Neo4j 第三篇:Cypher查询入门
本文转载自:https://www.cnblogs.com/ljhdo/p/5516793.html
Neo4j使用Cypher查询图形数据,Cypher是描述性的图形查询语言,语法简单,功能强大,由于Neo4j在图形数据库家族中处于绝对领先的地位,拥有众多的用户基数,使得Cypher成为图形查询语言的事实上的标准。本文作为入门级的教程,我不会试图分析Cypher语言的全部内容,本文的目标是循序渐进地使用Cypher语言执行简单的CRUD操作,为了便于演示,本文在Neo4j Browser中执行Cypher示例代码。以下图形包含三个节点和两个关系,本文会一步一步讲解如何利用Cypher语言创建以下图形。
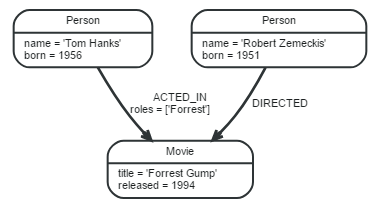
我的Neo4j系列的文章收录在:Neo4j
一,easy,热热身
和SQL很相似,Cypher语言的关键字不区分大小写,但是属性值,标签,关系类型和变量是区分大小写的。
1,变量(Variable)
变量用于对搜索模式的部分进行命名,并在同一个查询中引用,在小括号()中命名变量,变量名是区分大小写的,示例代码创建了两个变量:n和b,通过return子句返回变量b;
MATCH (n)-->(b)
RETURN b
在Cypher查询中,变量用于引用搜索模式(Pattern),但是变量不是必需的,如果不需要引用,那么可以忽略变量。
2,访问属性
在Cypher查询中,通过逗号来访问属性,格式是:Variable.PropertyKey,通过id函数来访问实体的ID,格式是id(Variable)。
match (n)-->(b)
where id(n)=5 and b.age=18
return b;
二,创建节点
节点模式的构成:(Variable:Lable1:Lable2{Key1:Value1,Key2,Value2}),实际上,每个节点都有一个整数ID,在创建新的节点时,Neo4j自动为节点设置ID值,在整个数据库中,节点的ID值是递增的和唯一的。
下面的Cypher查询创建一个节点,标签是Person,具有两个属性name和born,通过RETURN子句,返回新建的节点:
create (n:Person { name: 'Tom Hanks', born: 1956 }) return n;

继续创建其他节点:
create (n:Person { name: 'Robert Zemeckis', born: 1951 }) return n;
create (n:Movie { title: 'Forrest Gump', released: 1951 }) return n;
三,查询节点
通过match子句查询数据库,match子句用于指定搜索的模式(Pattern),where子句为match模式增加谓词(Predicate),用于对Pattern进行约束;
1,查询整个图形数据库
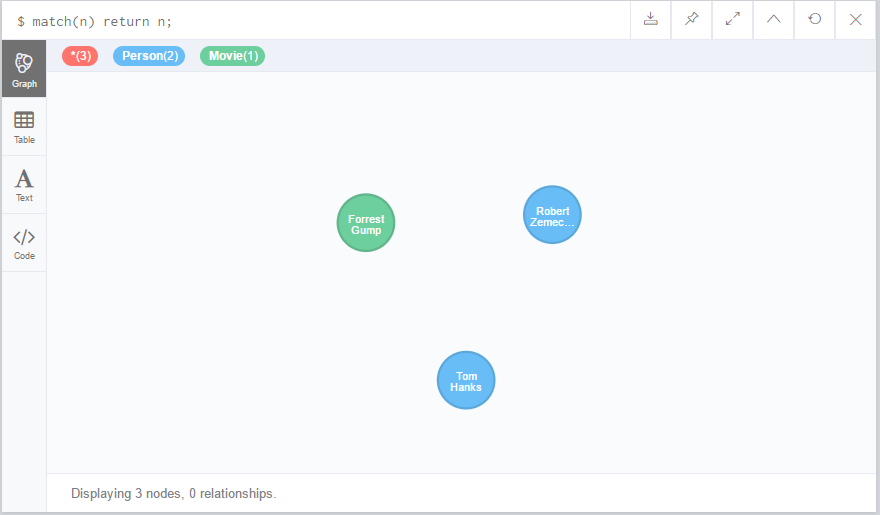
match(n) return n;
在图形数据库中,有三个节点,Person标签有连个节点,Movie有1个节点
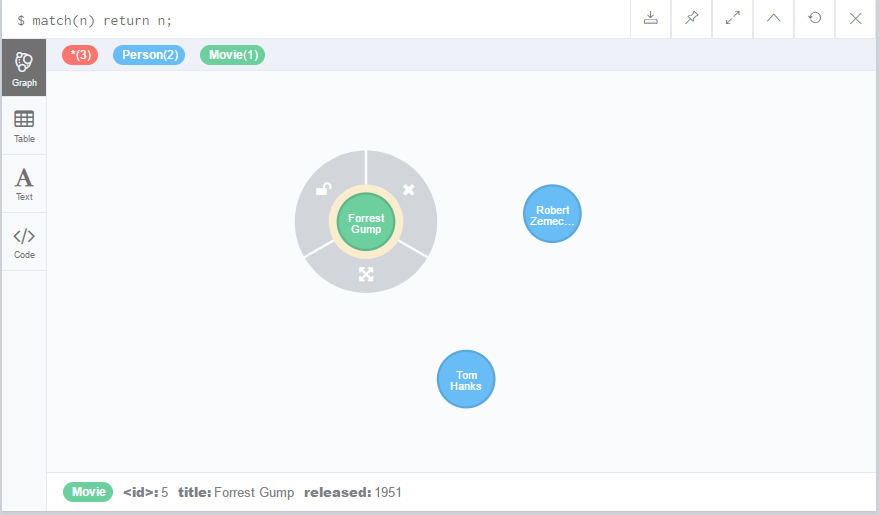
点击节点,查看节点的属性,如图,Neo4j自动为节点设置ID值,本例中,Forrest Gump节点的ID值是5,
2,查询born属性小于1955的节点
match(n)
where n.born<1955
return n;

