03 elasticsearch学习笔记-IK分词器?
1. 什么是IK分词器

2. 下载IK分词器
下载地址,版本要和ES的版本对应上
https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.3.1
注意下载zip版本
下载完毕后,放入到我们的elasticsearch/plugins/ik插件目录里即可

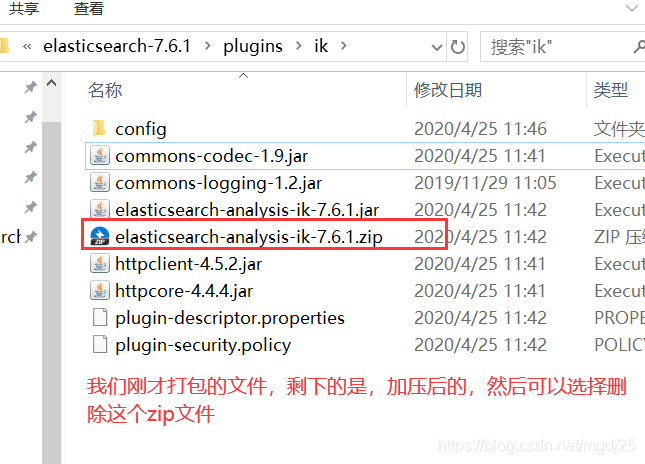
重启观察ES,可以看到IK分词器被加载了!

elasticsearch-plugin可以通过这个命令查看加载进来的插件

docker下载的安装的查看方法
root@haima-PC:/usr/local/docker/efk/docker_compose_efk# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c43439e99ff0 docker_compose_efk_fluentd "/bin/entrypoint.sh …" 29 seconds ago Up 27 seconds 5140/tcp, 0.0.0.0:24224->24224/tcp, 0.0.0.0:24224->24224/udp docker_compose_efk_fluentd_1
00eda4c1585d docker_compose_efk_kibana "/usr/local/bin/dumb…" 29 seconds ago Up 26 seconds 0.0.0.0:5601->5601/tcp docker_compose_efk_kibana_1
6e2e42f9e3ca docker.elastic.co/elasticsearch/elasticsearch:7.3.1 "/usr/local/bin/dock…" 31 seconds ago Up 29 seconds 0.0.0.0:9200->9200/tcp, 9300/tcp docker_compose_efk_elasticsearch_1
root@haima-PC:/usr/local/docker/efk/docker_compose_efk# docker exec -it docker_compose_efk_elasticsearch_1 bash ./bin/elasticsearch-plugin list
ik
详细查看我github里的readme.md
https://github.com/haimait/docker_compose_efk
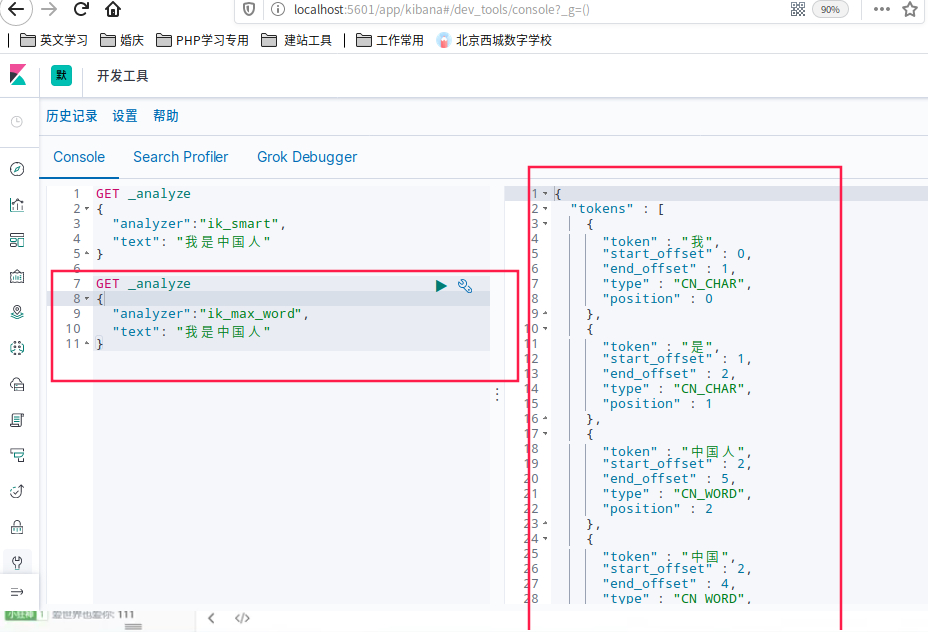
3. 使用kibana测试!
