大数据学习——Storm集群搭建
安装storm之前要安装zookeeper
一.安装storm步骤
1.下载安装包

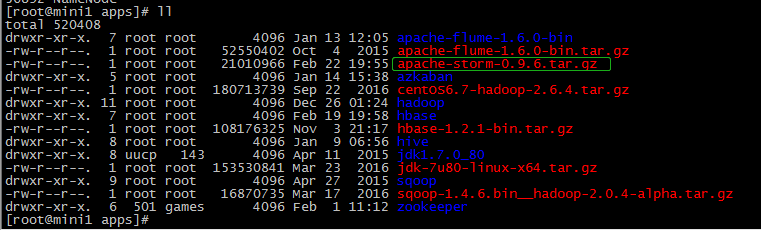
2.解压安装包
tar -zxvf apache-storm-0.9..tar.gz mv apache-storm-0.9. storm
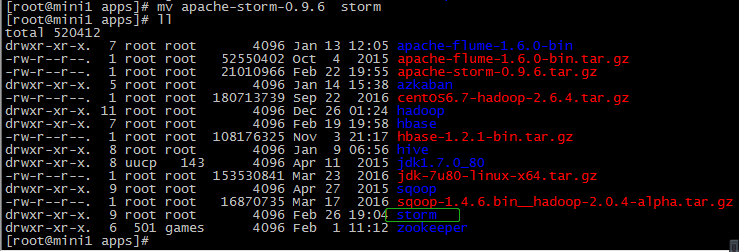
3.修改配置文件
mv /root/apps/storm/conf/storm.yaml /root/apps/storm/conf/storm.yaml.bak vi /root/apps/storm/conf/storm.yaml
修改环境变量/etc/profile
export STORM_HOME=/root/apps/storm
export PATH=${STORM_HOME}/bin:$PATH
#指定storm使用的zk集群
storm.zookeeper.servers:
- "mini1"
- "mini2"
- "mini3"
#指定storm集群中的nimbus节点所在的服务器
nimbus.host: "mini1"
#指定nimbus启动JVM最大可用内存大小
nimbus.childopts: "-Xmx1024m"
#指定supervisor启动JVM最大可用内存大小
supervisor.childopts: "-Xmx1024m"
#指定supervisor节点上,每个worker启动JVM最大可用内存大小
worker.childopts: "-Xmx768m"
#指定ui启动JVM最大可用内存大小,ui服务一般与nimbus同在一个节点上。
ui.childopts: "-Xmx768m"
#指定supervisor节点上,启动worker时对应的端口号,每个端口对应槽,每个槽位对应一个worker
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
