神经网络优化篇:为什么正则化有利于预防过拟合呢?(Why regularization reduces overfitting?)
为什么正则化有利于预防过拟合呢?
通过两个例子来直观体会一下。
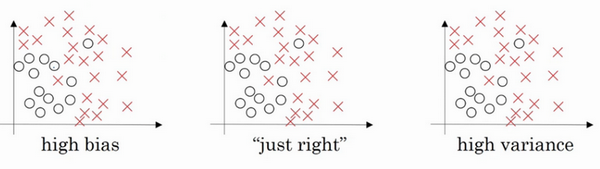
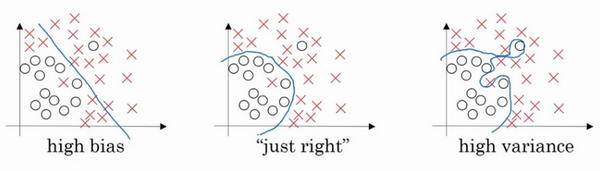
左图是高偏差,右图是高方差,中间是Just Right。
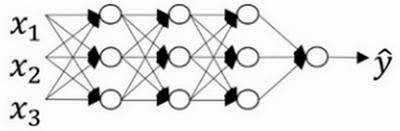
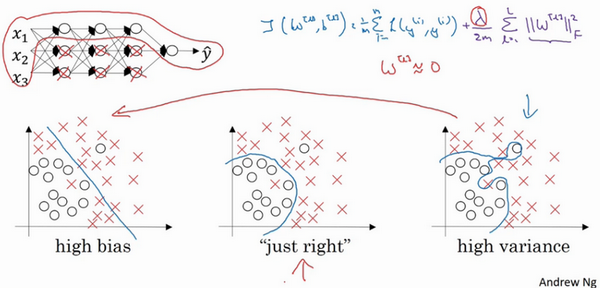
现在来看下这个庞大的深度拟合神经网络。知道这张图不够大,深度也不够,但可以想象这是一个过拟合的神经网络。这是的代价函数\(J\),含有参数\(W\),\(b\)。添加正则项,它可以避免数据权值矩阵过大,这就是弗罗贝尼乌斯范数,为什么压缩\(L2\)范数,或者弗罗贝尼乌斯范数或者参数可以减少过拟合?
直观上理解就是如果正则化\(\lambda\)设置得足够大,权重矩阵\(W\)被设置为接近于0的值,直观理解就是把多隐藏单元的权重设为0,于是基本上消除了这些隐藏单元的许多影响。如果是这种情况,这个被大大简化了的神经网络会变成一个很小的网络,小到如同一个逻辑回归单元,可是深度却很大,它会使这个网络从过度拟合的状态更接近左图的高偏差状态。
但是\(\lambda\)会存在一个中间值,于是会有一个接近“Just Right”的中间状态。
直观理解就是\(\lambda\)增加到足够大,\(W\)会接近于0,实际上是不会发生这种情况的,尝试消除或至少减少许多隐藏单元的影响,最终这个网络会变得更简单,这个神经网络越来越接近逻辑回归,直觉上认为大量隐藏单元被完全消除了,其实不然,实际上是该神经网络的所有隐藏单元依然存在,但是它们的影响变得更小了。神经网络变得更简单了,貌似这样更不容易发生过拟合,因此不确定这个直觉经验是否有用,不过在编程中执行正则化时,实际看到一些方差减少的结果。
再来直观感受一下,正则化为什么可以预防过拟合,假设用的是这样的双曲线激活函数。

用\(g(z)\)表示\(tanh(z)\),发现如果 z 非常小,比如 z 只涉及很小范围的参数(图中原点附近的红色区域),这里利用了双曲正切函数的线性状态,只要\(z\)可以扩展为这样的更大值或者更小值,激活函数开始变得非线性。
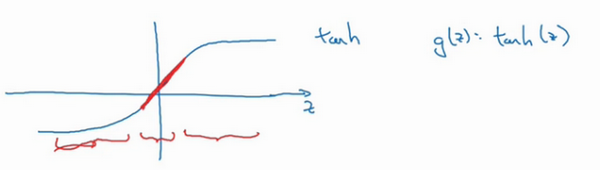
现在应该摒弃这个直觉,如果正则化参数λ很大,激活函数的参数会相对较小,因为代价函数中的参数变大了,如果\(W\)很小,
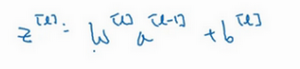
如果\(W\)很小,相对来说,\(z\)也会很小。
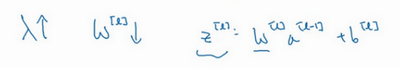
特别是,如果\(z\)的值最终在这个范围内,都是相对较小的值,\(g(z)\)大致呈线性,每层几乎都是线性的,和线性回归函数一样。

如果每层都是线性的,那么整个网络就是一个线性网络,即使是一个非常深的深层网络,因具有线性激活函数的特征,最终只能计算线性函数,因此,它不适用于非常复杂的决策,以及过度拟合数据集的非线性决策边界。
