推荐系统-05-Spark电影推荐、评估与部署
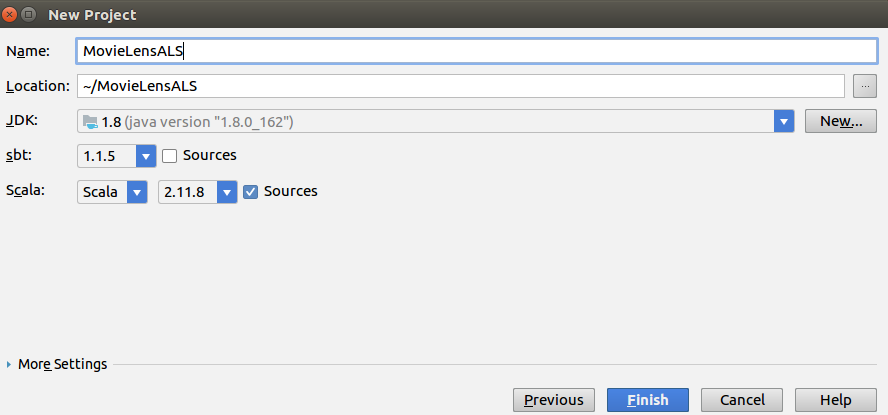
一、新建scala项目
二、构造程序

代码如下
package xyz.pl8
import java.io.File
import org.apache.log4j.{Level, Logger}
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.mllib.evaluation.RegressionMetrics
import org.apache.spark.mllib.recommendation.{MatrixFactorizationModel, Rating, ALS}
import org.apache.spark.rdd.RDD
import scala.util.Random
object MovieLensALS {
//1. Define a rating elicitation function
// Seq[Rating]
def elicitateRating(movies: Seq[(Int, String)])={
val prompt="Please rate the following movie(1-5(best) or 0 if not seen: )"
println(prompt)
val ratings= movies.flatMap{x=>
var rating: Option[Rating] = None // Rating(user: Int, product: Int, rating: Double)
var valid = false
while(!valid){
println(x._2+" :")
try{
val r = Console.readInt()
if (r>5 || r<0){
println(prompt)
} else {
valid = true
if (r>0){
rating = Some(Rating(0, x._1, r))
}
}
} catch{
case e:Exception => println(prompt)
}
}
rating match {
case Some(r) => Iterator(r) // FlatMap将结构解散成元素, 这里是Rating
case None => Iterator.empty
}
}
if (ratings.isEmpty){
error("No ratings provided!")
} else {
ratings
}
}
//2. Define a RMSE computation function
def computeRmse(model: MatrixFactorizationModel, data: RDD[Rating]) = {
val prediction = model.predict(data.map(x=>(x.user, x.product)))
val predDataJoined = prediction.map(x=> ((x.user,x.product),x.rating)).join(data.map(x=> ((x.user,x.product),x.rating))).values
new RegressionMetrics(predDataJoined).rootMeanSquaredError
}
//3. Main
def main(args: Array[String]) {
//3.1 Setup env
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
if (args.length !=1){
print("Usage: movieLensHomeDir")
sys.exit(1)
}
val conf = new SparkConf().setAppName("MovieLensALS")
.set("spark.executor.memory","500m")
val sc = new SparkContext(conf)
//3.2 Load ratings data and know your data
// ratings.dat 的格式 UserID::MovieID::Rating::Timestamp
val movieLensHomeDir=args(0)
// RDD[long, Rating]
val ratings = sc.textFile(new File(movieLensHomeDir, "ratings.dat").toString).map {line =>
val fields = line.split("::")
//timestamp, user, product, rating
// 取模成分成10组
(fields(3).toLong%10, Rating(fields(0).toInt, fields(1).toInt, fields(2).toDouble))
}
// movies.dat格式 MovieID::Title::Genres
// Map[Int,String]
val movies = sc.textFile(new File(movieLensHomeDir, "movies.dat").toString).map {line =>
val fields = line.split("::")
//movieId, movieName
(fields(0).toInt, fields(1))
}.collectAsMap()
val numRatings = ratings.count()
val numUser = ratings.map(x=>x._2.user).distinct().count()
val numMovie = ratings.map(_._2.product).distinct().count()
println("Got "+numRatings+" ratings from "+numUser+" users on "+numMovie+" movies.")
