Django(19)QuerySet API
前言
我们通常做查询操作的时候,都是通过模型名字.objects的方式进行操作。其实模型名字.objects是一个django.db.models.manager.Manager对象,而Manager这个类是一个“空壳”的类,他本身是没有任何的属性和方法的。他的方法全部都是通过Python动态添加的方式,从QuerySet类中拷贝过来的。示例图如下:
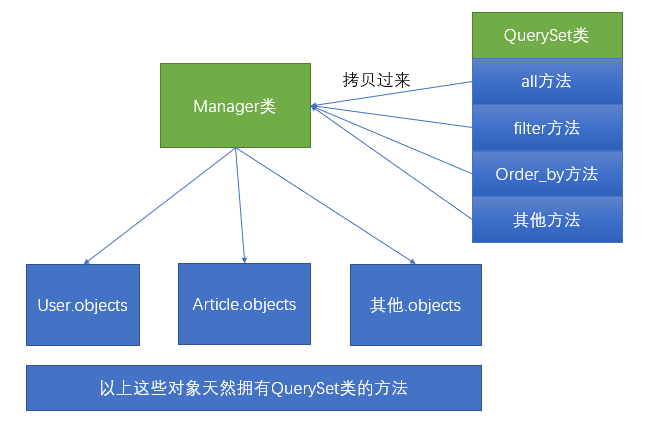
所以我们如果想要学习ORM模型的查找操作,必须首先要学会QuerySet上的一些API的使用
QuerySet 21个常用的API
filter
filter:将满足条件的数据提取出来,返回一个新的QuerySet。具体详情可查看这篇:https://www.cnblogs.com/jiakecong/p/14780601.html
exclude
exclude:排除满足条件的数据,返回一个新的QuerySet。示例代码如下:
Article.objects.exclude(title__contains='hello')
以上代码的意思是提取那些标题不包含hello的图书。
annotate
annotate:给QuerySet中的每个对象都添加一个使用查询表达式(聚合函数、F表达式、Q表达式、Func表达式等)的新字段。示例代码如下:
articles = Article.objects.annotate(author_age=F("author__age"))
以上代码将在每个对象中都添加一个author__age的字段,用来显示这个文章的作者的年龄。
order_by
order_by:指定将查询的结果根据某个字段进行排序。如果要倒叙排序,那么可以在这个字段的前面加一个负号。示例代码如下:
# 根据创建的时间正序排序
articles = Article.objects.order_by("create_time")
# 根据创建的时间倒序排序
articles = Article.objects.order_by("-create_time")
# 根据作者的名字进行排序
articles = Article.objects.order_by("author__name")
# 首先根据创建的时间进行排序,如果时间相同,则根据作者的名字进行排序
articles = Article.objects.order_by("create_time",'author__name')
一定要注意的一点是,多个order_by,会把前面排序的规则给打乱,而使用后面的排序方式。比如以下代码:
articles = Article.objects.order_by("create_time").order_by("author__name")
他会根据作者的名字进行排序,而不是使用文章的创建时间。
values
values:用来指定在提取数据出来,需要提取哪些字段。默认情况下会把表中所有的字段全部都提取出来,可以使用values来进行指定,并且使用了values方法后,提取出的QuerySet中的数据类型不是模型,而是在values方法中指定的字段和值形成的字典:
articles = Article.objects.values("title",'content')
for article in articles:
print(article)
以上打印出来的article是类似于{"title":"abc","content":"xxx"}的形式。如果在values中没有传递任何参数,那么将会返回一个字典,字典中包含这个模型中所有的属性。
如果我们想要提取的是这个模型上关联对象的属性,那么也是可以的,示例代码如下:
articles = Article.objects.values('title', 'content', 'author__name')
以上将会提取author的name字段,如果我们不想要这个名字,想自定义名字,可以使用关键字参数,示例代码如下:
articles = Articles.objects.values('title', 'content', authorName=F('author__name'))
注意:自定义的名字不能跟模型上本身拥有的字段一样,比如author__name名字改成author那么会报错,因为Article模型上本身拥有一个字段叫做author,会产生冲突
values_list
values_list:类似于values。只不过返回的QuerySet中,存储的不是字典,而是元组。示例代码如下:
articles = Article.objects.values_list("id","title")
print(articles)
那么在打印articles后,结果为<QuerySet [(1,'abc'),(2,'xxx'),...]>等。
如果在values_list中只有一个字段。那么你可以传递flat=True,这样返回的结果就不在是一个元组,而是整个字段的值,示例代码如下:
articles2 = Article.objects.values_list("title",flat=True)
那么以上返回的结果是
abc
xxx
all
all:获取这个ORM模型的QuerySet对象。
select_related
