使用CNN实现MNIST数据集分类
1 MNIST数据集和CNN网络配置
关于MNIST数据集的说明及配置见使用TensorFlow实现MNIST数据集分类
CNN网络参数配置如下:
- 原始数据:输入为[28,28],输出为[1,10]
- 卷积核1:[5,5],32个特征 -->282832
- 池化核1:[2,2],最大池化 -->141432
- 卷积核2:[5,5],2个特征 -->141464
- 池化核2:[2,2],最大池化 -->7764
- 全连接1:[7764,1024]
- 全连接2:[1024,10]
2 实验
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
#载入数据集
mnist=input_data.read_data_sets("MNIST_data",one_hot=True)
#每批次的大小
batch_size = 100
#总批次数
batch_num = mnist.train.num_examples//batch_size
#初始化权值函数
def weight_variable(shape):
initial=tf.truncated_normal(shape,stddev=0.1)
return tf.Variable(initial)
#初始化偏置值函数
def bias_vairable(shape):
initial=tf.constant(0.1,shape=shape)
return tf.Variable(initial)
#卷积层函数
def conv2d(x,w):
return tf.nn.conv2d(x,w,strides=[1,1,1,1],padding='SAME')
#池化层函数
def max_pool(x):
return tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
#定义三个placeholder
x = tf.placeholder(tf.float32,[None,784])
y = tf.placeholder(tf.float32,[None,10])
keep_prob = tf.placeholder(tf.float32)
x_image = tf.reshape(x,[-1,28,28,1])
#5*5的卷积核,1个平面->32个平面(每个平面抽取32个特征)
w_conv1 = weight_variable([5,5,1,32])
b_conv1 = bias_vairable([32])
#第一次卷积之后变为 28*28*32
h_conv1 = tf.nn.relu(conv2d(x_image, w_conv1) + b_conv1)
#第一次池化之后变为 14*14*32
h_pool1 = max_pool(h_conv1)
#5*5的卷积核,32个平面->64个平面(每个平面抽取2个特征)
w_conv2 = weight_variable([5,5,32,64])
b_conv2 = bias_vairable([64])
#第二次卷积之后变为 14*14*64
h_conv2 = tf.nn.relu(conv2d(h_pool1,w_conv2) + b_conv2)
#第二次池化之后变为 7*7*64
h_pool2 = max_pool(h_conv2)
#7*7*64的图像变成1维向量
h_pool2_flat = tf.reshape(h_pool2,[-1,7*7*64])
#第一个全连接层
w_fc1 = weight_variable([7*7*64,1024])
b_fc1 = bias_vairable([1024])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, w_fc1) + b_fc1)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
#第二个全连接层
w_fc2 = weight_variable([1024,10])
b_fc2 = bias_vairable([10])
h_fc2 = tf.matmul(h_fc1_drop,w_fc2) + b_fc2
#prediction = tf.nn.sigmoid(h_fc2)
#交叉熵损失函数
loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(labels=tf.argmax(y,1), logits=h_fc2))
#loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(labels=y, logits=h_fc2))
train = tf.train.AdamOptimizer(0.001).minimize(loss)
correct_prediction = (tf.equal(tf.argmax(h_fc2,1), tf.argmax(y,1)))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
#初始化变量
init=tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
test_feed={x:mnist.test.images,y:mnist.test.labels,keep_prob:1.0}
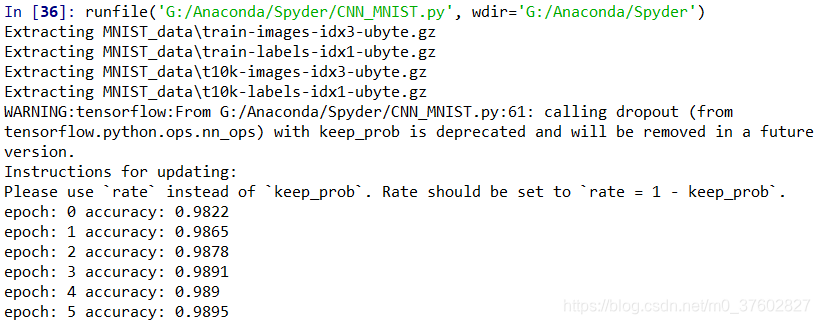
for epoch in range(6):
for batch in range(batch_num):
x_,y_=mnist.train.next_batch(batch_size)
sess.run(train,feed_dict={x:x_,y:y_,keep_prob:0.7})
acc=sess.run(accuracy,feed_dict=test_feed)
print("epoch:",epoch,"accuracy:",acc)
声明:本文转自使用CNN实现MNIST数据集分类
使用CNN实现MNIST数据集分类的更多相关文章
- 6.keras-基于CNN网络的Mnist数据集分类
keras-基于CNN网络的Mnist数据集分类 1.数据的载入和预处理 import numpy as np from keras.datasets import mnist from keras. ...
