centos7搭建kafka集群-第一篇
Kafka初识
1、Kafka使用背景
- 我们想分析下用户行为(pageviews),以便我们设计出更好的广告位
- 我想对用户的搜索关键词进行统计,分析出当前的流行趋势
- 有些数据,存储数据库浪费,直接存储硬盘效率又低
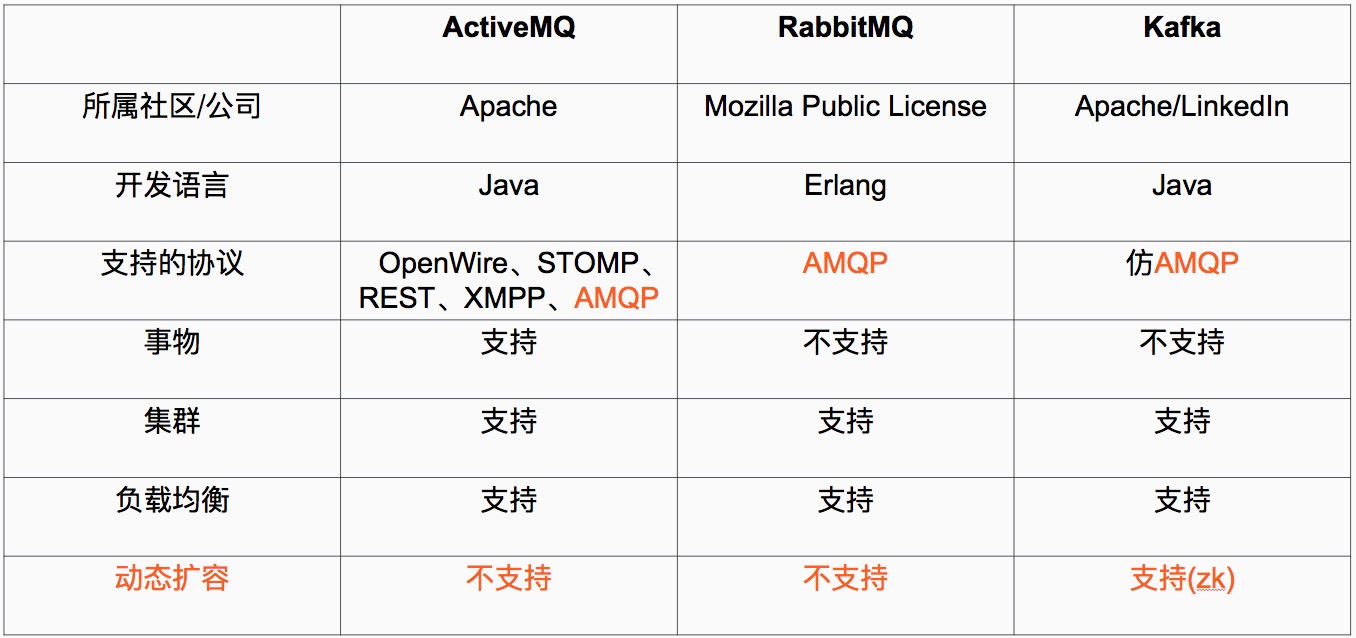
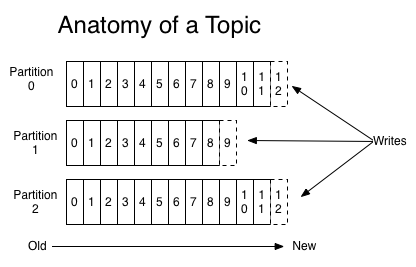
Kafka相关概念
1、 AMQP协议
centos7搭建kafka集群-第一篇的更多相关文章
- centos7搭建kafka集群-第二篇
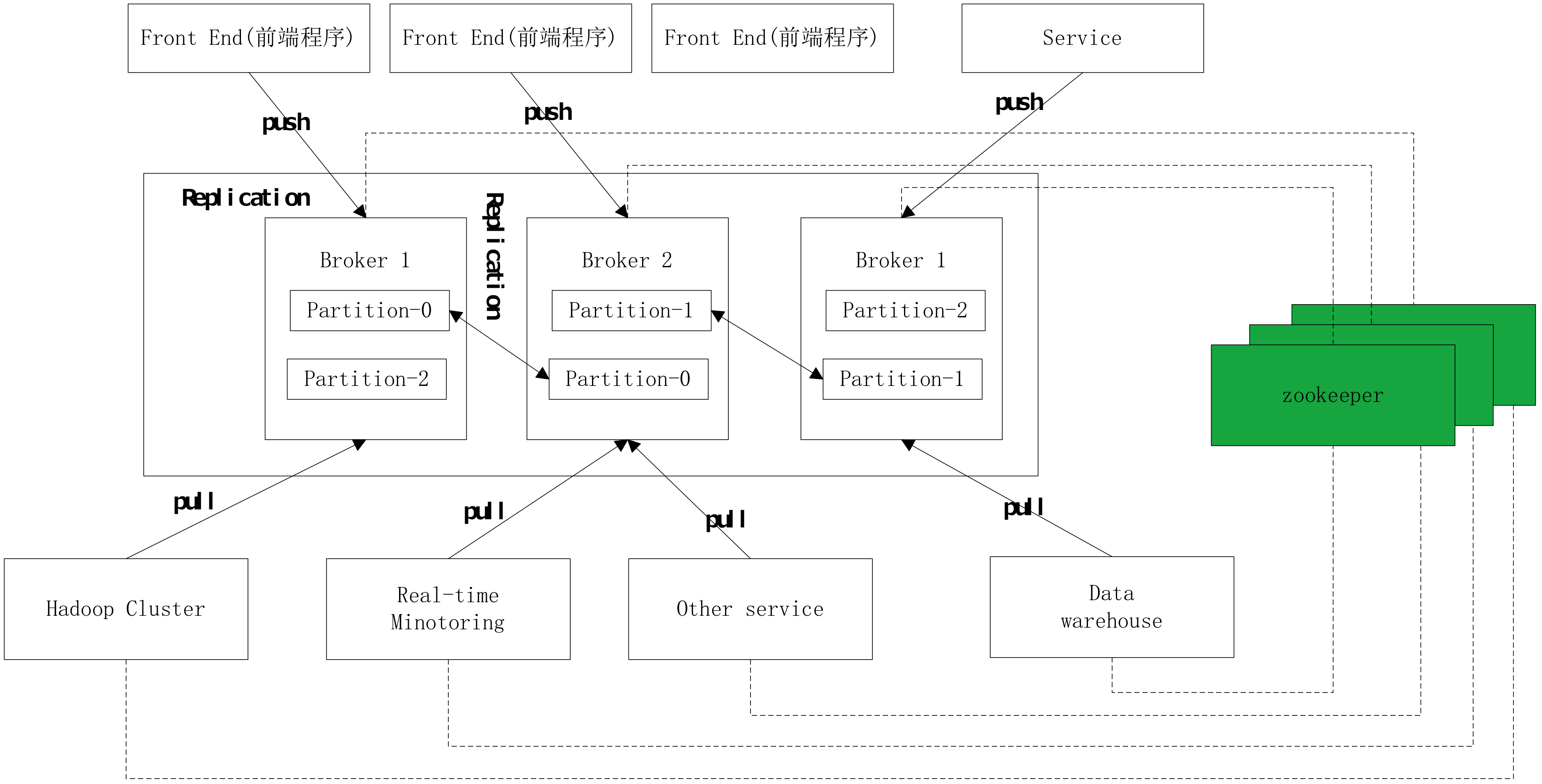
好了,本篇开始部署kafka集群 Zookeeper集群搭建 注:Kafka集群是把状态保存在Zookeeper中的,首先要搭建Zookeeper集群(也可以用kafka自带的ZK,但不推荐) 1.软 ...
- centos7搭建kafka集群
一.安装jdk 1.下载jdk压缩包并移动到/usr/local目录 mv jdk-8u162-linux-x64.tar.gz /usr/local 2.解压 tar -zxvf jdk-8u162 ...
- 利用新版本自带的Zookeeper搭建kafka集群
安装简要说明新版本的kafka自带有zookeeper,其实自带的zookeeper完全够用,本篇文章以记录使用自带zookeeper搭建kafka集群.1.关于kafka下载kafka下载页面:ht ...
