数据算法 --hadoop/spark数据处理技巧 --(9.基于内容的电影推荐 10. 使用马尔科夫模型的智能邮件营销)
九。基于内容的电影推荐
在基于内容的推荐系统中,我们得到的关于内容的信息越多,算法就会越复杂(设计的变量更多),不过推荐也会更准确,更合理。
本次基于评分,提供一个3阶段的MR解决方案来实现电影推荐。
1.找出各个电影的评分人总数
2.对于每个电影对A和B,找出所有同时对A和B评分的人。
3.找出每两个相关电影之间的关联。在这个阶段,我使用3个不同的关联度算法(pearson,cosine,jaccard)一般要根据具体的数据需求来选择关联度算法。
数据的输入格式:

第一阶段转化完之后:

经过MR阶段2的map阶段后:

经过排序和洗牌之后的输出:
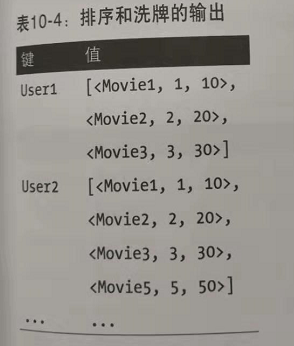
在经过MR阶段2的reduce()后:
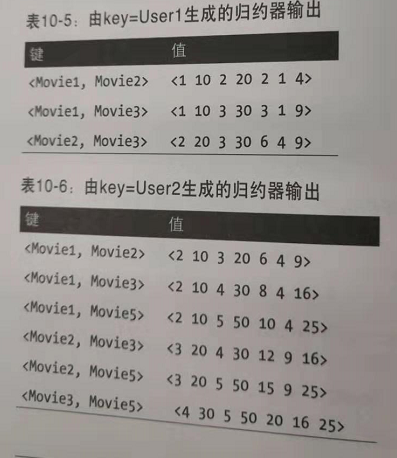
第三阶段MR的map阶段的输出:
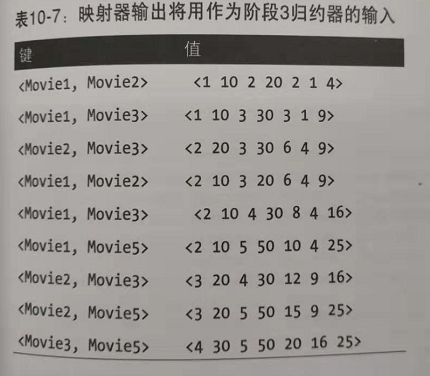
第三阶段MR的reduce的输入:
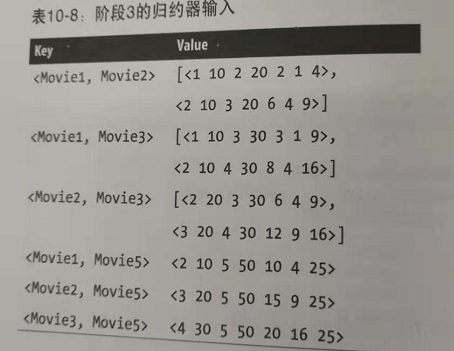
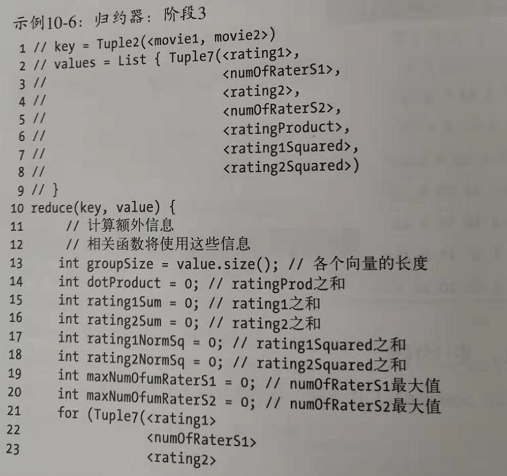
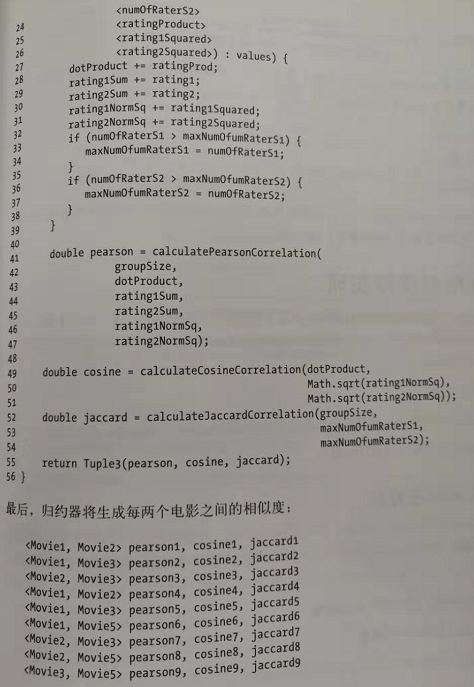
reduce代码:
spark的基本步骤:
1.导入所需要的类和接口;
2.处理输入参数;
3.创建一个spark上下文对象;
4.读取hdfs文件并创建第一个RDD;
5.找出谁曾对这个电影评分;
6.按movie对moviesRDD分组;
7.找出每个电影的评分人数,然后创建(K,V)为usersRDD = <K=user,V=<movie,rating,numberofRaters>>
8.将usersRDD与自身连接,找出所有(movie1,movie2)对 joinedRDD = userRDD.join(userRDD) joinedRDD= (user,T2((m1,r1,n1),(m2,r2,n2)))
9.删除重复的(movie1,movie2)对;
10生成所有的(movie1,movie2)组合。
11.按键(movie1,movie2)对moviePairs分组
12计算每个(movie1,movie2)对的关联度
十。使用马尔科夫模型的智能营销
先说说马尔科夫:


