cbow与skip-gram
场景:上次回答word2vec相关的问题,回答的是先验概率和后验概率,没有回答到关键点。
词袋模型(Bag of Words, BOW)与词向量(Word Embedding)模型
- 词袋模型就是将句子分词,然后对每个词进行编码,常见的有one-hot、TF-IDF、Huffman编码,假设词与词之间没有先后关系。
- 词向量模型是用词向量在空间坐标中定位,然后计算cos距离可以判断词于词之间的相似性。
先验概率和后验概率
先验概率和后验证概率是基于词向量模型。首先一段话由五个词组成:
A B C D E
对C来说:先验概率指ABDE出现后C出现的概率,即P(C|A,B,D,E)
可以将C用ABDE出现的概率来表示 Vector(C) = [P(C|A), P(C|B), P(C|D), P(C|E) ]
后验概率指C出现后ABDE出现的概率:即P(A|C),P(B|C),P(D|C),P(E|C)
n-gram
先验概率和后验概率已经知道了,但是一个句子很长,对每个词进行概率计算会很麻烦,于是有了n-gram模型。
该模型基于这样一种假设,第N个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。
一般情况下我们只计算一个单词前后各两个词的概率,即n取2, 计算n-2,.n-1,n+1,n+2的概率。
如果n=3,计算效果会更好;n=4,计算量会变得很大。
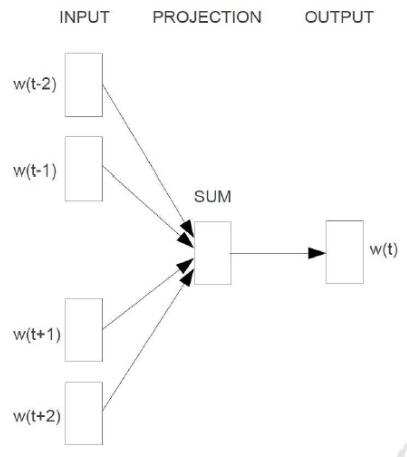
cbow
cbow输入是某一个特征词的上下文相关的词对应的词向量,而输出就是这特定的一个词的词向量,即先验概率。
训练的过程如下图所示,主要有输入层(input),映射层(projection)和输出层(output)三个阶段。
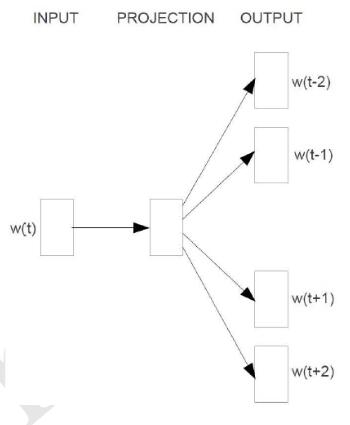
skip-gram
Skip-Gram模型和CBOW的思路是反着来的,即输入是特定的一个词的词向量,而输出是特定词对应的上下文词向量,即后验概率。训练流程如下:
word2vec中的Negative Sampling概述
传统网络训练词向量的网络:
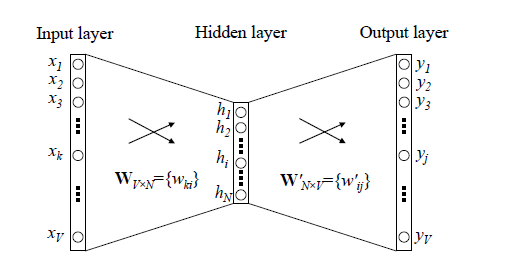
word2vec训练方法和传统的神经网络有所区别,主要解决的是softmax计算量太大的问题,采用Hierarchical Softmax和Negative Sampling模型。
word2vec中cbow,skip-gram都是基于huffman树然后进行训练,左子树为1右子树为0,同时约定左子树权重不小于右子树。
构建的Huffman树如下:
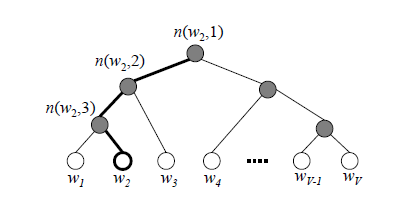
其中,根节点的词向量对应我们的投影后的词向量,而所有叶子节点就类似于之前神经网络softmax输出层的神经元,叶子节点的个数就是词汇表的大小。在霍夫曼树中,隐藏层到输出层的softmax映射不是一下子完成的,而是沿着霍夫曼树一步步完成的,因此这种softmax取名为"Hierarchical Softmax"。
因为时间有限,暂时总结这些,下一次详细看一下word2vec中的实现。
参考:
word2vec原理(一) CBOW与Skip-Gram模型基础
word2vec原理(二) 基于Hierarchical Softmax的模型
自己动手写word2vec (四):CBOW和skip-gram模型
cbow与skip-gram的更多相关文章
- DeepLearning.ai学习笔记(五)序列模型 -- week2 自然语言处理与词嵌入
一.词汇表征 首先回顾一下之前介绍的单词表示方法,即one hot表示法. 如下图示,"Man"这个单词可以用 \(O_{5391}\) 表示,其中O表示One_hot.其他单词同 ...
