特征向量、特征值以及降维方法(PCA、SVD、LDA)
一、特征向量/特征值
Av = λv
如果把矩阵看作是一个运动,运动的方向叫做特征向量,运动的速度叫做特征值。对于上式,v为A矩阵的特征向量,λ为A矩阵的特征值。
假设:v不是A的速度(方向)
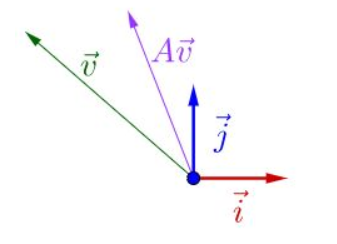
结果如上,不能满足上式的。
二、协方差矩阵
方差(Variance)是度量一组数据分散的程度。方差是各个样本与样本均值的差的平方和的均值。
协方差(Covariance)是度量两个变量的变动的同步程度,也就是度量两个变量线性相关性程度。如果两个变量的协方差为0,则统计学上认为二者线性无关。而方差是协方差的一种特殊情况,即当两个变量是相同的情况。
三、主成分分析法(PCA)
特征降维一般有两类方法:特征选择和特征抽取。特征选择即从高纬度的特征中选择其中的一个子集来作为新的特征;而特征抽取是指将高纬度的特征经过某个函数映射至低纬度作为新的特征。常用的特征抽取方法就是PCA。主成分分析法(PCA)是常用的一种降维方法。对于正交属性空间中的样本点,如何用一个超平面对所有的样本进行恰当的表达?
1、最近重构性,样本到这个超平面的距离都足够近
2、最大可分性,样本点到这个超平面上的投影能尽可能分开
首先:假设数据样本进行了中心化(对所有样本进行中心化,对每个维度减去这个维度的数据均值),假设投影变换得到的新坐标系为{w1,w2,...,wi},W为标准正交向量基,||wi||2=1,wiTwj=0(i!=j),对于样本点xi到超频面的投影为WTxi,若所有样本点的投影尽可能分开,则投影后的样本点方差应该最大。
投影后的方差:∑WTxixiTW,于是目标函数为:
max WTXXTW s.t. WTW=I
等价 min (-max)
采用拉格朗日乘子法:
F = -WTXXTW +λ(I-WTW)
∂F/∂W = 0 推导出:
XXTwi = λiwi
此时,只要对协方差XXT 进行特征值分解,求得特征值以及特征向量的排序,λ1 ≥λ2 .... λi,对应的W的排序就为主成分分析的解。
实际上,PCA主成分分析的求解或者说解释是通过拉格朗日乘子法进行推到的,只不过求解结果可以通过求解特征值的形式进行求解。而从特征值的角度来看,特征值和特征向量反映了协方差的变化规律。
四、PCA流程
- 对数据去中心化
- 计算XXT,注:这里除或不除样本数量M或M−1其实对求出的特征向量没影响
- 对XXT进行特征分解
- 选取特征值最大的几个维度进行数据映射。(去掉较小的维度)
下面,可以通过代码看PCA降维如何操作的:
import numpy as np
from sklearn.decomposition import PCA
#零均值化
def zeroMean(dataMat):
meanVal=np.mean(dataMat,axis=0) #按列求均值,即求各个特征的均值
newData=dataMat-meanVal
return newData,meanVal def pca(dataMat,n):
newData,meanVal=zeroMean(dataMat)
covMat=np.cov(newData,rowvar=0) #求协方差矩阵,return ndarray;若rowvar非0,一列代表一个样本,为0,一行代表一个样本 eigVals,eigVects=np.linalg.eig(np.mat(covMat))#求特征值和特征向量,特征向量是按列放的,即一列代表一个特征向量
#print(eigVals)
#argsort将x中的元素从小到大排列,提取其对应的index(索引)
eigValIndice=np.argsort(eigVals) #对特征值从小到大排序
#print(eigValIndice)
n_eigValIndice=eigValIndice[-1:-(n+1):-1] #最大的n个特征值的下标
n_eigVect=eigVects[:,n_eigValIndice] #最大的n个特征值对应的特征向量
lowDDataMat=newData*n_eigVect #低维特征空间的数据
reconMat=(lowDDataMat*n_eigVect.T)+meanVal #重构数据
return lowDDataMat,reconMat dataMat = np.array([i for i in range(100)]).reshape(10,10) data ,mat = pca(dataMat,2)
print(data)
p = PCA(n_components=2)
main_vector = p.fit_transform(dataMat)
print(main_vector)
如上,可以看到PCA的实现过程,但是我们自己实现的PCA的结果和sklearn实现的结果不一样,是因为sklearn中的PCA实际上是通过SVD实现的。
五、奇异值分解(SVD)
奇异值分解是一种重要的矩阵分解方法。
