【mysql】关联查询_子查询_排序分组优化
1. 关联查询优化
1.1 left join
结论:
①在优化关联查询时,只有在被驱动表上建立索引才有效!
②left join 时,左侧的为驱动表,右侧为被驱动表!
1.2 inner join
结论:inner join 时,mysql 会自己帮你把小结果集的表选为驱动表。
2. 子查询优化
结论: 在范围判断时,尽量不要使用not in 和not exists,使用left join on xxx is null 代替。
3. 排序分组优化
where 条件和on 的判断这些过滤条件,作为优先优化的部门,是要被先考虑的!其次,如果有分组和排序,那么
也要考虑grouo by 和order by。
3.1 无过滤,不索引
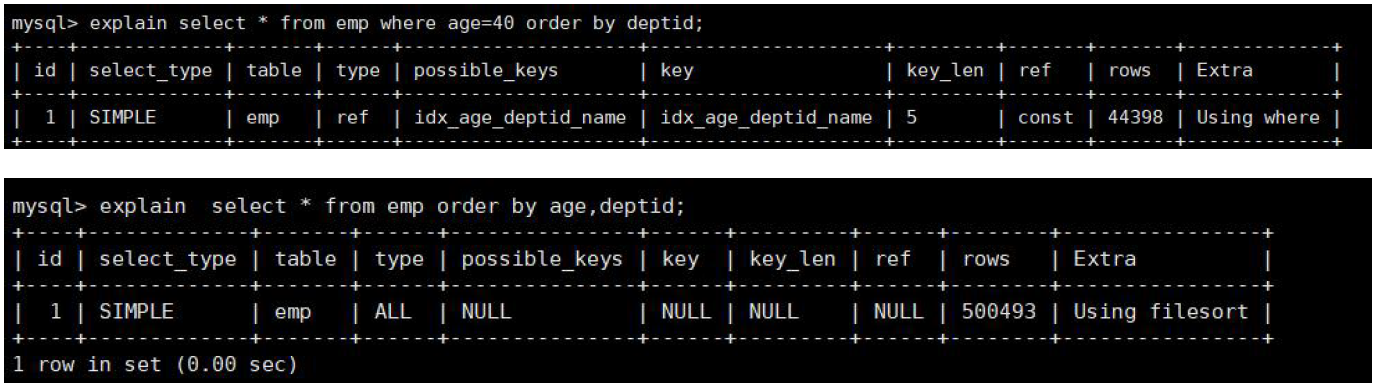
using filesort 说明进行了手工排序!原因在于没有where 作为过滤条件!

结论: 无过滤,不索引。where,limt 都相当于一种过滤条件,所以才能使用上索引!
3.2 顺序错,必排序


3.3 方向反,必排序
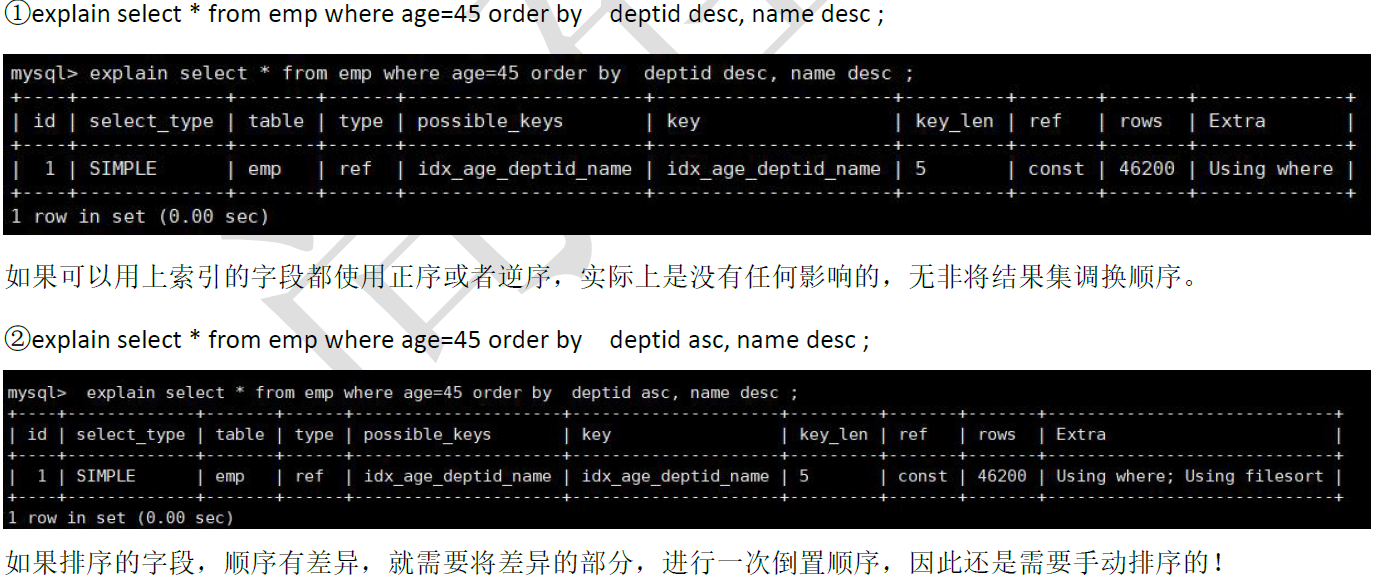
3.4 过滤和排序使用索引的选择
原因:所有的排序都是在条件过滤之后才执行的,所以如果条件过滤了大部分数据的话,几百几千条数据进行排序
其实并不是很消耗性能,即使索引优化了排序但实际提升性能很有限。相对的empno<101000 这个条件如果没
有用到索引的话,要对几万条的数据进行扫描,这是非常消耗性能的,使用empno 字段的范围查询,过滤性更好
(empno 从100000 开始)!
结论: 当范围条件和group by 或者order by 的字段出现二选一时,优先观察条件字段的过滤数量,如果过滤的