查看不同的分词效果
ik_smart和ik_max_word,其中ik_smart为最少切分
GET _analyze
{
"analyzer":"ik_smart",
"text": "我是中国人"
}
划出了3组
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "中国人",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
}
]
}

ik_max_word为最细粒度划分,穷尽词库的可能
GET _analyze
{
"analyzer":"ik_max_word",
"text": "我是中国人"
}
划出了5组
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "中国人",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "中国",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "国人",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 4
}
]
}
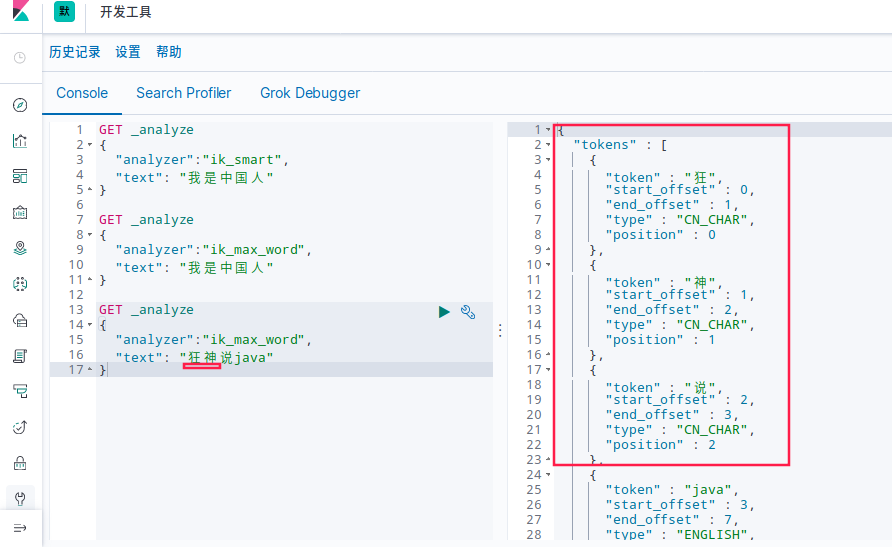
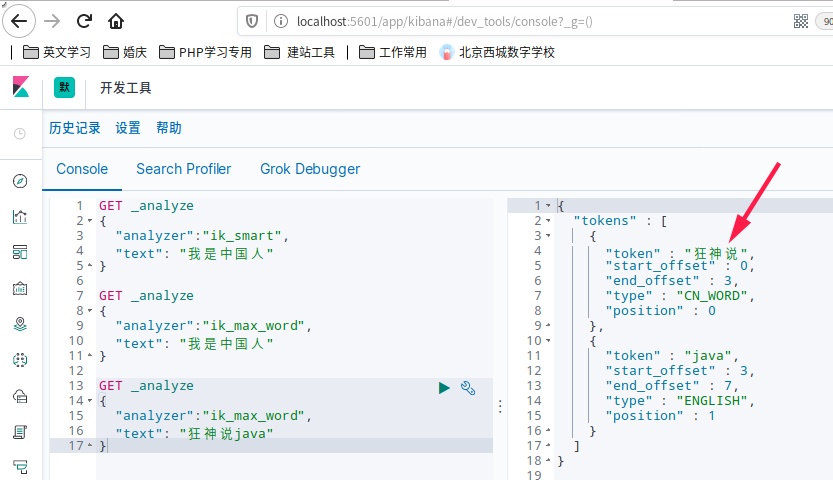
测试狂神说java
发现狂神说被分词器拆分开了,这里我们不想让它拆开,就需要在分词器中添加一个自己的词典,把自己的词放到自己的词典里
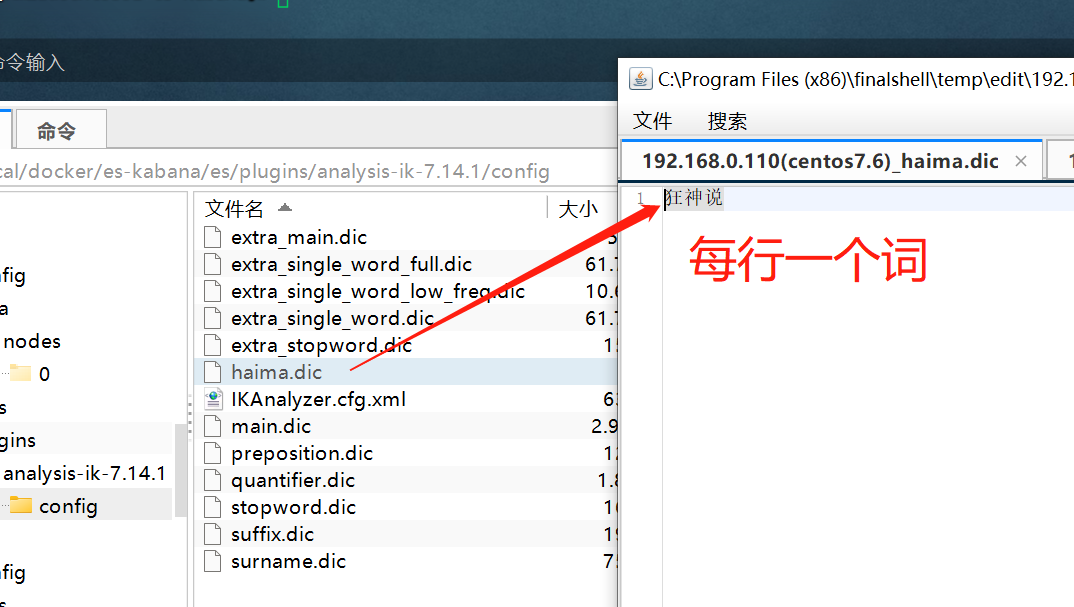
4. 创建自定义词典
- 创建
haima.dic
vim /elasticsearch/es/plugins/ik/config/haima.dic
写入 狂神说
- 把自定义的
haima.dic字典,载入到配置文件里
vim /elasticsearch/es/plugins/ik/config/IKAnalyzer.cfg.xml
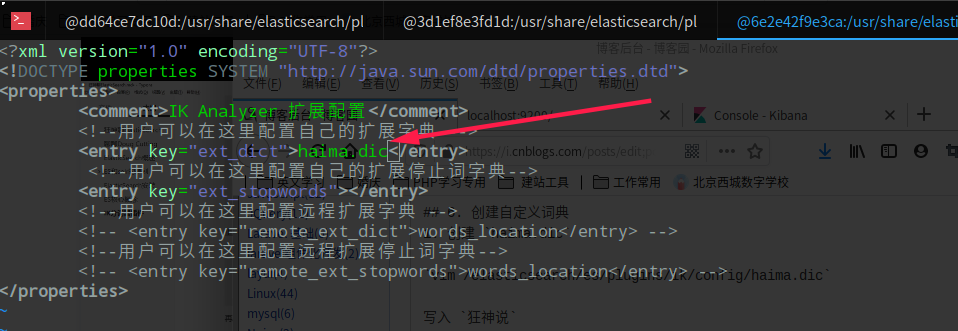
- 重启es服务