假设A是一个mxn的矩阵,则存在一个分解使得
Amn = Umm∑mnVnnT
与特征值、特征向量概念相对应,则:
∑对角线上的元素成为矩阵A的奇异值,U和V称为A的左右奇异向量矩阵。
左奇异向量用于压缩行,右奇异向量压缩列。压缩方法均是取奇异值较大的左奇异向量或者右奇异向量与原数据C相乘。
PCA是从特征方向去降维,而SVD从特征和实例两个方向降维。
SVD计算过程:假设原数据为X,一行代表一个样本,列代表特征。
1)计算X'X,XX';
2)对XX'进行特征值分解,得到的特征向量组成u,lambda_u;
3)对X'X进行特征值分解,得到的特征向量组成v,lambda_v;
4)lambda_u,lambda_v的重复元素开方组成对角矩阵sigma主对角线上的元素;
六、LDA降维方法
LDA(线性判别分析)是一种基于分类模型进行特征属性合并的操作,是一种有监督的降维方法。 在sklearn中本质就是SVD分解的左奇异矩阵乘以原来的矩阵,达到降实例的目的。该过程可以通过k-means同样实现。
LDA用于分类问题:
import numpy as np
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
y = np.array([1, 1, 1, 2, 2, 2])
clf = LinearDiscriminantAnalysis()
clf.fit(X, y)
print(clf.predict([[-0.8, -1]]))
LDA用于降维:
lda = LinearDiscriminantAnalysis(n_components=2)
lda.fit(X,y)
X_new = lda.transform(X)
七、PCA与LDA对比以及应用场景
PCA与LDA效果对比可以参考:http://scikit-learn.org/stable/auto_examples/decomposition/plot_pca_vs_lda.html#sphx-glr-auto-examples-decomposition-plot-pca-vs-lda-py
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from sklearn.datasets.samples_generator import make_classification
from sklearn.decomposition import PCA
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
# X1为样本特征,Y1为样本类别输出, 共400个样本,每个样本3个特征,输出有3个类别,没有冗余特征,每个类别一个簇
X, Y = make_classification(n_samples=400, n_features=3, n_redundant=0,
n_clusters_per_class=1, n_classes=3,random_state = 7)
fig = plt.figure()
ax = Axes3D(fig)
plt.scatter(X[:, 0], X[:, 1], X[:, 2],linewidths=5,marker='o',c=Y)
plt.show() # PCA降维
pca = PCA(n_components=2)
pca.fit(X)
X_new = pca.transform(X)
plt.scatter(X_new[:, 0], X_new[:, 1],marker='o',c=Y)
plt.show() #LDA降维
lda = LinearDiscriminantAnalysis(n_components=2)
lda.fit(X,Y)
X_new = lda.transform(X)
plt.scatter(X_new[:, 0], X_new[:, 1],marker='o',c=Y)
plt.show()

|
PCA |
LDA |

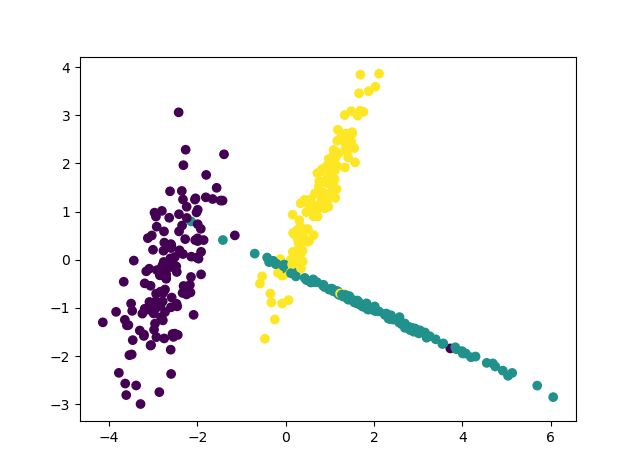
PCA映射是一种将高维数据合并到低维的过程,样本具有更大的发散性;LDA考虑了样本的标注,即希望投影后,不同类别之间的距离最大,可以用于降维和分类。
- 一般情况下,有类别信息时,可以采用LDA
- 无类别信息,不知道样本属于哪个类,用PCA
特征向量、特征值以及降维方法(PCA、SVD、LDA)的更多相关文章
- 降维方法PCA与SVD的联系与区别
在遇到维度灾难的时候,作为数据处理者们最先想到的降维方法一定是SVD(奇异值分解)和PCA(主成分分析). 两者的原理在各种算法和机器学习的书籍中都有介绍,两者之间也有着某种千丝万缕的联系.本文在简单 ...
- 降维【PCA & SVD】
PCA(principle component analysis)主成分分析 理论依据 最大方差理论 最小平方误差理论 一.最大方差理论(白面机器学习) 对一个矩阵进行降维,我们希望降维之后的每一维数 ...
