【Scrapy(四)】scrapy 分页爬取以及xapth使用小技巧
scrapy 分页爬取以及xapth使用小技巧
这里以爬取www.javaquan.com为例:
1.构建出下一页的url:
很显然通过dom树,可以发现下一页所在的a标签
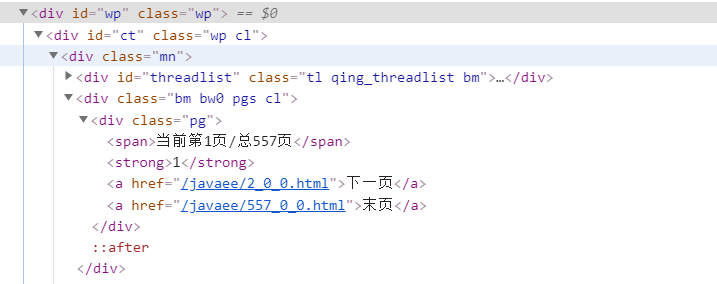
2.使用scrapy的yield scrapy.Reqeust(next_url,callback=self.parse) 构造下一页爬取的请求

Tips:使用xpath解析dom的常用处理方法:
1.查询页面上所有的div元素 : //div
2.查询页面上指定的元素 :
-通过class属性定位 例如: div[@class='xxxx']
-通过其他属性去定位 例如 div[@size='xxxxx']
-通过元素包含的文本去定位 例如: a[contains(string(),'下一页')]
3.获取标签中的文本: 例如: /a/text() 获取a标签中得到文本
4.获取标签中的属性值: 例如/a/@href
5.extract_first() 与 extract() 区别
extract_first() 解析标签的值,取第一个
extract() 解析标签的值,取所有值
6.url返回的dom结构,可能与页面显示的dom结构不一致,chrome调试时需要注意,例如tbody的问题
7.获取某个标签下的所有子标签可以使用列表 例如 response.xpath("//tbody[@id='normalthread_14']/tr")[0:-1]
【Scrapy(四)】scrapy 分页爬取以及xapth使用小技巧的更多相关文章
- 基于scrapy框架输入关键字爬取有关贴吧帖子
基于scrapy框架输入关键字爬取有关贴吧帖子 站点分析 首先进入一个贴吧,要想达到输入关键词爬取爬取指定贴吧,必然需要利用搜索引擎 点进看到有四种搜索方式,分别试一次,观察url变化 我们得知: 搜 ...
- Scrapy爬虫框架之爬取校花网图片
Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设 ...
- scrapy之360图片爬取
#今日目标 **scrapy之360图片爬取** 今天要爬取的是360美女图片,首先分析页面得知网页是动态加载,故需要先找到网页链接规律, 然后调用ImagesPipeline类实现图片爬取 *代码实 ...
- 如何分页爬取数据--beautisoup
'''本次爬取讲历史网站'''#!usr/bin/env python#-*- coding:utf-8 _*-"""@author:Hurrican@file: 分页爬 ...
- 爬虫(十七):Scrapy框架(四) 对接selenium爬取京东商品数据
1. Scrapy对接Selenium Scrapy抓取页面的方式和requests库类似,都是直接模拟HTTP请求,而Scrapy也不能抓取JavaScript动态谊染的页面.在前面的博客中抓取Ja ...
- scrapy 的分页爬取 CrawlSpider
1.创建scrapy工程:scrapy startproject projectName 2.创建爬虫文件:scrapy genspider -t crawl spiderName www.xxx.c ...
- 爬虫系列---scrapy全栈数据爬取框架(Crawlspider)
一 简介 crawlspider 是Spider的一个子类,除了继承spider的功能特性外,还派生了自己更加强大的功能. LinkExtractors链接提取器,Rule规则解析器. 二 强大的链接 ...
- Scrapy-redis改造scrapy实现分布式多进程爬取
一.基本原理: Scrapy-Redis则是一个基于Redis的Scrapy分布式组件.它利用Redis对用于爬取的请求(Requests)进行存储和调度(Schedule),并对爬取产生的项目(it ...
- Scrapy中用xpath/css爬取豆瓣电影Top250:解决403HTTP status code is not handled or not allowed
好吧,我又开始折腾豆瓣电影top250了,只是想试试各种方法,看看哪一种的方法效率是最好的,一直进行到这一步才知道 scrapy的强大,尤其是和selector结合之后,速度飞起.... 下面我就采用 ...
随机推荐
- 后端程序员之路 34、Index搜索引擎实现分析3-对文章索引的两层分块
# part_indexer 对文章根据id的hash进行分块索引- 持有 search_index _inc_index[2]; search_index _history_index[2]; 进行 ...
- CCF(管道清洁):最小费用最大流
管道清洁 201812-5 需要清洁的管道下界为1, 不需要清洁的管道下界为0, 可重复经过的管道上界为正无穷, 不可重复经过的管道上界为1. 这属于无源无汇的有容量下界的最小费用可行流.解决的方法就 ...
- java下载文件指定目录下的文件
方法一: @RequestMapping('download')def download(HttpServletRequest request, HttpServletResponse respons ...
- 使用函数式语言实践DDD
长期以来我都在实践OOP,进而通过OOP来实现DDD,特别是如何通过面向对象的技巧来建立一个领域模型.OO的一些特性在建立领域模型时显得恰如其分,能否掌握OO的技巧,对创建领域模型有着至关重要的作用. ...
- CSS行内元素盒模型
1 <!DOCTYPE html> 2 <html lang="en"> 3 <head> 4 <meta charset="U ...
- IPFS矿池集群方案详解
IPFS作为一项分布式存储技术,可以说是web3.0发展的基石.关于IPFS的产业,如存储.技术.矿机.矿池等也发展得非常迅速. 什么是单机挖矿? 单机挖矿就是一台机器就是一个节点,一台机器就完成挖矿 ...
- 2018ICPC南京K. Kangaroo Puzzle
题目:在一个20×20的地图上,1表示有袋鼠,0表示有障碍物,边界外和障碍物上不能走. 要求给出一个50000步以内的操作,每一步操作为'L', 'R', 'U', 'D', 表示所有袋 ...
- Ingress-nginx工作原理和实践
本文记录/分享 目前项目的 K8s 部署结构和请求追踪改造方案 这个图算是一个通用的前后端分离的 k8s 部署结构: Nginx Ingress 负责暴露服务(nginx前端静态资源服务), 根据十二 ...
- crackme001
最近在学习C语言的语法,今天因为早上起来得太早,导致一整天状态都不是很好,索性就没有继续,就拿了个最简单的crackme练练手 首先跑一下程序,看下报错 PE查壳,发现是一个啥子delphi的东西,没 ...
- Golang学习的方法和建议
学习方法: 学习方向:go方向是没有问题的 学习方法:多思考多练习,注重语法和关键词练习,切记哑巴学习,会看不会写,切记注意多写 课外学习,数据结构和算法:清华 谭浩强老师(链表.数组.排序...等等 ...