3,查询具有指定Lable的节点
match(n:Movie)
return n;

4,查询具有指定属性的节点
match(n{name:'Tom Hanks'})
return n;

四,创建关系
关系的构成:StartNode - [Variable:RelationshipType{Key1:Value1,Key2:Value2}] -> EndNode,在创建关系时,必须指定关系类型。
1,创建没有任何属性的关系
MATCH (a:Person),(b:Movie)
WHERE a.name = 'Robert Zemeckis' AND b.title = 'Forrest Gump'
CREATE (a)-[r:DIRECTED]->(b)
RETURN r;

2,创建关系,并设置关系的属性
MATCH (a:Person),(b:Movie)
WHERE a.name = 'Tom Hanks' AND b.title = 'Forrest Gump'
CREATE (a)-[r:ACTED_IN { roles:['Forrest'] }]->(b)
RETURN r;

五,查询关系
在Cypher中,关系分为三种:符号“--”,表示有关系,忽略关系的类型和方向;符号“-->”和“<--”,表示有方向的关系;
1,查询整个数据图形
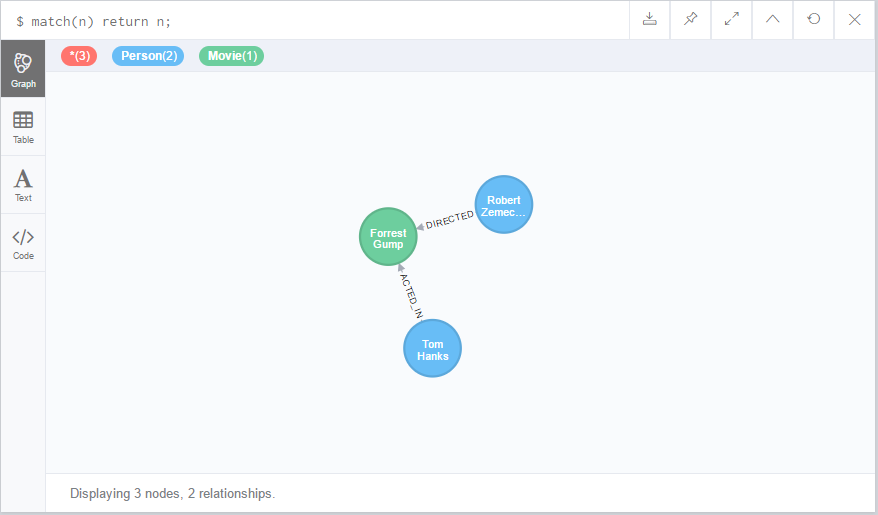
2,查询跟指定节点有关系的节点
示例脚本返回跟Movie标签有关系的所有节点
match(n)--(m:Movie)
return n;

2,查询有向关系的节点
MATCH (:Person { name: 'Tom Hanks' })-->(movie)
RETURN movie;

3,为关系命名,通过[r]为关系定义一个变量名,通过函数type获取关系的类型
MATCH (:Person { name: 'Tom Hanks' })-[r]->(movie)
RETURN r,type(r);