root@haima-PC:/usr/local/docker/efk/docker_compose_efk/elasticsearch/es/plugins/ik/config# docker restart docker_compose_efk_elasticsearch_1
docker_compose_efk_elasticsearch_1
- 再看一下分词器,
狂神说已经不会被分开了
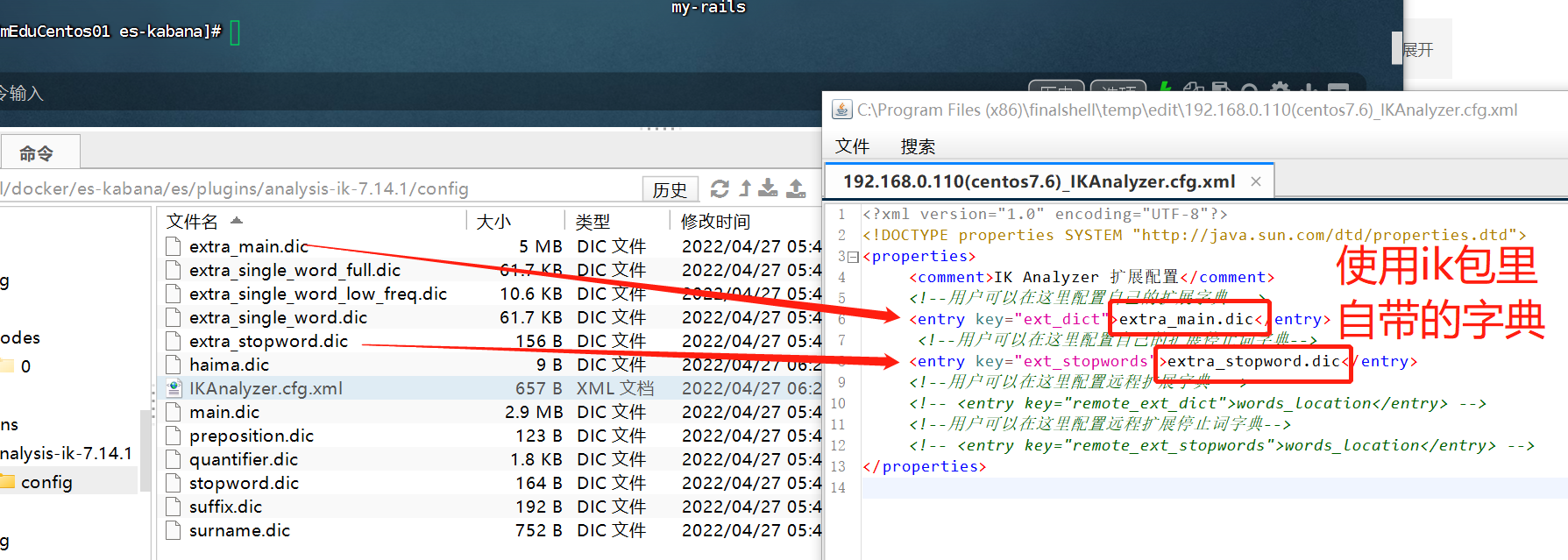
- 使用ik分词包里自带的词典
5. Analysis
analysis(只是一个概念),文本分析是将全文本转换为一系列单词的过程,也叫分词。analysis是通
过analyzer(分词器)来实现的,可以使用Elasticsearch内置的分词器,也可以自己去定制一些分词
器。 除了在数据写入的时候进行分词处理,那么在查询的时候也可以使用分析器对查询语句进行分词。
anaylzer是由三部分组成,例如有
Hello a World, the world is beautifu
Analyzer的处理过程
分词器名称 处理过程
Standard Analyzer 默认的分词器,按词切分,小写处理
Simple Analyzer 按照非字母切分(符号被过滤),小写处理
Stop Analyzer 小写处理,停用词过滤(the, a, this)
Whitespace Analyzer 按照空格切分,不转小写
Keyword Analyzer 不分词,直接将输入当做输出
Pattern Analyzer 正则表达式,默认是\W+(非字符串分隔)
1. Character Filter: 将文本中html标签剔除掉。
2. Tokenizer: 按照规则进行分词,在英文中按照空格分词。
3. Token Filter: 去掉stop world(停顿词,a, an, the, is, are等),然后转换小写
内置分词器
| 分词器名称 | 分词器名称 |
|---|---|
| 分词器名称 | 分词器名称 |
| Simple Analyzer | 按照非字母切分(符号被过滤),小写处理 |
| Stop Analyzer | 小写处理,停用词过滤(the, a, this) |