4.分发安装包
scp -r $PWD mini2:$PWD
scp -r $PWD mini3:$PWD
5.启动集群
storm的集群中的是三个角色
nimbus 主节点,管理节点
supervisor每个机器上的管理者
ui界面
mini1的/root/apps/storm/bin目录下
./storm nimbus
./storm supervisor
./storm ui mini2的/root/apps/storm/bin目录下
./storm supervisor mini3的/root/apps/storm/bin目录下
./storm supervisor
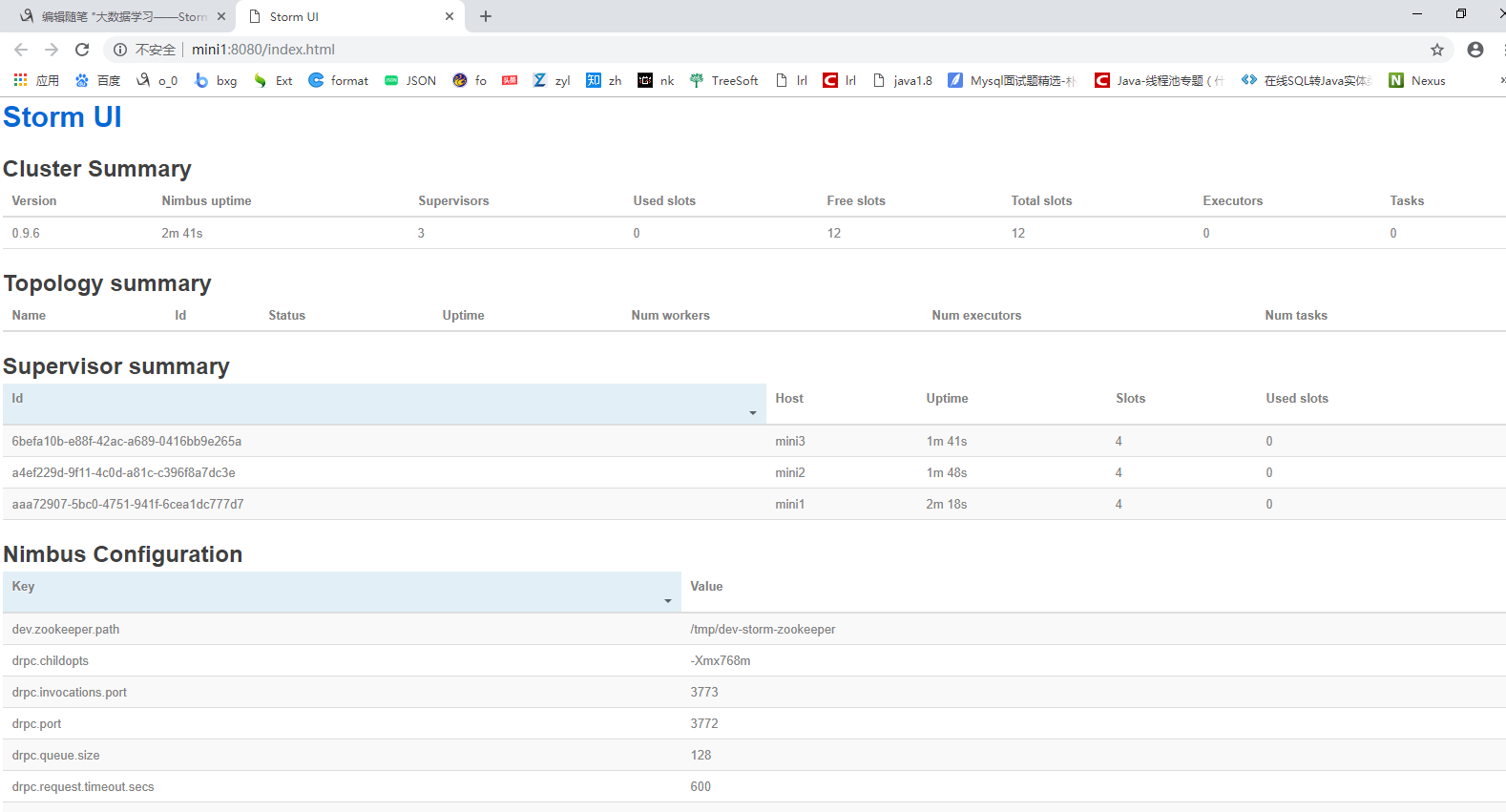
6.查看集群
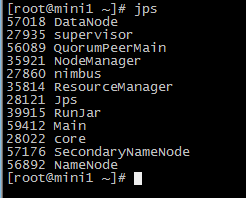
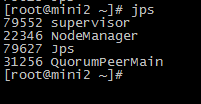
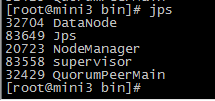
http://mini1:8080/index.html
大数据学习——Storm集群搭建的更多相关文章
- 大数据学习——HADOOP集群搭建
4.1 HADOOP集群搭建 4.1.1集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主 ...
- 大数据学习——hadoop集群搭建2.X
1.准备Linux环境 1.0先将虚拟机的网络模式选为NAT 1.1修改主机名 vi /etc/sysconfig/network NETWORKING=yes HOSTNAME=itcast ### ...
- 大数据中Hadoop集群搭建与配置
前提环境是之前搭建的4台Linux虚拟机,详情参见 Linux集群搭建 该环境对应4台服务器,192.168.1.60.61.62.63,其中60为主机,其余为从机 软件版本选择: Java:JDK1 ...