4,查询特定的关系类型,通过[Variable:RelationshipType{Key:Value}]指定关系的类型和属性
MATCH (:Person { name: 'Tom Hanks' })-[r:ACTED_IN{roles:'Forrest'}]->(movie)
RETURN r,type(r);
六,更新图形
set子句,用于对更新节点的标签和实体的属性;remove子句用于移除实体的属性和节点的标签;
1,创建一个完整的Path
由于Path是由节点和关系构成的,当路径中的关系或节点不存在时,Neo4j会自动创建;
CREATE p =(vic:Worker:Person{ name:'vic',title:"Developer" })-[:WORKS_AT]->(neo)<-[:WORKS_AT]-(michael:Worker:Person { name: 'Michael',title:"Manager" })
RETURN p
变量neo代表的节点没有任何属性,但是,其有一个ID值,通过ID值为该节点设置属性和标签

2,为节点增加属性
通过节点的ID获取节点,Neo4j推荐通过where子句和ID函数来实现。
match (n)
where id(n)=7
set n.name = 'neo'
return n;
3,为节点增加标签
match (n)
where id(n)=7
set n:Company
return n;

4,为关系增加属性
match (n)<-[r]-(m)
where id(n)=7 and id(m)=8
set r.team='Azure'
return n;

七,Merge子句
Merge子句的作用有两个:当模式(Pattern)存在时,匹配该模式;当模式不存在时,创建新的模式,功能是match子句和create的组合。在merge子句之后,可以显式指定on creae和on match子句,用于修改绑定的节点或关系的属性。
通过merge子句,你可以指定图形中必须存在一个节点,该节点必须具有特定的标签,属性等,如果不存在,那么merge子句将创建相应的节点。
1,通过merge子句匹配搜索模式
匹配模式是:一个节点有Person标签,并且具有name属性;如果数据库不存在该模式,那么创建新的节点;如果存在该模式,那么绑定该节点;
MERGE (michael:Person { name: 'Michael Douglas' })
RETURN michael;
2,在merge子句中指定on create子句
如果需要创建节点,那么执行on create子句,修改节点的属性;
ERGE (keanu:Person { name: 'Keanu Reeves' })
ON CREATE SET keanu.created = timestamp()
RETURN keanu.name, keanu.created
3,在merge子句中指定on match子句
如果节点已经存在于数据库中,那么执行on match子句,修改节点的属性;
MERGE (person:Person)
ON MATCH SET person.found = TRUE , person.lastAccessed = timestamp()
RETURN person.name, person.found, person.lastAccessed
4,在merge子句中同时指定on create 和 on match子句
MERGE (keanu:Person { name: 'Keanu Reeves' })
ON CREATE SET keanu.created = timestamp()
ON MATCH SET keanu.lastSeen = timestamp()
RETURN keanu.name, keanu.created, keanu.lastSeen
5,merge子句用于match或create一个关系
MATCH (charlie:Person { name: 'Charlie Sheen' }),(wallStreet:Movie { title: 'Wall Street' })
MERGE (charlie)-[r:ACTED_IN]->(wallStreet)
RETURN charlie.name, type(r), wallStreet.title
6,merge子句用于match或create多个关系
MATCH (oliver:Person { name: 'Oliver Stone' }),(reiner:Person { name: 'Rob Reiner' })
MERGE (oliver)-[:DIRECTED]->(movie:Movie)<-[:ACTED_IN]-(reiner)
RETURN movie
7,merge子句用于子查询
MATCH (person:Person)
MERGE (city:City { name: person.bornIn })
RETURN person.name, person.bornIn, city; MATCH (person:Person)
MERGE (person)-[r:HAS_CHAUFFEUR]->(chauffeur:Chauffeur { name: person.chauffeurName })
RETURN person.name, person.chauffeurName, chauffeur; MATCH (person:Person)
MERGE (city:City { name: person.bornIn })
MERGE (person)-[r:BORN_IN]->(city)
RETURN person.name, person.bornIn, city;
八,跟实体相关的函数
1,通过id函数,返回节点或关系的ID
MATCH (:Person { name: 'Oliver Stone' })-[r]->(movie)
RETURN id(r);
2,通过type函数,查询关系的类型
MATCH (:Person { name: 'Oliver Stone' })-[r]->(movie)
RETURN type(r);
3,通过lables函数,查询节点的标签