数据足够多,而需要排序的数据并不多时,优先把索引放在范围字段上。反之,亦然。
3.5 using filesort
mysql 的排序算法:
①双路排序
MySQL 4.1 之前是使用双路排序,字面意思就是两次扫描磁盘,最终得到数据,读取行指针和orderby 列,对他
们进行排序,然后扫描已经排序好的列表,按照列表中的值重新从列表中读取对应的数据输出。
从磁盘取排序字段,在buffer 进行排序,再从磁盘取其他字段。
简单来说,取一批数据,要对磁盘进行了两次扫描,众所周知,I\O 是很耗时的,所以在mysql4.1 之后,出现
了第二种改进的算法,就是单路排序。
②单路排序
从磁盘读取查询需要的所有列,按照order by 列在buffer 对它们进行排序,然后扫描排序后的列表进行输出,
它的效率更快一些,避免了第二次读取数据。并且把随机IO 变成了顺序IO,但是它会使用更多的空间,
因为它把每一行都保存在内存中了。
③单路排序的问题
由于单路是后出的,总体而言好过双路。但是存在以下问题:
在sort_buffer 中,方法B 比方法A 要多占用很多空间,因为方法B 是把所有字段都取出, 所以有可能取出的数
据的总大小超出了sort_buffer 的容量,导致每次只能取sort_buffer 容量大小的数据,进行排序(创建tmp 文件,多
路合并),排完再取取sort_buffer 容量大小,再排……从而多次I/O。
结论:本来想省一次I/O 操作,反而导致了大量的I/O 操作,反而得不偿失。
如何优化:
①增大sort_butter_size 参数的设置
不管用哪种算法,提高这个参数都会提高效率,当然,要根据系统的能力去提高,因为这个参数是针对每个进
程的1M-8M 之间调整。
②增大max_length_for_sort_data 参数的设置