- Kafka集群优化篇-调整broker的堆内存(heap)案例实操
Kafka集群优化篇-调整broker的堆内存(heap)案例实操 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.查看kafka集群的broker的堆内存使用情况 1>. ...
- Kafka学习之(六)搭建kafka集群
想要搭建kafka集群,必须具备zookeeper集群,关于zookeeper集群的搭建,在Kafka学习之(五)搭建kafka集群之Zookeeper集群搭建博客有说明.需要具备两台以上装有zook ...
- 大数据平台搭建-kafka集群的搭建
本系列文章主要阐述大数据计算平台相关框架的搭建,包括如下内容: 基础环境安装 zookeeper集群的搭建 kafka集群的搭建 hadoop/hbase集群的搭建 spark集群的搭建 flink集 ...
- 什么是kafka以及如何搭建kafka集群?
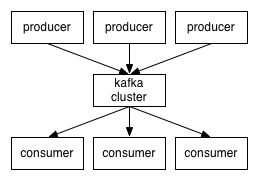
一.Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据. Kafka场景比喻 接下来我大概比喻下Kafka的使用场景 消息中间件:生产者和消费者 妈妈:生产 ...
- Centos7.4 kafka集群安装与kafka-eagle1.3.9的安装
Centos7.4 kafka集群安装与kafka-eagle1.3.9的安装 集群规划: hostname Zookeeper Kafka kafka-eagle kafka01 √ √ √ kaf ...
- docker-compose 搭建kafka集群
docker-compose搭建kafka集群 下载镜像 1.wurstmeister/zookeeper 2.wurstmeister/kafka 3.sheepkiller/kafka-manag ...
随机推荐
- 检查Makefile中的tab
转:http://stackoverflow.com/questions/16931770/makefile4-missing-separator-stop makefile has a very s ...
- 2018.10.01 bzoj3237: [Ahoi2013]连通图(cdq分治+并查集)
传送门 cdq分治好题. 对于一条边,如果加上它刚好连通的话,那么删掉它会有两个大集合A,B.于是我们先将B中禁用的边连上,把A中禁用的边禁用,再递归处理A:然后把A中禁用的边连上,把B中禁用的边禁用 ...
- 2018.09.30 bzoj2223: [Coci 2009]PATULJCI(主席树)
传送门 主席树经典题目. 直接利用主席树差分的思想判断区间中数的个数是否合法然后决定左走右走就行了. 实际上跟bzoj3524是同一道题. 代码: #include<bits/stdc++.h& ...
- AngularJS标准Web业务流程开发框架-4.AngularJS四大模块之一:Controller
一.Controller的创建 angular.controller("name",funtion($scope){ }) 1.name:控制器的名称(建议参考Java包的命名规范 ...
- movielens 时间戳是秒级别的
sigmoid(inX)函数 def sigmoid(inX): return 1.0/(1+exp(-inX)) Timestamps represent seconds since midnigh ...
- 基于SceneControl单击查询功能的实现
private void HandleIdentify_MouseDown(object sender, ISceneControlEvents_OnMouseDownEvent e) { this. ...
- 控件无法安装的问题-Unable to execute file
官方网站:http://www.ncmem.com/ 产品首页:http://www.ncmem.com/webplug/wordpaster/ 产品介绍:http://www.cnblogs.com ...
- WCF客户端第一请求server特别慢,解决办法
最近开发WCF应用的客户端,第一连接WCF后,请求数据返回的速度特别慢,不知道原因如何.最后改了下系统生成的APP.Config文件就好了,原来没有useDefaultWebProxy的选项,没有的时 ...
- Useful Field of View (UFOV)
IE8不支持canvas,使用excanvas.js,js代码需要放在window.onload=function(){...}内,$(docuemnt).ready(function(){...}) ...
- DBCC--EXTENTINFO/IND/PAGE--显示数据页信息
DBCC EXTENTINFO得到对象分配的区DBCC EXTENTINFO(<dbname|dbid>,<tabelname|tableid>[,{indexname|ind ...