MATCH (:Person { name: 'Oliver Stone' })-[r]->(movie)
RETURN lables(movie);
4,通过keys函数,查看节点或关系的属性键
MATCH (a)
WHERE a.name = 'Alice'
RETURN keys(a)
5,通过properties()函数,查看节点或关系的属性
CREATE (p:Person { name: 'Stefan', city: 'Berlin' })
RETURN properties(p)
Neo4j 第三篇:Cypher查询入门的更多相关文章
- Elasticsearch第三篇:查询详解
从第一篇开始,我用的ES版本就是7.8.0的,与低版本略有不同,不同点可以参考官方介绍,最大的不同就是抛弃 type 这一概念,为了方便测试,首先建立一个学生成绩的索引库(在建立的同时,规定字段类型, ...
- 【python自动化第三篇:python入门进阶】
鸡汤: 多学习,多看书. 推荐书籍:<追风筝的人>,<林达看美国>,<白鹿原> 本节知识点 集合及其操作 文件操作 函数与函数式编程 递归 一.集合及其操作 集合( ...
- Python之路,第三篇:Python入门与基础3
1, 布尔运算符 运算符; not and or not 运算符: 作用:逻辑取反 语法: not 表达式 例: not True # False not Fa ...
- Neo4j 第四篇:使用C#更新和查询Neo4j
本文使用的IDE是Visual Studio 2015 ,驱动程序是Neo4j官方的最新版本:Neo4j Driver 1.3.0 ,创建的类库工程(Project)要求安装 .NET Framewo ...
- ElasticSearch入门 第三篇:索引
这是ElasticSearch 2.4 版本系列的第三篇: ElasticSearch入门 第一篇:Windows下安装ElasticSearch ElasticSearch入门 第二篇:集群配置 E ...
- Neo4j 第四篇:使用.NET驱动访问Neo4j
本文使用的IDE是Visual Studio 2015 ,驱动程序是Neo4j官方的最新版本:Neo4j.Driver,创建的类库工程(Project)要求安装 .NET Framework 4.5. ...
- 【第三篇】ASP.NET MVC快速入门之安全策略(MVC5+EF6)
目录 [第一篇]ASP.NET MVC快速入门之数据库操作(MVC5+EF6) [第二篇]ASP.NET MVC快速入门之数据注解(MVC5+EF6) [第三篇]ASP.NET MVC快速入门之安全策 ...
- Neo4j使用Cypher查询图形数据
Neo4j使用Cypher查询图形数据,Cypher是描述性的图形查询语言,语法简单,功能强大,由于Neo4j在图形数据库家族中处于绝对领先的地位,拥有众多的用户基数,使得Cypher成为图形查询语言 ...
- Membership三步曲之入门篇 - Membership基础示例
Membership 三步曲之入门篇 - Membership基础示例 Membership三步曲之入门篇 - Membership基础示例 Membership三步曲之进阶篇 - 深入剖析Pro ...
随机推荐
- 《网页文档/文字复制方法大全》 - imsoft.cnblogs
<网页文档/文字复制方法大全> 一: 1.首先,找到自己要的文档. 2.文章题目复制,在搜索引擎的框框里输入:site:wenku.baidu.com "题目"/sit ...
- this和super用法详解
这几天看到类在继承时会用到this和super,这里就做了一点总结,与各位共同交流,有错误请各位指正~ this this是自身的一个对象,代表对象本身,可以理解为:指向对象本身的一个指针. this ...
- 测试那些事儿—浅谈TCP/IP协议
TCP/IP协议是一系列网络协议的总和,是构成网络通信的核心骨架. TCP/IP的工作原理通俗的讲就是一个主机的数据要经过哪些过程才能发送到对方的主机上. TCP/IP协议采用四层结构,分别为应用层, ...
- 动态规划-----hdu 1024 (区间连续和)
给定一个长度为n的区间:求m段连续子区间的和 最大值(其中m段子区间互不相交) 思路: dp[i][j]: 前j个元素i个连续区间最大值 (重要 a[j]必须在最后一个区间内) 转移方程:dp[i][ ...
- 单调栈的运用-bzoj1012(代码转载-http://hzwer.com/1130.html)
Description 现在请求你维护一个数列,要求提供以下两种操作: . 查询操作.语法:Q L 功能:查询当前数列中末尾L个数中的最大的数,并输出这个数的值.限制:L不超过当前数列的长度. . 插 ...
- SQL-表-003
注:红色代表关键字,绿色代表解释说明,蓝色代表重点: 什么是数据表? 数据表是数据库中最重要的组成部分,可以将数据表分解成字段(列)和记录(行): 数据表的增加:约束同时创建 create table ...
- linux-----初学命令和理解
the following Codes has been confirmed by me 1.头部标识[pecool@demo ~]: 其中pecool代表登入用户:demo代表系统名称:~代表当前处 ...
- LeetCode – Group Shifted Strings
Given a string, we can "shift" each of its letter to its successive letter, for example: & ...
- JS 数组常用的方法
数组常用的方法: x.toString()方法:任何对象都有toString方法. 将任何对象转为字符串. 一般不主动调用,系统在需要时自动调用 x.valueOf()方法:同toStr ...
- linux之nagios安装教程
我的系统环境是centos7,其它系统应该也差不多,只是有几条命令可能需要换种写法 下面是我用到的命令 363 yum install -y gcc gcc-c++ httpd php php-gd ...