select_related:在提取某个模型的数据的同时,也提前将相关联的数据提取出来。比如提取文章数据,可以使用select_related将author信息提取出来,以后再次使用article.author的时候就不需要再次去访问数据库了。可以减少数据库查询的次数。示例代码如下:
article = Article.objects.get(pk=1)
>> article.author # 重新执行一次查询语句
article = Article.objects.select_related("author").get(pk=2)
>> article.author # 不需要重新执行查询语句了
注意:selected_related只能用在一对多或者一对一中,不能用在多对多或者多对一中。比如可以提前获取文章的作者,但是不能通过作者获取这个作者的文章,或者是通过某篇文章获取这个文章所有的标签。
prefetch_related
prefetch_related:这个方法和select_related非常的类似,就是在访问多个表中的数据的时候,减少查询的次数。这个方法是为了解决多对一和多对多的关系的查询问题。比如要获取标题中带有hello字符串的文章以及他的所有标签,示例代码如下:
from django.db import connection
articles = Article.objects.prefetch_related("tag_set").filter(title__contains='hello')
print(articles.query) # 通过这条命令查看在底层的SQL语句
for article in articles:
print("title:",article.title)
print(article.tag_set.all())
# 通过以下代码可以看出以上代码执行的sql语句
for sql in connection.queries:
print(sql)
但是如果在使用article.tag_set的时候,如果又创建了一个新的QuerySet那么会把之前的SQL优化给破坏掉。比如以下代码:
tags = Tag.obejcts.prefetch_related("articles")
for tag in tags:
articles = tag.articles.filter(title__contains='hello') # 因为filter方法会重新生成一个QuerySet,因此会破坏掉之前的sql优化
# 通过以下代码,我们可以看到在使用了filter的,他的sql查询会更多,而没有使用filter的,只有两次sql查询
for sql in connection.queries:
print(sql)
那如果确实是想要在查询的时候指定过滤条件该如何做呢,这时候我们可以使用django.db.models.Prefetch来实现,Prefetch这个可以提前定义好queryset。示例代码如下:
tags = Tag.objects.prefetch_related(Prefetch("articles",queryset=Article.objects.filter(title__contains='hello'))).all()
for tag in tags:
articles = tag.articles.all()
for article in articles:
print(article)
for sql in connection.queries:
print('='*30)
print(sql)
因为使用了Prefetch,即使在查询文章的时候使用了filter,也只会发生两次查询操作
defer
defer:在一些表中,可能存在很多的字段,但是一些字段的数据量可能是比较庞大的,而此时你又不需要,比如我们在获取文章列表的时候,文章的内容我们是不需要的,因此这时候我们就可以使用defer来过滤掉一些字段。这个字段跟values有点类似,只不过defer返回的不是字典,而是模型。示例代码如下:
articles = Article.objects.defer("title")
for article in articles:
print('article.id')
defer虽然能过滤字段,但是有些字段是不能过滤的,比如id,即使你过滤了,也会提取出来。
only
only:跟defer类似,只不过defer是过滤掉指定的字段,而only是只提取指定的字段。
get
get:获取满足条件的数据。这个函数只能返回一条数据,并且如果给的条件有多条数据,那么这个方法会抛出MultipleObjectsReturned错误,如果给的条件没有任何数据,那么就会抛出DoesNotExit错误。所以这个方法在获取数据,只能有且只有一条。
create
create:创建一条数据,并且保存到数据库中。这个方法相当于先用指定的模型创建一个对象,然后再调用这个对象的save方法。示例代码如下:
article = Article(title='abc')
article.save()
# 下面这行代码相当于以上两行代码
article = Article.objects.create(title='abc')
get_or_create
get_or_create:根据某个条件进行查找,如果找到了那么就返回这条数据,如果没有查找到,那么就创建一个。示例代码如下:
obj,created= Category.objects.get_or_create(title='默认分类')