| Whitespace Analyzer | 按照空格切分,不转小写 |
| Keyword Analyzer | 不分词,直接将输入当做输出 |
| Pattern Analyzer | 正则表达式,默认是\W+(非字符串分隔) |
** 内置分词器示例**
5.2.1 Standard Analyzer
GET _analyze
{
"analyzer": "standard",
"text": "2 Running quick brown-foxes leap over lazy dog in the summer evening"
}
5.2.2 Simple Analyzer
GET _analyze
{
"analyzer": "simple",
"text": "2 Running quick brown-foxes leap over lazy dog in the summer evening"
}
5.2.3 Stop Analyzer
GET _analyze
{
"analyzer": "stop",
"text": "2 Running quick brown-foxes leap over lazy dog in the summer evening"
}
5.2.4 Whitespace Analyzer
GET _analyze
{
"analyzer": "whitespace",
"text": "2 Running quick brown-foxes leap over lazy dog in the summer evening"
}
5.2.5 Keyword Analyzer
GET _analyze
{
"analyzer": "keyword",
"text": "2 Running quick brown-foxes leap over lazy dog in the summer evening"
}
5.2.6 Pattern Analyzer
GET _analyze
{
"analyzer": "pattern",
"text": "2 Running quick brown-foxes leap over lazy dog in the summer evening"