mysql 使用单路排序的前提是排序的字段大小要小于max_length_for_sort_data。
提高这个参数,会增加用改进算法的概率。但是如果设的太高,数据总容量超出sort_buffer_size 的概率就增大,
明显症状是高的磁盘I/O 活动和低的处理器使用率。(1024-8192 之间调整)。
③减少select 后面的查询的字段。
当Query 的字段大小总和小于max_length_for_sort_data 而且排序字段不是TEXT|BLOB 类型时,会用改进后的
算法——单路排序, 否则用老算法——多路排序。
两种算法的数据都有可能超出sort_buffer 的容量,超出之后,会创建tmp 文件进行合并排序,导致多次I/O,
但是用单路排序算法的风险会更大一些,所以要提高sort_buffer_size。
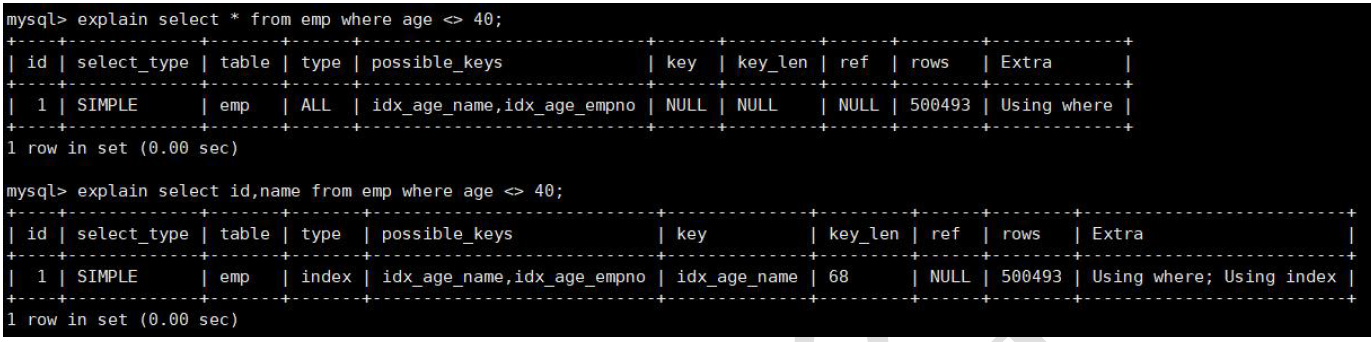
3.6 使用覆盖索引
覆盖索引:SQL 只需要通过索引就可以返回查询所需要的数据,而不必通过二级索引查到主键之后再去查询数据。
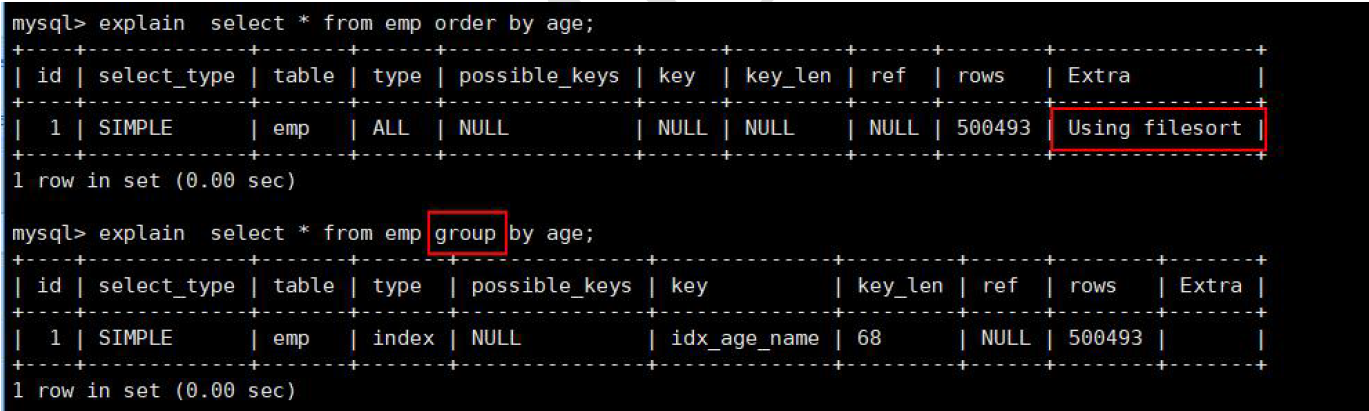
3.7 group by
group by 使用索引的原则几乎跟order by 一致,唯一区别是groupby 即使没有过滤条件用到索引,也可以直
接使用索引。
----尚硅谷_mysql_高级学习笔记
【mysql】关联查询_子查询_排序分组优化的更多相关文章
- mysql学习之路_联合查询与子查询
联合查询 联合查询:将多次查询(多条select语句)在记录上进行拼接(字段不会增加). 语法:多条select语句构成,每条select语句获取的字段必须严格一致(但是字段类型无关). Select ...