- 特征选取方法PCA与LDA
一.主成分分析(PCA)介绍 什么是主成分分析? 主成分分析是一种用于连续属性降维的方法,把多指标转化为少数几个综合指标. 它构造了原始属性的一个正交变换,将一组可能相关的变量转化为一组不相关的变 ...
- # 机器学习算法总结-第五天(降维算法PCA/SVD)
- 机器学习降维方法概括, LASSO参数缩减、主成分分析PCA、小波分析、线性判别LDA、拉普拉斯映射、深度学习SparseAutoEncoder、矩阵奇异值分解SVD、LLE局部线性嵌入、Isomap等距映射
机器学习降维方法概括 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/u014772862/article/details/52335970 最近 ...
- matlab 工具之各种降维方法工具包,下载及使用教程,有PCA, LDA, 等等。。。
最近跑深度学习,提出的feature是4096维的,放到我们的程序里,跑得很慢,很慢.... 于是,一怒之下,就给他降维处理了,但是matlab 自带的什么pca( ), princomp( )函数, ...
- 机器学习笔记----四大降维方法之PCA(内带python及matlab实现)
大家看了之后,可以点一波关注或者推荐一下,以后我也会尽心尽力地写出好的文章和大家分享. 本文先导:在我们平时看NBA的时候,可能我们只关心球员是否能把球打进,而不太关心这个球的颜色,品牌,只要有3D效 ...
- 四大机器学习降维算法:PCA、LDA、LLE、Laplacian Eigenmaps
四大机器学习降维算法:PCA.LDA.LLE.Laplacian Eigenmaps 机器学习领域中所谓的降维就是指采用某种映射方法,将原高维空间中的数据点映射到低维度的空间中.降维的本质是学习一个映 ...
- 【转】四大机器学习降维算法:PCA、LDA、LLE、Laplacian Eigenmaps
最近在找降维的解决方案中,发现了下面的思路,后面可以按照这思路进行尝试下: 链接:http://www.36dsj.com/archives/26723 引言 机器学习领域中所谓的降维就是指采用某种映 ...
随机推荐
- Eclipse配置C++环境
由于实在不想用(界面太丑,超级强迫症),前段时间JAVA一直用eclipse,感觉这个IDE非常友好,看上去很舒服,下载的时候发现有C++版本,于是折腾了一会儿,谷歌上发现好多教程,但是大部分比较老, ...
- React Native新手入门
前言 React Native是最近非常火的一个话题,想要学习如何使用它,首先就要知道它是什么. 好像面对一个新手全面介绍它的文章还不多,我就归纳一下所有的资料和刚入门的小伙伴一起来认识它~ 将从以下 ...
- linux nginx大量TIME_WAIT的解决办法--转
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}' TIME_WAIT 8535 CLOSE_WAIT 5 FIN ...
- python网络编程-socket发送大数据包问题
一:什么是socket大数据包发送问题 socket服务器端或者客户端在向对方发送的数据大于对方接受的缓存时,会出现第二次接受还接到上次命令发送的结果.这就出现象第一次接受结果不全,第二次接果出现第一 ...
- Python匿名函数详解
python 使用 lambda 来创建匿名函数. lambda这个名称来自于LISP,而LISP则是从lambda calculus(一种符号逻辑形式)取这个名称的. 在Python中,lambda ...
- Ibatis.Net 各种配置说明学习(二)
1.各个配置文件的配置说明 providers.config:指定数据库提供者,.Net版本等信息. xxxxx.xml:映射规则. SqlMap.config:大部分配置一般都在这里,如数据库连接等 ...
- CF 983B 序列函数
CF 983B 序列函数 一道本校神仙wucstdio出的毒瘤签到题. 题意: 给你一段序列,求出它们的最大异或和. 解法: 其实这道题并不很难,但读题上可能会有困难. 其实样例我是用Python 3 ...
- 洛谷P2458 保安站岗
传送门啦 分析: 树形dp刚刚入门,这是我做的第一个一个点同时受父亲节点和儿子节点控制的题目. 由于这个题中某一个点放不放保安与父亲和儿子都有关系(因为线段的两个端点嘛),所以我们做题时就要考虑全面. ...
- (三)Jsoup 使用选择器语法查找 DOM 元素
第一节: Jsoup 使用选择器语法查找 DOM 元素 Jsoup使用选择器语法查找DOM元素 我们前面通过标签名,Id,Class样式等来搜索DOM,这些是不能满足实际开发需求的, 很多时候我们需要 ...
- hadoop 初探之第二篇(杂谈)
NameNode:名称节点,主要功能在于实现保存文件元数据,这些元数据直接保存在内存中,为了保证元数据的持久性,而也会周期性的同步到磁盘上去.磁盘上的数据通常被称为元数据的映像数据 image fil ...