MapReduce的洗牌(Shuffle)
Shuffle过程:数据从map端传输到reduce端的过程~
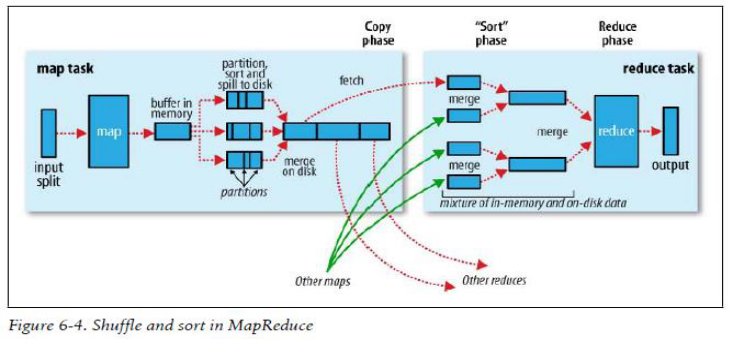
Map端
- 每个map有一个环形内存缓冲区,用于存储任务的输出。默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io.sort.spill.percent),一个后台线程把内容写到(spill)磁盘的指定目录(mapred.local.dir)下的新建的一个溢出写文件。
- 写磁盘前,要partition,sort。如果有combiner,combine排序后数据。
- 等最后记录写完,合并全部溢出写文件为一个分区且排序的文件。
hadoop1中的是resourcemanager,在hadoop2中applicationmaster会通过reduce task从map task拷贝文件
Reduce端
- Reducer通过Http方式得到输出文件的分区。 ( 上图为3个reduce任务,每一个分区产生一个reduce任务,分区后的数据通过shuffle,由reduce主动fetch数据,通过网络copy到reduce端)
- TaskTracker为分区文件运行Reduce任务。复制阶段把Map输出复制到Reducer的内存或磁盘。一个Map任务完成,Reduce就开始复制输出。
- 排序阶段合并map输出。然后走Reduce阶段。
优化点:
- 内存缓冲器越小的时,往磁盘写的几率会增加。磁盘上会产生更多小文件的合并。数据的排序发生在内存中,如果缓冲区越大,也就是往磁盘写入的更少。
- Spill到指定目录,如果把指定目录建立在固定硬盘上速度会加快。
- 数据传输的时候网络也是可优化的,可增加网络带宽。
源码导读:

注释:
/**
* Reduces a set of intermediate values which share a key to a smaller set of Reduce减少汇总了一些中间值的集合,共享一个key给一些较小值得集合
* values.
*
<p><code>Reducer</code> has 3 primary phases:</p>
* <ol>
* <li>
*
* <h4 id="Shuffle">Shuffle</h4>
*
* <p>The <code>Reducer</code> copies the sorted output from each //复制每个的排序输出,核心是拷贝
* {@link Mapper} using HTTP across the network.</p> //在整个网络上使用HTTP,网络传输的过程就是shuffle的过程
* </li>
*
* <li>
* <h4 id="Sort">Sort</h4>
*
* <p>The framework merge sorts <code>Reducer</code> inputs by
* <code>key</code>s
* (since different <code>Mapper</code>s may have output the same key).</p>
*
* <p>The shuffle and sort phases occur simultaneously i.e. while outputs are
* being fetched they are merged.</p>
*
* <h5 id="SecondarySort">SecondarySort</h5>
*
* <p>To achieve a secondary sort on the values returned by the value
* iterator, the application should extend the key with the secondary
* key and define a grouping comparator. The keys will be sorted using the
* entire key, but will be grouped using the grouping comparator to decide
* which keys and values are sent in the same call to reduce.The grouping
* comparator is specified via
* {@link Job#setGroupingComparatorClass(Class)}. The sort order is
* controlled by
* {@link Job#setSortComparatorClass(Class)}.</p>
* For example, say that you want to find duplicate web pages and tag them
* all with the url of the "best" known example. You would set up the job
* like:
* <ul>
* <li>Map Input Key: url</li>
* <li>Map Input Value: document</li>
* <li>Map Output Key: document checksum, url pagerank</li>
* <li>Map Output Value: url</li>
* <li>Partitioner: by checksum</li>
* <li>OutputKeyComparator: by checksum and then decreasing pagerank</li>
* <li>OutputValueGroupingComparator: by checksum</li>
* </ul>
* </li>
*
* <li>
* <h4 id="Reduce">Reduce</h4>
*
* <p>In this phase the
* {@link #reduce(Object, Iterable, Context)}
* method is called for each <code><key, (collection of values)></code> in
* the sorted inputs.</p>
* <p>The output of the reduce task is typically written to a
* {@link RecordWriter} via
* {@link Context#write(Object, Object)}.</p>
* </li>
* </ol>
*
* <p>The output of the <code>Reducer</code> is <b>not re-sorted</b>.</p>
*
* <p>Example:</p>
* <p><blockquote><pre>
* public class IntSumReducer<Key> extends Reducer<Key,IntWritable,
* Key,IntWritable> {
* private IntWritable result = new IntWritable();
*
* public void reduce(Key key, Iterable<IntWritable> values,
* Context context) throws IOException, InterruptedException {
* int sum = 0;
* for (IntWritable val : values) {
* sum += val.get();
* }
* result.set(sum);
* context.write(key, result);
* }
* }
* </pre></blockquote></p>
*
* @see Mapper
* @see Partitioner
*/
End!