}
03 elasticsearch学习笔记-IK分词器?的更多相关文章
- Elasticsearch下安装ik分词器
安装ik分词器(必须安装maven) 上传相应jar包 解压到相应目录 unzip elasticsearch-analysis-ik-master.zip(zip包) cp -r elasticse ...
- 【ELK】【docker】【elasticsearch】2.使用elasticSearch+kibana+logstash+ik分词器+pinyin分词器+繁简体转化分词器 6.5.4 启动 ELK+logstash概念描述
官网地址:https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html#docker-cli-run-prod ...
- Elasticsearch 7.x - IK分词器插件(ik_smart,ik_max_word)
一.安装IK分词器 Elasticsearch也需要安装IK分析器以实现对中文更好的分词支持. 去Github下载最新版elasticsearch-ik https://github.com/medc ...
- Elasticsearch拼音和ik分词器的结合应用
一.创建索引时,自定义拼音分词和ik分词 PUT /my_index { "index": { "analysis": { "analyzer&quo ...
- linux(centos 7)下安装elasticsearch 5 的 IK 分词器
(一)到IK 下载 对应的版本(直接下载release版本,避免mvn打包),下载后是一个zip压缩包 (二)将压缩包上传至elasticsearch 的安装目录下的plugins下,进行解压,运行如 ...
- 通过docker安装elasticsearch和安装ik分词器插件及安装kibana
前提: 已经安装好docker运行环境: 步骤: 1.安装elasticsearch 6.2.2版本,目前最新版是7.2.0,这里之所以选择6.2.2是因为最新的SpringBoot2.1.6默认支持 ...