如果有标题等于默认分类的分类,那么就会查找出来,如果没有,则会创建并且存储到数据库中。这个方法的返回值是一个元组,元组的第一个参数obj是这个对象,第二个参数created代表是否创建的。
bulk_create
bulk_create:一次性创建多个数据。示例代码如下:
Tag.objects.bulk_create([
Tag(name='111'),
Tag(name='222'),
])
count
获取提取的数据的个数。如果想要知道总共有多少条数据,那么建议使用count,而不是使用len(articles)这种。因为count在底层是使用select count(*)来实现的,这种方式比使用len函数更加的高效。
first和last
first和last:返回QuerySet中的第一条和最后一条数据
aggregate
aggregate:使用聚合函数。具体详情可参考这篇:https://www.cnblogs.com/jiakecong/p/14784109.html
exists
exists:判断某个条件的数据是否存在。如果要判断某个条件的元素是否存在,那么建议使用exists,这比使用count或者直接判断QuerySet更有效得多。示例代码如下:
result = Book.objects.filter(name="三国演义").exists()
print(result)
distinct
distinct:去除掉那些重复的数据。这个方法如果底层数据库用的是MySQL,那么不能传递任何的参数。比如想要提取所有销售的价格超过80元的图书,并且删掉那些重复的,那么可以使用distinct来帮我们实现,示例代码如下:
books = Book.objects.filter(bookorder__price__gte=80).distinct()
需要注意的是,如果在distinct之前使用了order_by,那么因为order_by会提取order_by中指定的字段,因此再使用distinct就会根据多个字段来进行唯一化,所以就不会把那些重复的数据删掉。示例代码如下:
orders = BookOrder.objects.order_by("create_time").values("book_id").distinct()
那么以上代码因为使用了order_by,即使使用了distinct,也会把重复的book_id提取出来。
update
update:执行更新操作,在SQL底层走的也是update命令。比如要将所有category为空的article的article字段都更新为默认的分类。示例代码如下:
Article.objects.filter(category__isnull=True).update(category_id=3)
delete
delete:删除所有满足条件的数据。删除数据的时候,要注意on_delete指定的处理方式。
切片
切片操作:有时候我们查找数据,有可能只需要其中的一部分。那么这时候可以使用切片操作来帮我们完成。QuerySet使用切片操作就跟列表使用切片操作是一样的。示例代码如下:
books = Book.objects.all()[1:3]
for book in books:
print(book)
切片操作并不是把所有数据从数据库中提取出来再做切片操作。而是在数据库层面使用LIMIE和OFFSET来帮我们完成。所以如果只需要取其中一部分的数据的时候,建议大家使用切片操作。
Django将QuerySet转换为SQL语句去执行的五种情况
- 迭代:在遍历
QuerySet对象的时候,会首先先执行这个SQL语句,然后再把这个结果返回进行迭代。比如以下代码就会转换为SQL语句:
for book in Book.objects.all():
print(book)
- 使用步长做切片操作:
QuerySet可以类似于列表一样做切片操作。做切片操作本身不会执行SQL语句,但是如果如果在做切片操作的时候提供了步长,那么就会立马执行SQL语句。需要注意的是,做切片后不能再执行filter方法,否则会报错。 - 调用len函数:调用len函数用来获取
QuerySet中总共有多少条数据也会执行SQL语句。 - 调用list函数:调用list函数用来将一个
QuerySet对象转换为list对象也会立马执行SQL语句。 - 判断:如果对某个
QuerySet进行判断,也会立马执行SQL语句。
Django(19)QuerySet API的更多相关文章
- [py]django强悍的数据库接口(QuerySet API)-增删改查
django强悍的数据库接口(QuerySet API) 4种方法插入数据 获取某个对象 filter过滤符合条件的对象 filter过滤排除某条件的对象- 支持链式多重查询 没找到排序的 - 4种方 ...
- Django(三) 模型:ORM框架、定义模型类并创建一个对应的数据库、配置Mysql数据库
一.模型概述 https://docs.djangoproject.com/zh-hans/3.0/intro/tutorial02/ https://www.runoob.com/django/dj ...
- guava 学习笔记(二) 瓜娃(guava)的API快速熟悉使用
guava 学习笔记(二) 瓜娃(guava)的API快速熟悉使用 1,大纲 让我们来熟悉瓜娃,并体验下它的一些API,分成如下几个部分: Introduction Guava Collection ...
