使用CNN实现MNIST数据集分类
1 MNIST数据集和CNN网络配置
关于MNIST数据集的说明及配置见使用TensorFlow实现MNIST数据集分类
CNN网络参数配置如下:
- 原始数据:输入为[28,28],输出为[1,10]
- 卷积核1:[5,5],32个特征 -->282832
- 池化核1:[2,2],最大池化 -->141432
- 卷积核2:[5,5],2个特征 -->141464
- 池化核2:[2,2],最大池化 -->7764
- 全连接1:[7764,1024]
- 全连接2:[1024,10]
2 实验
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
#载入数据集
mnist=input_data.read_data_sets("MNIST_data",one_hot=True)
#每批次的大小
batch_size = 100
#总批次数
batch_num = mnist.train.num_examples//batch_size
#初始化权值函数
def weight_variable(shape):
initial=tf.truncated_normal(shape,stddev=0.1)
return tf.Variable(initial)
#初始化偏置值函数
def bias_vairable(shape):
initial=tf.constant(0.1,shape=shape)
return tf.Variable(initial)
#卷积层函数
def conv2d(x,w):
return tf.nn.conv2d(x,w,strides=[1,1,1,1],padding='SAME')
#池化层函数
def max_pool(x):
return tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
#定义三个placeholder
x = tf.placeholder(tf.float32,[None,784])
y = tf.placeholder(tf.float32,[None,10])
keep_prob = tf.placeholder(tf.float32)
x_image = tf.reshape(x,[-1,28,28,1])
#5*5的卷积核,1个平面->32个平面(每个平面抽取32个特征)
w_conv1 = weight_variable([5,5,1,32])
b_conv1 = bias_vairable([32])
#第一次卷积之后变为 28*28*32
h_conv1 = tf.nn.relu(conv2d(x_image, w_conv1) + b_conv1)
#第一次池化之后变为 14*14*32
h_pool1 = max_pool(h_conv1)
#5*5的卷积核,32个平面->64个平面(每个平面抽取2个特征)
w_conv2 = weight_variable([5,5,32,64])
b_conv2 = bias_vairable([64])
#第二次卷积之后变为 14*14*64
h_conv2 = tf.nn.relu(conv2d(h_pool1,w_conv2) + b_conv2)
#第二次池化之后变为 7*7*64
h_pool2 = max_pool(h_conv2)
#7*7*64的图像变成1维向量
h_pool2_flat = tf.reshape(h_pool2,[-1,7*7*64])
#第一个全连接层
w_fc1 = weight_variable([7*7*64,1024])
b_fc1 = bias_vairable([1024])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, w_fc1) + b_fc1)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
#第二个全连接层
w_fc2 = weight_variable([1024,10])
b_fc2 = bias_vairable([10])
h_fc2 = tf.matmul(h_fc1_drop,w_fc2) + b_fc2
#prediction = tf.nn.sigmoid(h_fc2)
#交叉熵损失函数
loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(labels=tf.argmax(y,1), logits=h_fc2))
#loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(labels=y, logits=h_fc2))
train = tf.train.AdamOptimizer(0.001).minimize(loss)
correct_prediction = (tf.equal(tf.argmax(h_fc2,1), tf.argmax(y,1)))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
#初始化变量
init=tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
test_feed={x:mnist.test.images,y:mnist.test.labels,keep_prob:1.0}
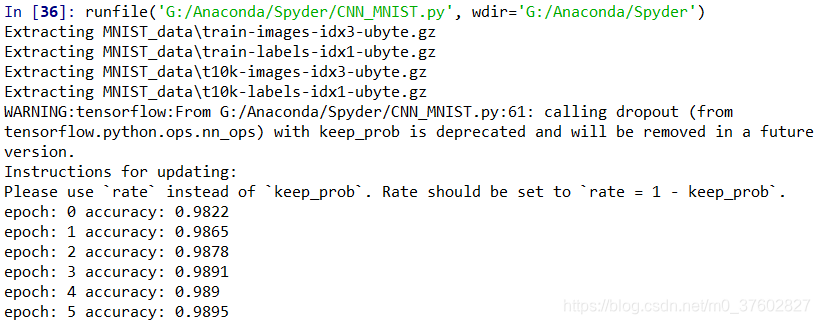
for epoch in range(6):
for batch in range(batch_num):
x_,y_=mnist.train.next_batch(batch_size)
sess.run(train,feed_dict={x:x_,y:y_,keep_prob:0.7})
acc=sess.run(accuracy,feed_dict=test_feed)
print("epoch:",epoch,"accuracy:",acc)
声明:本文转自使用CNN实现MNIST数据集分类
使用CNN实现MNIST数据集分类的更多相关文章
- 6.keras-基于CNN网络的Mnist数据集分类
keras-基于CNN网络的Mnist数据集分类 1.数据的载入和预处理 import numpy as np from keras.datasets import mnist from keras. ...