- 【ELK】【docker】【elasticsearch】1. 使用Docker和Elasticsearch+ kibana 5.6.9 搭建全文本搜索引擎应用 集群,安装ik分词器
系列文章:[建议从第二章开始] [ELK][docker][elasticsearch]1. 使用Docker和Elasticsearch+ kibana 5.6.9 搭建全文本搜索引擎应用 集群,安 ...
- docker 部署 elasticsearch + elasticsearch-head + elasticsearch-head跨域问题 + IK分词器
0. docker pull 拉取elasticsearch + elasticsearch-head 镜像 1. 启动elasticsearch Docker镜像 docker run -di ...
- Docker 下Elasticsearch 的安装 和ik分词器
(1)docker镜像下载 docker pull elasticsearch:5.6.8 (2)安装es容器 docker run -di --name=changgou_elasticsearch ...
- Elasticsearch(ES)分词器的那些事儿
1. 概述 分词器是Elasticsearch中很重要的一个组件,用来将一段文本分析成一个一个的词,Elasticsearch再根据这些词去做倒排索引. 今天我们就来聊聊分词器的相关知识. 2. 内置 ...
随机推荐
- KingbaseES 表级设置autovacuum有关参数和触发机制
前言 在表级别设置autovacuum有关参数清理表的死亡元祖可以有效规避autovacuum触发全局默认阈值的高峰.例如,如果想让表的autovacuum任务更频繁,可以在表级设置更小的触发auto ...
- 鸿蒙HarmonyOS实战-ArkUI组件(Swiper)
一.Swiper 1.概述 Swiper可以实现手机.平板等移动端设备上的图片轮播效果,支持无缝轮播.自动播放.响应式布局等功能.Swiper轮播图具有使用简单.样式可定制.功能丰富.兼容性好等优点, ...
- #树状数组,dp#洛谷 3506 [POI2010]MOT-Monotonicity 2
题目 给出\(N\)个正整数\(a[1..N]\),再给出\(K\)个关系符号(>.<或=)\(s[1..k]\). 选出一个长度为\(L\)的子序列(不要求连续),要求这个子序列的第\( ...
- OpenHarmony父子组件单项同步使用:@Prop装饰器
@Prop装饰的变量可以和父组件建立单向的同步关系.@Prop装饰的变量是可变的,但是变化不会同步回其父组件. 说明: 从API version 9开始,该装饰器支持在ArkTS卡片中使用. 概述 ...
- C#中超链接方法
linkLabel控件:双击事件打开网页:System.Diagnostics.Process.Start("http://www.baidu.com"); 截图:
- C# sqlclient数据库事务BeginTransaction()详解
重载 重载 BeginTransaction() 开始数据库事务. BeginTransaction(IsolationLevel) 以指定的隔离级别启动数据库事务. BeginTransaction ...
- Mybatis实现增删改查
1.CRUD 1.1namespace namespace中的包名必须和Dao/mapper接口包名一致 1.2select 选择,查询语句 id:就是对应的namespace中的方法名 resul ...
- 基于HarmonyOS的HTTPS请求过程开发示例(ArkTS)
介绍 本篇Codelab基于网络模块以及Webview实现一次HTTPS请求,并对其过程进行抓包分析.效果如图所示: 相关概念 ● Webview:提供Web控制能力,Web组件提供网页显示能力. ...
- Django框架——Q查询进阶、ORM查询优化、事务操作、字段类型、字段参数、Ajax、Content—Type、ajax携带文件
Q查询进阶 from django.db.models import Q q_obj = Q() # 1.产生q对象 q_obj.connector = 'or' # 默认多个条件的连接是and可以修 ...
- 剑指offer04(Java)二维数组中的查找(中等)
题目: 在一个 n * m 的二维数组中,每一行都按照从左到右 非递减 的顺序排序,每一列都按照从上到下 非递减 的顺序排序.请完成一个高效的函数,输入这样的一个二维数组和一个整数,判断数组中是否含有 ...