大数据学习(25)—— 用IDEA搭建Spark开发环境
IDEA是一个优秀的Java IDE工具,它同样支持其他语言。Spark是用Scala语言编写的,用Scala开发Spark是最舒畅的。当然,Spark也提供Java和Python的API。
Java是一门热度很高的开发语言,也是一个高龄语言。Java本身很牛逼,但它最牛逼的地方是——成就了JVM。
基于JVM的语言非常多,常用的除了Java还有Scala、Groovy、Kotlin、Clojure。能编译成字节码的语言,都能在JVM上运行。
Scala
Scala 是一门多范式(multi-paradigm)的编程语言,设计初衷是要集成面向对象编程和函数式编程的各种特性。
Scala 运行在 Java 虚拟机上,并兼容现有的 Java 程序。
Scala 源代码被编译成 Java 字节码,所以它可以运行于 JVM 之上,并可以调用现有的 Java 类库。
与JAVA的区别
我们学习的是大数据,重点不在于Scala用的有多么溜,够用就行。作为一个从Java上手的码农,我感觉Java是一个古板先生,语言和语法都规规矩矩,显得有点儿臃肿。Scala像一个翩翩少年,没那么多束缚,语法天马行空,用行话说就是“有很甜的语法糖”,一个API可以做很多事。用惯了Scala的数据集操作,简直就不想再用Java的那一套,什么都要自己写,太麻烦了。当然,想招聘一个精通Scala的人,这个难度比招一个精通Java的人要大得多,毕竟用的人少。
IDEA安装Scala插件
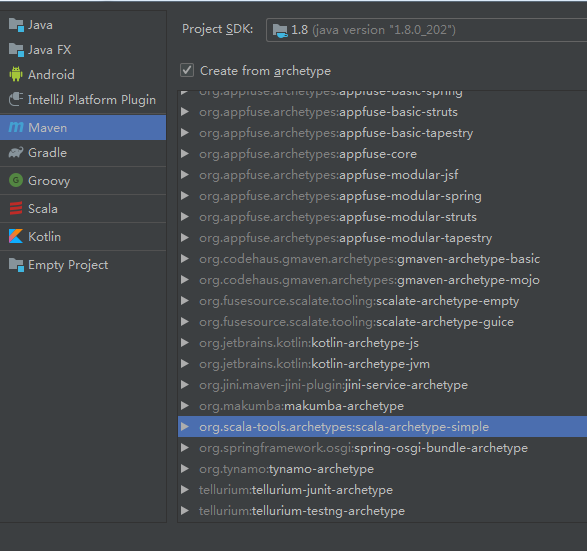
创建Scala Maven项目
建好项目把App、AppTest、MySpec三个类删掉。修改pom文件里scala的版本号。
<properties>
<scala.version>2.12.0</scala.version>
</properties>
引入spark-core依赖。
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.1.2</version>
</dependency>
编写Scala代码
环境配好之后,可以写代码了。创建一个Scala的Object,它可以运行main方法。
package com.xy
import org.apache.spark.{SparkConf, SparkContext}
object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Test").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("ERROR")
val rdd = sc.parallelize(Array(1,2,3,2,1,4,5,2))
val kv = rdd.map(x=>(x,1)).reduceByKey(_+_)
kv.foreach(println)
}
}
从(1,2,3,2,1,4,5,2)这个数据集里计算每个数字出现的次数,运行结果如下。
(4,1)
(1,2)
(3,1)
(5,1)
(2,3) Process finished with exit code 0
大数据学习(25)—— 用IDEA搭建Spark开发环境的更多相关文章
- PyCharm搭建Spark开发环境 + 第一个pyspark程序
一, PyCharm搭建Spark开发环境 Windows7, Java 1.8.0_74, Scala 2.12.6, Spark 2.2.1, Hadoop 2.7.6 通常情况下,Spark开发 ...
- Intellij IDEA使用Maven搭建spark开发环境(scala)
如何一步一步地在Intellij IDEA使用Maven搭建spark开发环境,并基于scala编写简单的spark中wordcount实例. 1.准备工作 首先需要在你电脑上安装jdk和scala以 ...