//3.3 Elicitate personal rating
// = RDD[(long,Rating) -> Array[int] -> Map[Int, long] -> Seq[(Int, long)] -> Seq[(Int,long)] -> Seq[Int]
val topMovies = ratings.map(_._2.product).countByValue().toSeq.sortBy(-_._2).take(50).map(_._1)
val random = new Random(0)
// Seq[(Int, String)]
val selectMovies = topMovies.filter(x=>random.nextDouble() < 0.2).map(x=>(x, movies(x)))
val myRatings = elicitateRating(selectMovies)
val myRatingsRDD = sc.parallelize(myRatings, 1)
//3.4 Split data into train(60%), validation(20%) and test(20%)
val numPartitions = 10
// 6组(即60%),并上手工输入评价
val trainSet = ratings.filter(x=>x._1<6).map(_._2).union(myRatingsRDD).repartition(numPartitions).persist()
val validationSet = ratings.filter(x=>x._1>=6 && x._1<8).map(_._2).persist()
val testSet = ratings.filter(x=>x._1>=8).map(_._2).persist()
val numTrain = trainSet.count()
val numValidation = validationSet.count()
val numTest = testSet.count()
println("Training data: "+numTrain+" Validation data: "+numValidation+" Test data: "+numTest)
//3.5 Train model and optimize model with validation set
val numRanks = List(8, 12)
val numIters = List(10, 20)
val numLambdas = List(0.1, 10.0)
var bestRmse = Double.MaxValue
var bestModel: Option[MatrixFactorizationModel] = None
var bestRanks = -1
var bestIters = 0
var bestLambdas = -1.0
// 寻找优化参数的模型
for(rank <- numRanks; iter <- numIters; lambda <- numLambdas){
val model = ALS.train(trainSet, rank, iter, lambda)
val validationRmse = computeRmse(model, validationSet)
println("RMSE(validation) = "+validationRmse+" with ranks="+rank+", iter="+iter+", Lambda="+lambda)
if (validationRmse < bestRmse) {
bestModel = Some(model)
bestRmse = validationRmse
bestIters = iter
bestLambdas = lambda
bestRanks = rank
}
}
//3.6 Evaluate model on test set
// 用测试集来评估模型
// 测试集均方根差
val testRmse = computeRmse(bestModel.get, testSet)
println("The best model was trained with rank="+bestRanks+", Iter="+bestIters+", Lambda="+bestLambdas+
" and compute RMSE on test is "+testRmse)
//3.7 Create a baseline and compare it with best model
// 创建基线 并与模型进行比较
val meanRating = trainSet.union(validationSet).map(_.rating).mean() // 训练集与验证集和的均数
// 最佳根均方错误线(基线)
val bestlineRmse = new RegressionMetrics(testSet.map(x=>(x.rating, meanRating))).rootMeanSquaredError // 测试集与均数的均方根差
// testRmse(这个数应该更优,值更小)
val improvement = (bestlineRmse - testRmse)/bestlineRmse*100
println("The best model improves the baseline by "+"%1.2f".format(improvement)+"%.")