- 机器学习与Tensorflow(3)—— 机器学习及MNIST数据集分类优化
一.二次代价函数 1. 形式: 其中,C为代价函数,X表示样本,Y表示实际值,a表示输出值,n为样本总数 2. 利用梯度下降法调整权值参数大小,推导过程如下图所示: 根据结果可得,权重w和偏置b的梯度 ...
- 3.keras-简单实现Mnist数据集分类
keras-简单实现Mnist数据集分类 1.载入数据以及预处理 import numpy as np from keras.datasets import mnist from keras.util ...
- 卷积神经网络CNN识别MNIST数据集
这次我们将建立一个卷积神经网络,它可以把MNIST手写字符的识别准确率提升到99%,读者可能需要一些卷积神经网络的基础知识才能更好的理解本节的内容. 程序的开头是导入TensorFlow: impor ...
- 深度学习(一)之MNIST数据集分类
任务目标 对MNIST手写数字数据集进行训练和评估,最终使得模型能够在测试集上达到\(98\%\)的正确率.(最终本文达到了\(99.36\%\)) 使用的库的版本: python:3.8.12 py ...
- 第十三节,使用带有全局平均池化层的CNN对CIFAR10数据集分类
这里使用的数据集仍然是CIFAR-10,由于之前写过一篇使用AlexNet对CIFAR数据集进行分类的文章,已经详细介绍了这个数据集,当时我们是直接把这些图片的数据文件下载下来,然后使用pickle进 ...
- 神经网络MNIST数据集分类tensorboard
今天分享同样数据集的CNN处理方式,同时加上tensorboard,可以看到清晰的结构图,迭代1000次acc收敛到0.992 先放代码,注释比较详细,变量名字看单词就能知道啥意思 import te ...
- python,tensorflow,CNN实现mnist数据集的训练与验证正确率
1.工程目录 2.导入data和input_data.py 链接:https://pan.baidu.com/s/1EBNyNurBXWeJVyhNeVnmnA 提取码:4nnl 3.CNN.py i ...
- MNIST数据集分类简单版本
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data #载入数据集 mnist = ...
- 6.MNIST数据集分类简单版本
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data # 载入数据集 mnist = i ...
随机推荐
- css - 隐藏body滚动条
body::-webkit-scrollbar{ display: none; }
- [转帖]【教程】如何在不同架构打包Docker镜像
https://docs.qsnctf.com/qsnctf/37674.html 前言 大家在使用Docker的时候经常会遇到一个问题,就是受用机和本级不是同一架构.就比如小编使用的就是新版本的Ma ...
- [转帖]Linux Shell编程 循环语法
https://zhuanlan.zhihu.com/ for循环 for 循环是固定循环,也就是在循环时已经知道需要进行几次循环.有时也把 for 循环称为计数循环.语法: for 变量 in 值1 ...
- [转帖]AlertManager 配置邮箱告警
http://www.mydlq.club/article/126/ 2022-12-02 13:17:00KUBERNETESPROMETHEUSALERTMANAGER 文章目录 一.邮箱告警说明 ...
- [转帖]jmeter学习笔记(二十二)——监听器插件之jp@gc系列
一.jp@gc - Actiive Threads Over Time 不同时间活动用户数量展示 下面是一个阶梯加压测试的图标 二.jp@gc - Transactions per Second ...
- [转帖]【P1】Jmeter 准备工作
文章目录 一.Jmeter 介绍 1.1.Jmeter 有什么样功能 1.2.Jmeter 与 LoadRunner 比较 1.3.常用性能测试工具 1.4.性能测试工具如何选型 1.5.学习 Jme ...
- [转帖]《Linux性能优化实战》笔记(24)—— 动态追踪 DTrace
使用 perf 对系统内核线程进行分析时,内核线程依然还在正常运行中,所以这种方法也被称为动态追踪技术.动态追踪技术通过探针机制来采集内核或者应用程序的运行信息,从而可以不用修改内核和应用程序的代码就 ...
- [转帖]【测试】 FIO:ceph/磁盘IO测试工具 fio(iodepth深度)
目录 随看随用 NAS文件系统测试 块系统测试 FIO用法 FIO介绍 FIO 工具常用参数: FIO结果说明 I/O 的重放('录'下实际工况的IO,用fio'重放') fio工作参数可以写入配置文 ...
- [转帖]Ubuntu Server安装图形界面
最早接触到的Linux系统是Ubuntu 10.04,当时在自己的一台Win7笔记本电脑上安装的Win/Ubuntu双系统,Ubuntu简洁的操作界面给我留下了深刻的印象. 后来开始做一些服务器开发, ...
- with(上下文管理器)的用法
with语句可以自动管理上下文资源,不论什么原因(成功或失败)跳出with语句,都能保证文件正确关闭,并 释放资源,不用手动去close掉资源 1.with语句中有两个内置方法__enter__和__ ...