- 大数据中HBase集群搭建与配置
hbase是分布式列式存储数据库,前提条件是需要搭建hadoop集群,需要Zookeeper集群提供znode锁机制,hadoop集群已经搭建,参考 Hadoop集群搭建 ,该文主要介绍Zookeep ...
- 大数据平台Hadoop集群搭建
一.概念 Hadoop是由java语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,其核心部件是HDFS与MapReduce.HDFS是一个分布式文件系统,类似mogilef ...
- 大数据-HBase HA集群搭建
1.下载对应版本的Hbase,在我们搭建的集群环境中选用的是hbase-1.4.6 将下载完成的hbase压缩包放到对应的目录下,此处我们的目录为/opt/workspace/ 2.对已经有的压缩包进 ...
- 大数据:spark集群搭建
创建spark用户组,组ID1000 groupadd -g 1000 spark 在spark用户组下创建用户ID 2000的spark用户 获取视频中文档资料及完整视频的伙伴请加QQ群:9479 ...
- 大数据学习——Kafka集群部署
1下载安装包 2解压安装包 -0.9.0.1.tgz -0.9.0.1 kafka 3修改配置文件 cp server.properties server.properties.bak # Lice ...
- 大数据学习——hdfs集群启动
第一种方式: 1 格式化namecode(是对namecode进行格式化) hdfs namenode -format(或者是hadoop namenode -format) 进入 cd /root/ ...
随机推荐
- IIS网站设置禁止IP访问设置方法
本文设置系统为Windows2003.IIS版本是6.0. 打开IIS管理器,在iis管理器左侧单击打开网站下面的相应需要设置的网站,并在此网站上右键,选择属性,即可打开该网站属性进行相关设置. (i ...
- 在WIN7、WIN8中,将快捷方式锁定到任务栏,C#
其实很简单,使用 API 函数 ShellExecute,就可以解决这个问题. 首先添加引用 using System.Runtime.InteropServices; 代码如下: using Sys ...
- hasNextInt()方法
hasNextInt()方法是判断控制台接收是否为数字,当你在控制台输入一个字符的时候,hasNextInt()判断你输入这个字符是不是数字,而不是接收值,当if判断通过之后执行接收,也就是你输入的那 ...
- 基于Servlet+smartUpload的文件上传
文件上传在web应用中是非常常见的,现在我就介绍下基于servlet的文件上传,基于Struts2的文件上传可以看: 页面端代码: <%@ page language="java&qu ...
- THML5新增功能
HTML5新增功能 1.语义化标记: 1)article:article标签装载显示一个独立的文章内容.例如一篇完整的论坛帖子,一则网站新闻,一篇博客文章等等,一个用户评论等等 artilce可以嵌套 ...
- 利用基于@AspectJ的AOP实现权限控制
一. AOP与@AspectJ AOP 是 Aspect Oriented Programming 的缩写,意思是面向方面的编程.我们在系统开发中可以提取出很多共性的东西作为一个 Aspect,可以理 ...
- ZOJ 3626 Treasure Hunt I (树形DP,常规)
题意:给一棵树,一个人站在节点s,他有m天时间去获取各个节点上的权值,并且最后需要回到起点s,经过每条边需要消耗v天,问最少能收获多少权值? 思路: 常规的,注意还得跑回原地s. //#include ...
- NBUT 1114 Alice's Puppets(排序统计,水)
题意:给一棵人名树,按层输出,同层则按名字的字典序输出. 思路:首先对每个人名做索引,确定其在哪一层,按层装进一个set,再按层输出就自动排好序了. #include <bits/stdc++. ...
- 微软OneDrive使用体验
OneDrive是微软推出的一款软件,提供类似百度网盘的功能,能够在线存储照片和文档, 号称从任意电脑.Mac 电脑或手机都可访问. 一起来看看吧,第一次用之前需要进行简单配置. 因为是一个同步盘,需 ...
- java 读取文件转换成字符串
public String readFromFile(File src) { try { BufferedReader bufferedReader = new BufferedReader(new ...