//3.8 Make a personal recommendation
// 进行个人推荐, 排除自己已经评分内容
val moviesId = myRatings.map(_.product)
val candidates = sc.parallelize(movies.keys.filter(!moviesId.contains(_)).toSeq)
val recommendations = bestModel.get
.predict(candidates.map(x=>(0, x)))
.sortBy(-_.rating)
.take(50)
var i = 0
println("Movies recommended for you:")
recommendations.foreach{ line=>
println("%2d".format(i)+" :"+movies(line.product))
i += 1
}
sc.stop()
}
}
导入引用库

三、打包部署
程序运行时,需要指定输入数据路径,数据包含了ratings.dat和movies.dat,数据都包含在了一个数据包。点击下载, 然后解压。
配置运行参数
点击edit configuration,在左侧点击该项目。在右侧在右侧VM options中输入“-Dspark.master=local”,指示本程序本地单线程运行
在Program argguemnts指定,上面解压的路径。
然后,在IDEA上选择MovieLensALS右键选择运行,即可运行了。
按照引导,输入自己的评价后,最后输出形式如下:The best model was trained with rank=12, Iter=20, Lambda=0.1 and compute RMSE on test is 0.868464888081759
The best model improves the baseline by 22.01%.
Movies recommended for you:
0 :Julien Donkey-Boy (1999)
1 :Love Serenade (1996)
2 :Catwalk (1995)
四、HADOOP集群部署
导出jar包设置
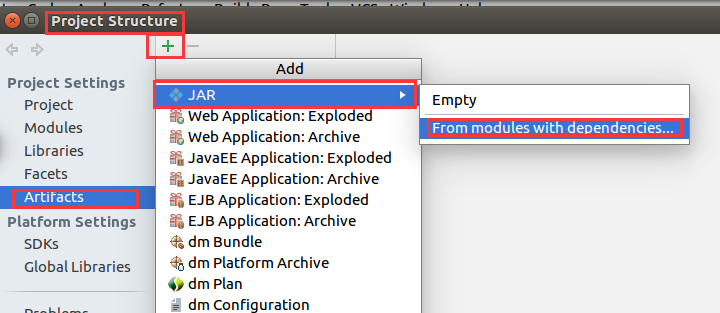
选main类对后,点击OK确定, 这个时候配置已经完成了, 我们就可以进行编译 jar文件了, 选择菜单Build->Build Artifacts..., 生成的文件路径为/out/artifacts/MovieLensALS_jar/MovieLensALS.jar
准备HADOOP环境
假设我们的HADOOP环境已经搭建成功。 接下来我们要把需要计算的数据文件上传到hadoop; 首先,在hadoop上面创建文件夹,命令如下:
hdfs dfs -mkdir -p /recommendation/data
上传数据文件命令如下:
hdfs dfs -put *.dat /recommendation/data
这时时候我们可以通过命令查看,上传是否成功
hdfs dfs -cat /recommendation/data/users.dat
运行

在上面红框中,指定了生成的jar文件名, 所在路径, 以及MainClass。这面就是通过spark执行:
/usr/local/spark/spark-2.3.0-bin-hadoop2.7/bin/spark-submit --master local --class "xyz.pl8.MovieLensALS" /home/hartifacts/movielensals_jar/movielensals.jar /recommendation/data
推荐系统-05-Spark电影推荐、评估与部署的更多相关文章
- SparkMLlib—协同过滤推荐算法,电影推荐系统,物品喜好推荐
SparkMLlib-协同过滤推荐算法,电影推荐系统,物品喜好推荐 一.协同过滤 1.1 显示vs隐式反馈 1.2 实例介绍 1.2.1 数据说明 评分数据说明(ratings.data) 用户信息( ...
- 数据算法 --hadoop/spark数据处理技巧 --(9.基于内容的电影推荐 10. 使用马尔科夫模型的智能邮件营销)
九.基于内容的电影推荐 在基于内容的推荐系统中,我们得到的关于内容的信息越多,算法就会越复杂(设计的变量更多),不过推荐也会更准确,更合理. 本次基于评分,提供一个3阶段的MR解决方案来实现电影推荐. ...
- 【大数据 Spark】利用电影观看记录数据,进行电影推荐
利用电影观看记录数据,进行电影推荐. 目录 利用电影观看记录数据,进行电影推荐. 准备 1.任务描述: 2.数据下载 3.部分数据展示 实操 1.设置输入输出路径 2.配置spark 3.读取Rati ...
- 利用Surprise包进行电影推荐
Surprise(Simple Python Recommendation System Engine)是一款推荐系统库,是scikit系列中的一个.简单易用,同时支持多种推荐算法(基础算法.协同过滤 ...