- 机器学习与Tensorflow(3)—— 机器学习及MNIST数据集分类优化
一.二次代价函数 1. 形式: 其中,C为代价函数,X表示样本,Y表示实际值,a表示输出值,n为样本总数 2. 利用梯度下降法调整权值参数大小,推导过程如下图所示: 根据结果可得,权重w和偏置b的梯度 ...
- 3.keras-简单实现Mnist数据集分类
keras-简单实现Mnist数据集分类 1.载入数据以及预处理 import numpy as np from keras.datasets import mnist from keras.util ...
- 卷积神经网络CNN识别MNIST数据集
这次我们将建立一个卷积神经网络,它可以把MNIST手写字符的识别准确率提升到99%,读者可能需要一些卷积神经网络的基础知识才能更好的理解本节的内容. 程序的开头是导入TensorFlow: impor ...
- 深度学习(一)之MNIST数据集分类
任务目标 对MNIST手写数字数据集进行训练和评估,最终使得模型能够在测试集上达到\(98\%\)的正确率.(最终本文达到了\(99.36\%\)) 使用的库的版本: python:3.8.12 py ...
- 第十三节,使用带有全局平均池化层的CNN对CIFAR10数据集分类
这里使用的数据集仍然是CIFAR-10,由于之前写过一篇使用AlexNet对CIFAR数据集进行分类的文章,已经详细介绍了这个数据集,当时我们是直接把这些图片的数据文件下载下来,然后使用pickle进 ...
- 神经网络MNIST数据集分类tensorboard
今天分享同样数据集的CNN处理方式,同时加上tensorboard,可以看到清晰的结构图,迭代1000次acc收敛到0.992 先放代码,注释比较详细,变量名字看单词就能知道啥意思 import te ...
- python,tensorflow,CNN实现mnist数据集的训练与验证正确率
1.工程目录 2.导入data和input_data.py 链接:https://pan.baidu.com/s/1EBNyNurBXWeJVyhNeVnmnA 提取码:4nnl 3.CNN.py i ...
- MNIST数据集分类简单版本
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data #载入数据集 mnist = ...
- 6.MNIST数据集分类简单版本
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data # 载入数据集 mnist = i ...
随机推荐
- HTTP 1.1响应码
HTTP 1.1响应码 响应码和信息 含义 HttpURLConnection 1XX 信息 100 Continue 服务器准备接受请求主体,客户端应当发送请求主体:这允许客户端在请求中发送大量数据 ...
- [转帖]shell编程:shell变量的核心基础知识与实战(二)
shell编程:shell变量的核心基础知识与实战(二) https://www.cnblogs.com/luoahong/articles/9152039.html Shell 变量类型 变量可以分 ...
- [转帖]46岁加入谷歌,51岁发明Go,他的编程原则影响了一大批程序员!
https://www.zhihu.com/tardis/zm/art/551945410?source_id=1005 今年3月,万众瞩目的Go 1.18版本发布,Go终于开始支持泛型了!该版本不仅 ...
- [转帖]在 Linux 上以 All-in-One 模式安装 KubeSphere
https://www.kubesphere.io/zh/docs/v3.4/quick-start/all-in-one-on-linux/ 对于刚接触 KubeSphere 并想快速上手该容器平台 ...
- [转帖]CentOS-7-x86_64-Everything-2009 rpm包列表(CentOS7.9)
CentOS-7-x86_64-Everything-2009 rpm包列表(CentOS7.9) 共10073个文件 复制389-ds-base-1.3.10.2-6.el7.x86_64.rpm ...
- [转帖]Linux—vi/vim全局替换
https://www.jianshu.com/p/4daa5dbc7dd5 vim全局替换 在linux系统中编辑文件或者配置时,常常会用到全局替换功能. 语法格式 :%s/oldWords/n ...
- [转帖]使用Transformers推理
https://github.com/ymcui/Chinese-LLaMA-Alpaca/wiki/%E4%BD%BF%E7%94%A8Transformers%E6%8E%A8%E7%90%86 ...
- 【转帖】JAVA GC日志分析
https://zhuanlan.zhihu.com/p/613592552 目录 1. GC分类 针对HotSpot VM的实现,它里面的GC按照回收区域又分为两大种类型:一种是部分收集(Par ...
- [转帖]logback:logback和slf4j中的:appender、logger、encoder、layout
(1)appender 1.appender标签是logback配置文件中重要的组件之一.在logback配置文件中使用appender标签进行定义.可 以包含0个或多个appender标签. 2.a ...
- Linux 通过命令方式反编译jar包的方法
第一步: 复制jar包到指定路径. find . -iname "*.jar" -exec scp {} /root/bf/ \; 第二步: 解压缩jar包解压缩出来class文件 ...