- NLP学习(4)----word2vec模型
一. 原理 哈弗曼树推导: https://www.cnblogs.com/peghoty/p/3857839.html 负采样推导: http://www.hankcs.com/nlp/word2v ...
- 关于 word2vec 如何工作的问题
2019-09-07 22:36:21 问题描述:word2vec是如何工作的? 问题求解: 谷歌在2013年提出的word2vec是目前最常用的词嵌入模型之一.word2vec实际是一种浅层的神经网 ...
- Paddle Graph Learning (PGL)图学习之图游走类模型[系列四]
Paddle Graph Learning (PGL)图学习之图游走类模型[系列四] 更多详情参考:Paddle Graph Learning 图学习之图游走类模型[系列四] https://aist ...
- word2vec (CBOW、分层softmax、负采样)
本文介绍 wordvec的概念 语言模型训练的两种模型CBOW+skip gram word2vec 优化的两种方法:层次softmax+负采样 gensim word2vec默认用的模型和方法 未经 ...
- tensorflow在文本处理中的使用——CBOW词嵌入模型
代码来源于:tensorflow机器学习实战指南(曾益强 译,2017年9月)——第七章:自然语言处理 代码地址:https://github.com/nfmcclure/tensorflow-coo ...
- Tensorflow 的Word2vec demo解析
简单demo的代码路径在tensorflow\tensorflow\g3doc\tutorials\word2vec\word2vec_basic.py Sikp gram方式的model思路 htt ...
- Word2Vec总结
摘要: 1.算法概述 2.算法要点与推导 3.算法特性及优缺点 4.注意事项 5.实现和具体例子 6.适用场合 内容: 1.算法概述 Word2Vec是一个可以将语言中的字词转换为向量表达(Vecto ...
- Coursera, Deep Learning 5, Sequence Models, week2, Natural Language Processing & Word Embeddings
Word embeding 给word 加feature,用来区分word 之间的不同,或者识别word之间的相似性. 用于学习 Embeding matrix E 的数据集非常大,比如 1B - 1 ...
- lecture2-word2vec-七月在线nlp
离散表示: one-hot bag of words -- 词权重 ~不能表示顺序关系 TF-IDF (Term Frequency - Inverse Document Frequency) [ ...
随机推荐
- Mybatis Generator xml格式配置
Mybatis Generator可以使用Maven方式和Java方法,使用Maven这里是配置文件: <?xml version="1.0" encoding=" ...
- iOS11开发教程(二十三)iOS11应用视图实现按钮的响应(3)
iOS11开发教程(二十三)iOS11应用视图实现按钮的响应(3) 2.使用代码添加按钮实现的响应 使用代码添加的按钮,实现响应需要使用到addTarget(_:action:for:)方法,其语法形 ...
- FastDFS_v4.06安装简记
提前准备所需4个包:FastDFS_v4.06.tar.gzfastdfs-nginx-module_v1.16.tar.gzlibevent-2.0.20-stable.tar.gznginx-1. ...
- BZOJ.2434.[NOI2011]阿狸的打字机(AC自动机 树状数组 DFS序)
题目链接 首先不需要存储每个字符串,可以将所有输入的字符依次存进Trie树,对于每个'P',记录该串结束的位置在哪,以及当前节点对应的是第几个串(当前串即根节点到当前节点):对于'B',只需向上跳一个 ...
- Python3正则表达式(2)
re库常用方法 正则表达式的表示类型: 1.re库采用 raw string 类型(原生字符串类型),不用对转义符再次转义,表示为:r'text' 例如:r'\d{3}-\d{8}' 2.re库采用 ...
- Java并发程序设计(九)设计模式与并发之不变模式
设计模式与并发之不变模式 使用不变模式的目的:除去多线程中的同步操作,提高并行程序的性能. 一个类在的内部状态创建后,在整个生命周期内都不会发生改变,该类就是不变类. /** * @author: T ...
- 潭州课堂25班:Ph201805201 第八课:函数基础和函数参数 (课堂笔记)
1, 函数定义 def fun(): print('测试函数') fun() #调用函数 return 运行函数返回值 def fun(): name = [1,3,4,5] return name[ ...
- tomcat溢出
http://blog.csdn.net/qq_15653597/article/details/42753269?locationNum=10
- linux中apt-get和yum和wget的区别
1.RedHat系列:Redhat.Centos.Fedora等 yum 2.Debian系列:Debian.Ubuntu等 apt-get wget类似迅雷
- 【CSS Demo】纯 CSS 打造 Flow-Steps 导航
low-Steps 导航效果常用于需要表示执行步骤的交互页面,效果如下: 步骤一 步骤二 步骤三 通常使用图片来实现 Flow-Steps 效果,但此方法的灵活性不足,当内容变化较大时就可能需要重 ...