- Hadoop 系列(三)Java API
Hadoop 系列(三)Java API <dependency> <groupId>org.apache.hadoop</groupId> <artifac ...
- 漫谈可视化Prefuse(三)---Prefuse API数据结构阅读有感
前篇回顾:上篇<漫谈可视化Prefuse(二)---一分钟学会Prefuse>主要通过一个Prefuse的具体实例了解了构建一个Prefuse application的具体步骤.一个Pre ...
- Docker入门教程(七)Docker API
Docker入门教程(七)Docker API [编者的话]DockerOne组织翻译了Flux7的Docker入门教程,本文是系列入门教程的第七篇,重点介绍了Docker Registry API和 ...
- 构建ASP.NET MVC4+EF5+EasyUI+Unity2.x注入的后台管理系统(19)-权限管理系统-用户登录
原文:构建ASP.NET MVC4+EF5+EasyUI+Unity2.x注入的后台管理系统(19)-权限管理系统-用户登录 我们之前做了验证码,登录界面,却没有登录实际的代码,我们这次先把用户登录先 ...
- Windows Phone开发(19):三维透视效果
原文:Windows Phone开发(19):三维透视效果 三维效果也可以叫透视效果,所以,我干脆叫三维透视效果.理论知识少讲,直接用例开场吧,因为这个三维效果其实很简单,比上一节中的变换更省事,不信 ...
- 微服务从设计到部署(二)使用 API 网关
链接:https://github.com/oopsguy/microservices-from-design-to-deployment-chinese 译者:Oopsguy 本书的七个章节是关于设 ...
随机推荐
- python-for表达式
for表达式用于其他区间,元组,列表等可迭代对象创建新的列表 [表达式 for 循环计数器 in 可迭代对象] for表达式与普通for循环的区别有两点 在for关键字之前定义一个表达式,该表达式通常 ...
- P1071 潜伏者(JAVA语言)
//HashMap大法好 题目描述 RR国和SS国正陷入战火之中,双方都互派间谍,潜入对方内部,伺机行动.历尽艰险后,潜伏于SS国的RR 国间谍小CC终于摸清了 SS 国军用密码的编码规则: 1. S ...
- 攻防世界 reverse 进阶5-7
5.re-for-50-plz-50 tu-ctf-2016 流程很简单,异或比较 1 x=list('cbtcqLUBChERV[[Nh@_X^D]X_YPV[CJ') 2 y=0x37 3 z= ...
- Python异步asyncio快速实践模版
只是参考快速跑起来模版,细节或者封装流畅使用需要详细阅读aiohttp文档 1 import asyncio 2 3 async def foo(): 4 await print('bar') 5 6 ...
- 复制文件--cp
cp file1 file2 将文件拷贝到指定路径下 cp -r dir1 dir2 将文件夹拷贝到指定路径下
- 3w 字长文爆肝 Java 基础面试题!太顶了!!!
hey guys ,这不是也到了面试季了么,cxuan 又打算重新写一下 Java 相关的面试题,先从基础的开始吧,这些面试题属于基础系列,不包含多线程相关面试题和 JVM 相关面试题,多线程和 JV ...
- BUAA防脱发第一抗连——团队介绍
项目 内容 这个作业属于哪个课程 2021学年春季软件工程(罗杰 任健) 这个作业的要求在哪里 团队项目-团队介绍 我在这个课程的目标是 锻炼在大规模开发中的团队协作能力 这个作业在哪个具体方面帮助我 ...
- redhat7.6 Tomcat下安装 Jenkins 安装wget文件下载
安装wget下载工具 # 查看是否安装wget rpm -qa | grep wget #使用yum安装wget yum -y install wget 使用wget工具下载到 /usr/share ...
- 简介TLS 1.3
0x00 前言 最近在阅读论文,其中阅读了 WWW2021的一篇文章"TLS 1.3 in Practice: How TLS 1.3 Contributes to the Internet ...
- Day05_20_Java中类的创建和对象的实例化
类的创建和对象的实例化 类的定义 类属于引用数据类型,java语言中所有的.class都属于引用数据类型 在类体当中,方法体之外定义的变量被称为 成员变量,成员变量没有赋值,系统默认是0: 语法结构: ...