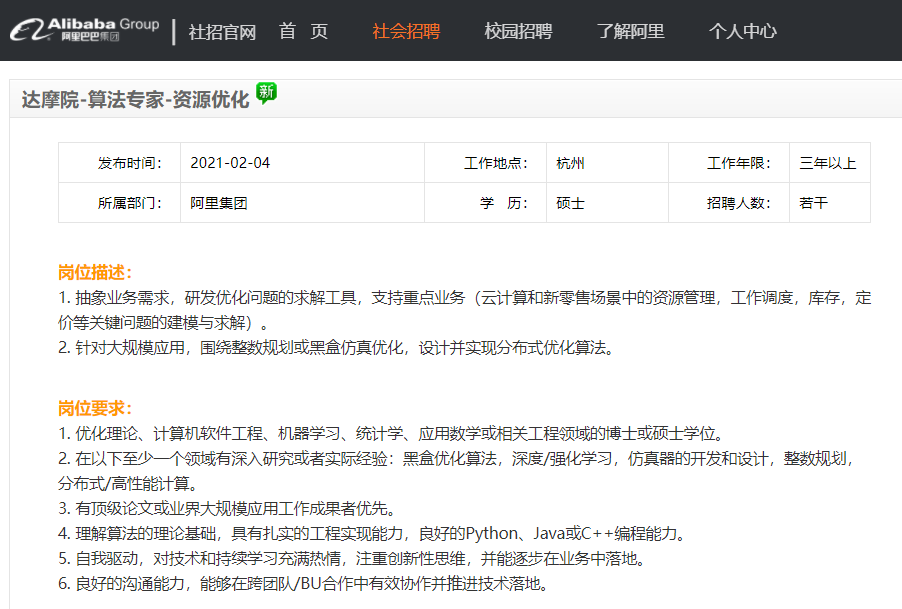
5. 资源优化( 算法工程师 )
https://job.alibaba.com/zhaopin/PositionDetail.htm?positionCode=GP634344
==============================================
强化学习、分布式计算方向的phd毕业后去企业的要求的更多相关文章
- 强化学习 1 --- 马尔科夫决策过程详解(MDP)
强化学习 --- 马尔科夫决策过程(MDP) 1.强化学习介绍 强化学习任务通常使用马尔可夫决策过程(Markov Decision Process,简称MDP)来描述,具体而言:机器处在一个环境 ...
- 强化学习(二)马尔科夫决策过程(MDP)
在强化学习(一)模型基础中,我们讲到了强化学习模型的8个基本要素.但是仅凭这些要素还是无法使用强化学习来帮助我们解决问题的, 在讲到模型训练前,模型的简化也很重要,这一篇主要就是讲如何利用马尔科夫决策 ...
- 强化学习 CartPole实验的一些启发 有没有可能设计一个新的实验呢?(杆子可以向360度方向倾倒,可行吗?)
最近在看强化学习方面的东西,突然想到了这么一个事情,那就是经典的CartPole游戏我们改变一下,或者说升级一下,那么使用强化学习是否能得到不错的效果呢? 原始游戏如图: 一点个人的想法: ===== ...
- 【整理】强化学习与MDP
[入门,来自wiki] 强化学习是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益.其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的 ...
- 强化学习读书笔记 - 02 - 多臂老O虎O机问题
# 强化学习读书笔记 - 02 - 多臂老O虎O机问题 学习笔记: [Reinforcement Learning: An Introduction, Richard S. Sutton and An ...
- 强化学习 - Q-learning Sarsa 和 DQN 的理解
本文用于基本入门理解. 强化学习的基本理论 : R, S, A 这些就不说了. 先设想两个场景: 一. 1个 5x5 的 格子图, 里面有一个目标点, 2个死亡点二. 一个迷宫, 一个出发点, ...
- 强化学习(十三) 策略梯度(Policy Gradient)
在前面讲到的DQN系列强化学习算法中,我们主要对价值函数进行了近似表示,基于价值来学习.这种Value Based强化学习方法在很多领域都得到比较好的应用,但是Value Based强化学习方法也有很 ...
- 强化学习(八)价值函数的近似表示与Deep Q-Learning
在强化学习系列的前七篇里,我们主要讨论的都是规模比较小的强化学习问题求解算法.今天开始我们步入深度强化学习.这一篇关注于价值函数的近似表示和Deep Q-Learning算法. Deep Q-Lear ...
- 强化学习(六)时序差分在线控制算法SARSA
在强化学习(五)用时序差分法(TD)求解中,我们讨论了用时序差分来求解强化学习预测问题的方法,但是对控制算法的求解过程没有深入,本文我们就对时序差分的在线控制算法SARSA做详细的讨论. SARSA这 ...
- 强化学习(三)用动态规划(DP)求解
在强化学习(二)马尔科夫决策过程(MDP)中,我们讨论了用马尔科夫假设来简化强化学习模型的复杂度,这一篇我们在马尔科夫假设和贝尔曼方程的基础上讨论使用动态规划(Dynamic Programming, ...
随机推荐
- SQL SERVER 2012的安装
1.将光盘镜像用虚拟光驱加载(WIN10自带虚拟光驱) 2.双击setup.exe 3.选择"安装"-"全新 SQL Server 独立安装或向现有安装添加功能" ...
- 夜莺监控(Nightingale)上线内置指标功能
Prometheus 生态里如果要查询数据,需要编写 promql,对于普通用户来说,门槛有点高.通常有两种解法,一个是通过 AI 的手段做翻译,你用大白话跟 AI 提出你的诉求,让 AI 帮你写 p ...
- Chapter1 p2 vec
在上一小节中,我们完成了对BMPImage类的构建,成功实现了我们这个小小引擎的图像输出功能. 你已经完成了图像输出了,接着就开始路径追踪吧... 开个玩笑XD 对于曾经学习过一些图形学经典教材的人来 ...
- Spring扩展———自定义bean组件注解
引言 Java 注解(Annotation)又称 Java 标注,是 JDK5.0 引入的一种注释机制. Java 语言中的类.方法.变量.参数和包等都可以被标注.和 Javadoc 不同,Java ...
- llm-universe - 1
Smiling & Weeping ---- 难怪春迟迟不来,原来是我把雪一读再读 一.大型语言模型(LLM)理论简介 1 大型语言模型(LLM)的概念 大语言模型(LLM,Large Lan ...
- onreadystatechange 属性
onreadystatechange 属性是 XMLHttpRequest 对象的一个事件处理器,用于在 XMLHttpRequest 对象的 readyState 属性发生变化时触发.这个属性通常用 ...
- 《Node.js+Vue.js+MangoDB全栈开发实战》已出版
<Node.js+Vue.js+MangoDB全栈开发实战> 图书购买地址: 京东:<Node.js+Vue.js+MangoDB全栈开发实战> 当当:<Node.js+ ...
- Android 7 默认声音/大小修改
背景 客户机器默认的开机声音一直很大:客户觉得无法接受,需要改小点. 基于Android 7的代码 前言 一般主要通过系统层来进行修改. 在系统关于音频的有关代码中,定义了两个数组: 注意,这些代码根 ...
- 基于MCU的SD卡fat文件系统读写移植
背景 https://blog.csdn.net/huang20083200056/article/details/78508490 SD卡(Secure Digital Memory Card)具有 ...
- Springboot整合Apollo
一.Apollo作用 随着程序功能的日益复杂,程序的配置日益增多:各种功能的开关.参数的配置.服务器的地址-- 对程序配置的期望值也越来越高:配置修改后实时生效,灰度发布,分环境.分集群管理配置,完善 ...