莫烦tensorflow学习记录 (2)激励函数Activation Function
https://mofanpy.com/tutorials/machine-learning/tensorflow/intro-activation-function/
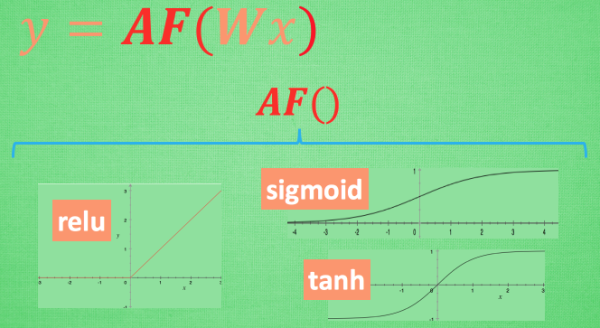
这里的 AF 就是指的激励函数. 激励函数拿出自己最擅长的”掰弯利器”, 套在了原函数上 用力一扭, 原来的 Wx 结果就被扭弯了.
其实这个 AF, 就是一个非线性函数. 比如说relu, sigmoid, tanh. 嵌套在原有的结果之上, 强行把原有的线性结果给扭曲了. 使得输出结果 y 也有了非线性的特征.
可以创造自己的激励函数来处理自己的问题,只要激励函数是可以微分的, 因为在 backpropagation 误差反向传递的时候, 只有这些可微分的激励函数才能把误差传递回去.
想要恰当使用这些激励函数, 还是有窍门的. 比如当你的神经网络层只有两三层, 不是很多的时候, 对于隐藏层, 使用任意的激励函数, 随便掰弯是可以的, 不会有特别大的影响. 不过, 当你使用特别多层的神经网络, 在掰弯的时候, 往往不得随意选择利器. 因为这会涉及到梯度爆炸, 梯度消失的问题.
在具体的例子中, 我们默认首选的激励函数是哪些. 在少量层结构中, 我们可以尝试很多种不同的激励函数. 在卷积神经网络的卷积层中, 推荐的激励函数是 relu. 在循环神经网络中推荐的是 tanh 或者是 relu。
常用激励函数
def sigmoid(x):
return 1 / (1 + np.exp(-x)) def sigmoid_grad(x):
return (1.0 - sigmoid(x)) * sigmoid(x) def relu(x):
return np.maximum(0, x) def relu_grad(x):
grad = np.zeros(x)
grad[x>=0] = 1
return grad def softmax(x):
if x.ndim == 2:
x = x.T
x = x - np.max(x, axis=0)
y = np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T x = x - np.max(x) # 溢出对策
return np.exp(x) / np.sum(np.exp(x))
莫烦tensorflow学习记录 (2)激励函数Activation Function的更多相关文章
- 莫烦PyTorch学习笔记(三)——激励函数
1. sigmod函数 函数公式和图表如下图 在sigmod函数中我们可以看到,其输出是在(0,1)这个开区间内,这点很有意思,可以联想到概率,但是严格意义上讲,不要当成概率.sigmod函数 ...
- 莫烦pytorch学习笔记(八)——卷积神经网络(手写数字识别实现)
莫烦视频网址 这个代码实现了预测和可视化 import os # third-party library import torch import torch.nn as nn import torch ...
- 莫烦pytorch学习笔记(七)——Optimizer优化器
各种优化器的比较 莫烦的对各种优化通俗理解的视频 import torch import torch.utils.data as Data import torch.nn.functional as ...
- 莫烦 - Pytorch学习笔记 [ 一 ]
1. Numpy VS Torch #相互转换 np_data = torch_data.numpy() torch_data = torch.from_numpy(np_data) #abs dat ...
- 莫烦PyTorch学习笔记(五)——模型的存取
import torch from torch.autograd import Variable import matplotlib.pyplot as plt torch.manual_seed() ...
- 莫烦theano学习自修第八天【分类问题】
1. 代码实现 from __future__ import print_function import numpy as np import theano import theano.tensor ...
- ML 激励函数 Activation Function (整理)
本文为内容整理,原文请看url链接,感谢几位博主知识来源 一.什么是激励函数 激励函数一般用于神经网络的层与层之间,上一层的输出通过激励函数的转换之后输入到下一层中.神经网络模型是非线性的,如果没有使 ...
- 莫烦theano学习自修第四天【激励函数】
1. 定义 激励函数通常用于隐藏层,是将特征值进行过滤或者激活的算法 2.常见的激励函数 1. sigmoid (1)sigmoid() (2)ultra_fast_sigmoid() (3)hard ...
- 莫烦theano学习自修第二天【激励函数】
1. 代码如下: #!/usr/bin/env python #! _*_ coding:UTF-8 _*_ import numpy as np import theano.tensor as T ...
- 莫烦keras学习自修第四天【分类问题】
1.代码实战 #!/usr/bin/env python #! _*_ coding:UTF-8 _*_ # 导入numpy import numpy as np np.random.seed(133 ...
随机推荐
- Godot UI线程,Task异步和消息弹窗通知
目录 前言 线程安全 全局消息IOC注入 消息窗口搭建 最简单的消息提示 简单使用 仿Element UI ElementUI 效果 简单的Label样式 如何快速加载多个相同节点 修改一下,IOC按 ...
- 安装 php_mongodb.dll的坑
背景 php_mongodb.dll在这里介绍的是for php,php_mongodb.dll是这个坑,因为php_mongodb.dll前生是php_mongo.dll,而这个东西,它又不更新了, ...
- 【cef编译包】下载地址
http://opensource.spotify.com/cefbuilds/index.html
- 特殊border的样式 -- CSS3实现三种切角效果
效果一: 代码:<div class="cornerCut">corner cutcorner cutcorner cutcorner cut</div> ...
- css添加属性,让浏览器检查无法选中元素
1.表现 浏览器直接选中元素的时候,仅能直接选中整个body,想要找到具体元素,需要自己手动寻找,没太大实际作用,仅仅让不懂的人不能简简单单的直接定位元素然后修改里面的内容 pointer-event ...
- Oracle with的重复使用(递归)
Oracle with的重复使用(递归) 写力扣的时候学到了新的方法 Recursive WITH Clauses 通常来说如果直接使用with XXX as ()这种,是没发直接使用自身的数据的 例 ...
- 报错ORA-01830: date format picture ends before converting entire input string
报错ORA-01830: date format picture ends before converting entire input string 原语句 select to_char(to_da ...
- 力扣184(MySQL)-部门工资最高的员工(中等)
题目: 表: Employee 表: Department 编写SQL查询以查找每个部门中薪资最高的员工.按 任意顺序 返回结果表.查询结果格式如下例所示. 解题思路: 方法一:窗口函数和多表联结 ...
- 力扣594(java&python)-最长和谐子序列(简单)
题目: 和谐数组是指一个数组里元素的最大值和最小值之间的差别 正好是 1 . 现在,给你一个整数数组 nums ,请你在所有可能的子序列中找到最长的和谐子序列的长度. 数组的子序列是一个由数组派生出来 ...
- 力扣647(java)-回文子串(中等)
题目: 给你一个字符串 s ,请你统计并返回这个字符串中 回文子串 的数目. 回文字符串 是正着读和倒过来读一样的字符串. 子字符串 是字符串中的由连续字符组成的一个序列. 具有不同开始位置或结束位置 ...