- Spark学习笔记——构建基于Spark的推荐引擎
推荐模型 推荐模型的种类分为: 1.基于内容的过滤:基于内容的过滤利用物品的内容或是属性信息以及某些相似度定义,来求出与该物品类似的物品. 2.协同过滤:协同过滤是一种借助众包智慧的途径.它利用大量已 ...
- 利用python实现电影推荐
"协同过滤"是推荐系统中的常用技术,按照分析维度的不同可实现"基于用户"和"基于产品"的推荐. 以下是利用python实现电影推荐的具体方法 ...
- 转利用python实现电影推荐
“协同过滤”是推荐系统中的常用技术,按照分析维度的不同可实现“基于用户”和“基于产品”的推荐. 以下是利用python实现电影推荐的具体方法,其中数据集源于<集体编程智慧>一书,后续的编程 ...
- 数据挖掘-MovieLens数据集_电影推荐_亲和性分析_Aprioro算法
#!/usr/bin/env python2 # -*- coding: utf-8 -*- """ Created on Tue Feb 7 14:38:33 201 ...
- 基于Azure构建PredictionIO和Spark的推荐引擎服务
基于Azure构建PredictionIO和Spark的推荐引擎服务 1. 在Azure构建Ubuntu 16.04虚拟机 假设前提条件您已有 Azure 帐号,登陆 Azure https://po ...
- Azure构建PredictionIO和Spark的推荐引擎服务
Azure构建PredictionIO和Spark的推荐引擎服务 1. 在Azure构建Ubuntu 16.04虚拟机 假设前提条件您已有 Azure 帐号,登陆 Azure https://port ...
随机推荐
- awr相关
手工生成awr快照SQL> exec dbms_workload_repository.create_snapshot; PL/SQL procedure successfully comple ...
- PostgreSQL常用查看命令
1. 查看当前库sehcma大小,并按schema排序 SELECT schema_name, pg_size_pretty(sum(table_size)::bigint) as "dis ...
- PostgreSQL常用函数
1.系统信息函数 1.会话信息函数 edbstore=# select current_catalog; #查询当前数据库名称 current_database ------------------ ...
- 一、SQLite学习
由于公司业务拓展,需要开发一个基于ASP.NET Core2.0+AdminLTE架构的后台管理系统,数据库选择方面,选择了使用SQLite轻便. SQLite:一个软件库,实现自给自足,无服务器,零 ...
- 二十三、Spring框架的相关知识点总结
1.Spring的优点: 1.1.Spring在大小和透明性方面是轻量级的,Spring框架大约只有2MB大小. 1.2.控制反转(IOC):使用控制反转技术实现了低耦合,依赖注入(DI)到对象,而不 ...
- 【转】Vue中mintui的field实现blur和focus事件
首先上代码说总结: <mt-field label="卡号" v-model="card.cardNo" @blur.native.capture=&qu ...
- JBoss/WildFly 初步安装配置教程
1.下载 Redhat的JBoss与Oracle的Weblogic.IBM的WebSphere并称三大JAVA EE中间件. JBoss AS是JBoss的开源版本,JBoss EAP是JBoss的企 ...
- POJ 1006 生理周期(中国剩余定理)
POJ 1006 生理周期 分析:中国剩余定理(注意结果要大于d即可) 代码: #include<iostream> #include<cstdio> using namesp ...
- Win10系列:VC++绘制几何图形4
三角形绘制完成以后,接下来介绍如何给项目添加主入口函数.打开D2DBasicAnimation.h头文件,添加如下的代码定义一个DirectXAppSource类. //定义类DirectXAppSo ...
- ASP.Net MVC(3) 之Razor视图引擎的基础语法
Razor视图引擎的基础语法: 1.“_”开头的cshtml文档将不能在服务器上访问,和asp.net中的config文档差不多. 2.Razor语法以@开头,以@{}进行包裹. 3.语法使用: 注释 ...