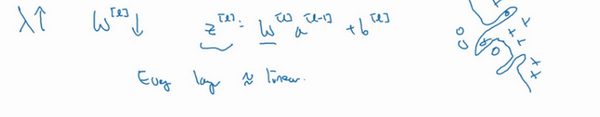
总结一下,如果正则化参数变得很大,参数\(W\)很小,\(z\)也会相对变小,此时忽略\(b\)的影响,\(z\)会相对变小,实际上,\(z\)的取值范围很小,这个激活函数,也就是曲线函数\(tanh\)会相对呈线性,整个神经网络会计算离线性函数近的值,这个线性函数非常简单,并不是一个极复杂的高度非线性函数,不会发生过拟合。
大家在编程作业里实现正则化的时候,会亲眼看到这些结果,总结正则化之前,给大家一个执行方面的小建议,在增加正则化项时,应用之前定义的代价函数\(J\),做过修改,增加了一项,目的是预防权重过大。
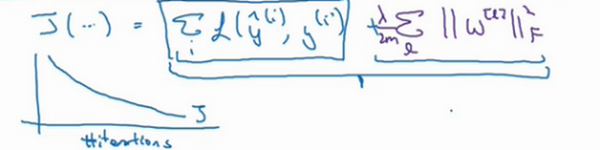
如果使用的是梯度下降函数,在调试梯度下降时,其中一步就是把代价函数\(J\)设计成这样一个函数,在调试梯度下降时,它代表梯度下降的调幅数量。可以看到,代价函数对于梯度下降的每个调幅都单调递减。如果实施的是正则化函数,请牢记,\(J\)已经有一个全新的定义。如果用的是原函数\(J\),也就是这第一个项正则化项,可能看不到单调递减现象,为了调试梯度下降,请务必使用新定义的\(J\)函数,它包含第二个正则化项,否则函数\(J\)可能不会在所有调幅范围内都单调递减。
这就是\(L2\)正则化,它是在训练深度学习模型时最常用的一种方法。
神经网络优化篇:为什么正则化有利于预防过拟合呢?(Why regularization reduces overfitting?)的更多相关文章
- Tensorflow学习:(三)神经网络优化
一.完善常用概念和细节 1.神经元模型: 之前的神经元结构都采用线上的权重w直接乘以输入数据x,用数学表达式即,但这样的结构不够完善. 完善的结构需要加上偏置,并加上激励函数.用数学公式表示为:.其中 ...
- 【零基础】神经网络优化之Adam
一.序言 Adam是神经网络优化的另一种方法,有点类似上一篇中的“动量梯度下降”,实际上是先提出了RMSprop(类似动量梯度下降的优化算法),而后结合RMSprop和动量梯度下降整出了Adam,所以 ...
- zz图像、神经网络优化利器:了解Halide
动图示例实在太好 图像.神经网络优化利器:了解Halide Oldpan 2019年4月17日 0条评论 1,327次阅读 3人点赞 前言 Halide是用C++作为宿主语言的一个图像处理相 ...
- 神经网络优化算法:梯度下降法、Momentum、RMSprop和Adam
最近回顾神经网络的知识,简单做一些整理,归档一下神经网络优化算法的知识.关于神经网络的优化,吴恩达的深度学习课程讲解得非常通俗易懂,有需要的可以去学习一下,本人只是对课程知识点做一个总结.吴恩达的深度 ...
- Halide视觉神经网络优化
Halide视觉神经网络优化 概述 Halide是用C++作为宿主语言的一个图像处理相关的DSL(Domain Specified Language)语言,全称领域专用语言.主要的作用为在软硬层面上( ...