- mysql查询语句 和 多表关联查询 以及 子查询
原文地址: http://blog.csdn.net/github_37767025/article/details/67636061 1.查询一张表: select * from 表名: 2.查询指 ...
- SQL基本查询_子查询(实验四)
SQL基本查询_子查询(实验四) 1.查询所有员工中薪水低于"孙军"的员工姓名和薪水: 2.查询与部门编号为"01"的岗位相同的员工姓名.岗位.薪水及部门号: ...
- 多表查询_子查询概述和多表查询_子查询情况1&情况2&情况3
子查询 概念:查询中嵌套查询,称嵌套查询为子查询 -- 查询工资最高的员工信息 -- 1.查询最高的工资是多少 9000 select max(salary) from emp; -- 查询员工信息, ...
- mysql的查询、子查询及连接查询
>>>>>>>>>> 一.mysql查询的五种子句 where(条件查询).having(筛选).group by(分组). ...
- 从项目上一个子查询扩展学习开来:mysql的查询、子查询及连接查询
上面这样的数据,想要的结果是:如果matchResult为2的话,代表是黑名单.同一个softId,version,pcInfoId的代表是同一个软件,需要去重:同时,如果相同软件里面只要有一个mat ...
- [转]mysql的查询、子查询及连接查询
转自:http://www.cnblogs.com/rollenholt/archive/2012/05/15/2502551.html 一.mysql查询的五种子句 where(条件 ...
- MySQL (六)--外键、联合查询、子查询
1 外键 外键:foreign key,外面的键(键不在自己表中),如果一张表中有一个字段(非主键)指向另外一张表的主键,那么将该字段称为外键. 1.1 增加外键 外键可以在创建表的时候或创建表之后增 ...
- mysql 外键和子查询,视图
1.mysql 外键约束 建表时生成外键 foreing key ('sid') references' student'('id'); 建表后添加外键 alter table' course ...
随机推荐
- ES6新增语法(五)——Promise详解
Promise介绍 promise是一个对象,从它可以获取异步操作的消息.有all.race.reject.resolve这几个方法,原型上有then.catch等方法. Promise的两个特点: ...
- [刘阳Java]_EasyUI环境搭建_第2讲
在EasyUI的第1讲中我们介绍了学习EasyUI能够做什么,这次我们得快速搭建一个EasyUI环境,来测试一下它的运行效果 1.jQuery EasyUI环境搭建 <script type=& ...
- Spring总结之SpringMvc下
五.拦截器 SpringMVC中的拦截器是通过HandlerInterceptor来实现的,定义一个Interceptor有两种方式 1.实现HandlerInterceptor接口或者继承实现了Ha ...
- 使用mvn命令将pom和jar上传至nexus私服
要将自定义的jar或者pom上传至nexus私服,需要配置maven的settings文件! 上传至nexus私服配置 1. settings配置 <!-- maven设置私服对应的信息:id. ...
- npm 安装、卸载模块
npm安装模块 [npm install xxx]利用 npm 安装xxx模块到当前命令行所在目录:[npm install -g xxx]利用npm安装全局模块xxx:本地安装时将模块写入packa ...
- GeoServer Rest服务启动匿名认证的配置方法
GeoServer Rest服务数据默认需要进行用户名.密码的认证,如不需进行该认证,则启动匿名认证即可,配置方式如下(针对war包发布的GeoServer应用): 在GeoServer war包的解 ...
- Linux chgrp命令的使用
Linux chgrp(change group)命令用于变更文件或目录的所属群组. 语法 chgrp [-cfhRv][--help][--version][所属群组][文件或目录...] 或 ch ...
- Java 中 this 和 super 的用法详解
前言 这次我们来回顾一下this和super这两个关键字的用法,作为一名Java程序员,我觉得基础是最重要的,因为它决定了我们的上限,所以我的文章大部分还是以分享Java基础知识为主,学好基础,后面的 ...
- mysql安装简书
mysql下载地址:https://dev.mysql.com/downloads/mysql/ mysql可视化工具下载地址:https://dev.mysql.com/downloads/work ...
- 17Java进阶——反射、进程、Java11新特性
1.Java反射机制 Java反射(Reflection)概念:在运行时动态获取类的信息以及动态调用对象方法的功能. 1.1反射的应用--通过全类名获取类对象及其方法 package two.refl ...