MapReduce的洗牌(Shuffle)的更多相关文章
- 洗牌Shuffle'm Up POJ-3087 模拟
题目链接:Shuffle'm Up 题目大意 模拟纸牌的洗牌过程,已知两个牌数相等的牌堆.求解经过多少次洗牌的过程,使牌的顺序与目标顺序相同. 思路 直接模拟,主要是字符串的操作.问题是,如何判断出不 ...
- erlang 洗牌 shuffle
很简单的一个场景:一副扑克(54张)的乱序洗牌 shuffle_list(List) -> [X || {_, X} <- lists:sort([{random:uniform(), N ...
- Fisher–Yates shuffle 洗牌(shuffle)算法
今天在敲undersore的源码,数组里面有一个shuffle,把数组随机打乱. _.shuffle = function(obj) { var set = isArrayLike(obj) ? ob ...
- 【转】Algorithms -离散概率值(discrete)和重置、洗牌(shuffle)算法及代码
离散概率值(discrete) 和 重置\洗牌(shuffle) 算法 及 代码 本文地址: http://blog.csdn.net/caroline_wendy/article/details/1 ...
- 用C语言实现的扑克牌洗牌程序
一副牌:54张 从0开始排序: 0-12表示黑桃 A 1,2,3,... 10,J,Q,K 13-25表示红桃 A 1,2,3,... 10,J,Q,K 26-38表示草花 A 1,2,3,... ...
- [大牛翻译系列]Hadoop(13)MapReduce 性能调优:优化洗牌(shuffle)和排序阶段
6.4.3 优化洗牌(shuffle)和排序阶段 洗牌和排序阶段都很耗费资源.洗牌需要在map和reduce任务之间传输数据,会导致过大的网络消耗.排序和合并操作的消耗也是很显著的.这一节将介绍一系列 ...
- [LeetCode] Shuffle an Array 数组洗牌
Shuffle a set of numbers without duplicates. Example: // Init an array with set 1, 2, and 3. int[] n ...
- [转]完美洗牌(Perfect Shuffle)问题
[转]原博文地址:https://github.com/julycoding/The-Art-Of-Programming-By-July/blob/master/ebook/zh/02.09.md ...
- [CareerCup] 18.2 Shuffle Cards 洗牌
18.2 Write a method to shuffle a deck of cards. It must be a perfect shuffle—in other words, each of ...
随机推荐
- 对象克隆技术Object.clone()
Java中对象的创建 clone顾名思义就是复制, 在Java语言中, clone方法被对象调用,所以会复制对象. 所谓的复制对象,首先要分配一个和源对象同样大小的空间,在这个空间中创建一个新的对象. ...
- mysql的in查询分析
群里山楂大仙和电台大神探讨到mysql的in查询的问题,问题如下: student表有class_id的索引,但是只查询一个的时候用索引,查两个就不用索引了 这是很奇怪的现象,我试了一下也是这样,真是 ...
- PHP代码审计笔记--文件包含漏洞
有限制的本地文件包含: <?php include($_GET['file'].".php"); ?> %00截断: ?file=C://Windows//win.in ...
- java-RAC Oracle 连接字符串
昨天在访问oracle数据库取数据时遇到一个问题: 上网搜索一下发现是我访问的数据库做了RAC,原有的数据库连接字符串不适用,原来的连接字符串如下所示: 使用下面的字符串解决了该问题: String ...
- JavaWeb学习总结(十七)EL表达式
语法格式: ${expression} 1. 表达式支持算术运算符合逻辑运算符 <%@ page language="java" contentType="text ...
- 在 Linux 使用 GCC 编译C语言共享库
对任何程序员来说库都是必不可少的.所谓的库是指已经编译好的供你使用的代码.它们常常提供一些通用功能,例如链表和二叉树可以用来保存任何数据,或者是一个特定的功能例如一个数据库服务器的接口,就像MySQL ...
- react中的hoc和修饰器@connect结合使用
在学习react-redux的时候,看到了修饰器这个新的属性,这个是es7的提案属性,很方便.于是我用@connect代替了connect(使用的时候需要配置,这里不赘述),省去了很多不必要的代码,但 ...
- Android学习之PopupWindow
Android的对话框有两种:PopupWindow和AlertDialog. 详细说明如下: AlertDialog是非阻塞式对话框:AlertDialog弹出时,后台还可以做事情: AlertDi ...
- 树莓派3b配置耳机音频输出
耳机输出 amixer cset numid=3 1 然后,播放既可,有杂音. hdmi输出 amixer cset numid=3 2
- 三.jquery.datatables.js表格编辑与删除
1.为了使用如图效果(即将按钮放入行内http://www.datatables.net/examples/ajax/null_data_source.html) 采用了另一个数据格式 2.后台php ...