- 训练/验证/测试集设置;偏差/方差;high bias/variance;正则化;为什么正则化可以减小过拟合
1. 训练.验证.测试集 对于一个需要解决的问题的样本数据,在建立模型的过程中,我们会将问题的data划分为以下几个部分: 训练集(train set):用训练集对算法或模型进行训练过程: 验证集(d ...
- 神经网络优化算法:Dropout、梯度消失/爆炸、Adam优化算法,一篇就够了!
1. 训练误差和泛化误差 机器学习模型在训练数据集和测试数据集上的表现.如果你改变过实验中的模型结构或者超参数,你也许发现了:当模型在训练数据集上更准确时,它在测试数据集上却不⼀定更准确.这是为什么呢 ...
- tensorflow(3):神经网络优化(ema,regularization)
1.指数滑动平均 (ema) 描述滑动平均: with tf.control_dependencies([train_step,ema_op]) 将计算滑动平均与 训练过程绑在一起运行 train_o ...
- APP网络优化篇
Android Addresses are cached for 600 seconds (10 minutes) by default. Failed lookups are cached for ...
- 神经网络优化算法如何选择Adam,SGD
之前在tensorflow上和caffe上都折腾过CNN用来做视频处理,在学习tensorflow例子的时候代码里面给的优化方案默认很多情况下都是直接用的AdamOptimizer优化算法,如下: o ...
随机推荐
- 《Python魔法大冒险》008 石像怪的挑战:运算符之旅
小鱼和魔法师继续深入魔法森林.不久,他们来到了一个巨大的魔法石圈旁边.石圈中心有一个闪闪发光的魔法水晶,周围则是一些神秘的符号.但令人意外的是,水晶的旁边还有一个巨大的石像怪,它的眼睛散发着红色的光芒 ...
- react移动端上拉加载更多组件
在开发移动端react项目中,遇到了上拉加载更多数据的分页功能,自己封装了一个组件,供大家参考,写的不好还请多多指教! import React, {Component} from 'react'; ...
- 部分网页中仅供浏览的pdf文件下载方法
现在越来越多的网站提供的PDF资料只能在线浏览,不提供下载功能,实际上仅仅是通过网页PDF浏览插件来访问文件资源,如果能够获取到该文件的访问地址,就可以访问下载. 以Firefox浏览器访问某大学网站 ...
- Journey -「CQOI 2021」
Day -1 Thu. & Fri. 恰逢学校运动会,于是向班主任申请了不去,然后就在机房坐着.不美好的事情可能就是文化课老师还留了这两天的作业,不过-> 一旦放弃了作业,什么都好说了呢 ...
- MPI转以太网Plus模块Modbus连接两台变频器通信案例
MPI转以太网Plus模块Modbus主站连接两台变频器通信案例 MPI转以太网Plus模块连接200PLC无需编程实现Modbus主从站功能与2台变频器modbus通信:以下就是MPI转以太网模块作 ...
- Mac上虚拟环境的安装与使用
Mac上虚拟环境的安装与使用 介绍 virtualenv是python虚拟环境,能够和系统环境相隔离,保持环境的纯净. virtualenvwrapper可以方便管理虚拟环境 安装 pip insta ...
- 我封装的一个REPR轮子 Biwen.QuickApi
Biwen.QuickApi 项目介绍 [QuickApi("hello/world")] public class MyApi : BaseQuickApi<Req,Rsp ...
- 基于SpringBoot+Netty实现即时通讯(IM)功能
简单记录一下实现的整体框架,具体细节在实际生产中再细化就可以了. 第一步 引入netty依赖 SpringBoot的其他必要的依赖像Mybatis.Lombok这些都是老生常谈了 就不在这里放了 &l ...
- 自定义MyBatis拦截器更改表名
by emanjusaka from https://www.emanjusaka.top/archives/10 彼岸花开可奈何 本文欢迎分享与聚合,全文转载请留下原文地址. 自定义MyBati ...
- tailwindcss 选型,以及vue配置使用
一.为什么选择tailwindcss? Tailwind CSS 是一个受欢迎的.功能丰富的CSS框架,它与传统的CSS框架(如Bootstrap)有些不同.以下是一些人们通常对于Tailwind C ...