- 大数据学习系列之八----- Hadoop、Spark、HBase、Hive搭建环境遇到的错误以及解决方法
前言 在搭建大数据Hadoop相关的环境时候,遇到很多了很多错误.我是个喜欢做笔记的人,这些错误基本都记载,并且将解决办法也写上了.因此写成博客,希望能够帮助那些搭建大数据环境的人解决问题. 说明: ...
- Intellij Idea搭建Spark开发环境
在Spark高速入门指南 – Spark安装与基础使用中介绍了Spark的安装与配置.在那里还介绍了使用spark-submit提交应用.只是不能使用vim来开发Spark应用.放着IDE的方便不用. ...
- 大数据学习系列之Hadoop、Spark学习线路(想入门大数据的童鞋,强烈推荐!)
申明:本文出自:http://www.cnblogs.com/zlslch/p/5448857.html(该博客干货较多) 1 Java基础: 视频方面: 推荐<毕向东JAVA ...
- 大数据学习——HADOOP集群搭建
4.1 HADOOP集群搭建 4.1.1集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主 ...
- 大数据学习——hadoop集群搭建2.X
1.准备Linux环境 1.0先将虚拟机的网络模式选为NAT 1.1修改主机名 vi /etc/sysconfig/network NETWORKING=yes HOSTNAME=itcast ### ...
- 大数据学习之scala-环境搭建
scala 下载网站 https://www.scala-lang.org/download/ 安装scala要先安装java,并且配置java环境,官网也有说明 不过国内的网站下载不下来可以访问: ...
- 大数据学习——Storm集群搭建
安装storm之前要安装zookeeper 一.安装storm步骤 1.下载安装包 2.解压安装包 .tar.gz storm 3.修改配置文件 mv /root/apps/storm/conf/st ...
随机推荐
- [源码解析] 深度学习分布式训练框架 horovod (7) --- DistributedOptimizer
[源码解析] 深度学习分布式训练框架 horovod (7) --- DistributedOptimizer 目录 [源码解析] 深度学习分布式训练框架 horovod (7) --- Distri ...
- Golang限制函数调用次数
Golang限制函数调用次数 项目环境 ubuntu+go1.14 需求描述 限制某个函数5秒内只能调用一次,5秒内的其他调用抛弃 工具包使用 这里用到了官方限流器/time/rate 该限流器是基于 ...
- Centos7搭建内网DNS服务器
一.配置阿里云yum源 执行脚本配置阿里云的yum源,已配置yum源的可以忽略 #!/bin/bash # ******************************************** ...
- Arduino库和STM32的寄存器、标准库、HAL库、LL库开发比较之GPIO
标题: Arduino库和STM32的寄存器.标准库.HAL库.LL库开发比较之GPIO 作者: 梦幻之心星 sky-seeker@qq.com 标签: [#Arduino,#STM32,#库,#开发 ...
- 『动善时』JMeter基础 — 51、使用JMeter测试WebService接口
目录 1.什么是WebService 2.WebService和SOAP的关系 3.什么是WSDL 4.测试WebService接口前的准备 (1)如何判断是WebService接口 (2)如何获取W ...
- upload-labs通关记录
upload-labs通关记录 一句话木马解读 一般的解题步骤 或者可以直接用字典爆破一下 https://github.com/TheKingOfDuck/fuzzDicts/blob/master ...
- JS刷新窗口的几种方式
浮层内嵌iframe及frame集合窗口,刷新父页面的多种方法 <script language=JavaScript> parent.location.reload(); ...
- Libevent2.1.8版在Liunx中编译安装遇到的问题
Libevent2.1.8版在Liunx中编译安装遇到的问题 前言:在网上找了很久,都没有一个明确的解决方法,通过分析可能的原因,将自己实际操作及解决的成功结果记录如下,以供遇到相似的问题,能提供思路 ...
- WPF教程十:如何使用Style和Behavior在WPF中规范视觉样式
在使用WPF编写客户端代码时,我们会在VM下解耦业务逻辑,而剩下与功能无关的内容比如动画.视觉效果,布局切换等等在数量和复杂性上都超过了业务代码.而如何更好的简化这些编码,WPF设计人员使用了Styl ...
- android实现计时器(转)
新建布局文件activity_main.xml <?xml version="1.0" encoding="utf-8"?> <Linea ...