使用马尔科夫的智能营销的大致流程:
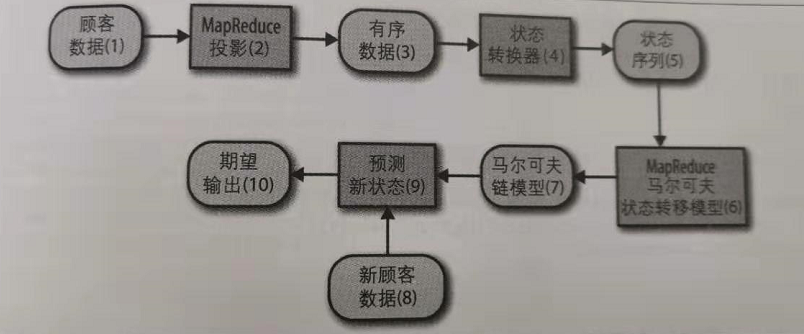
其中使用MR生成有序数据:可以采用之前说的二次排序的方式。
状态序列的生成:


采用的策略:

数据算法 --hadoop/spark数据处理技巧 --(9.基于内容的电影推荐 10. 使用马尔科夫模型的智能邮件营销)的更多相关文章
- 数据算法 --hadoop/spark数据处理技巧 --(5.移动平均 6. 数据挖掘之购物篮分析MBA)
五.移动平均 多个连续周期的时间序列数据平均值(按相同时间间隔得到的观察值,如每小时一次或每天一次)称为移动平均.之所以称之为移动,是因为随着新的时间序列数据的到来,要不断重新计算这个平均值,由于会删 ...
- 数据算法 --hadoop/spark数据处理技巧 --(1.二次排序问题 2. TopN问题)
一.二次排序问题. MR/hadoop两种方案: 1.让reducer读取和缓存给个定键的所有值(例如,缓存到一个数组数据结构中,)然后对这些值完成一个reducer中排序.这种方法不具有可伸缩性,因 ...
- 数据算法 --hadoop/spark数据处理技巧 --(3.左外连接 4.反转排序)
三. 左外连接 考虑一家公司,比如亚马逊,它拥有超过2亿的用户,每天要完成数亿次交易.假设我们有两类数据,用户和交易: users(user_id,location_id) transactions( ...
- 数据算法 --hadoop/spark数据处理技巧 --(17.小文件问题 18.MapReuce的大容量缓存)
十七.小文件问题 十八.MR的大容量缓存 在MR中使用和读取大容量缓存,(也就是说,可能包括数十亿键值对,而无法放在一个商用服务器的内存中).本次提出的算法通用,可以在任何MR范式中使用.(eg:MR ...
- 数据算法 --hadoop/spark数据处理技巧 --(11.K-均值聚类 12. k-近邻)
十一.k-均值聚类 这个需要MR迭代多次. 开始时,会选择K个点作为簇中心,这些点成为簇质心.可以选择很多方法啦初始化质心,其中一种方法是从n个点的样本中随机选择K个点.一旦选择了K个初始的簇质心,下 ...
- 数据算法 --hadoop/spark数据处理技巧 --(13.朴素贝叶斯 14.情感分析)
十三.朴素贝叶斯 朴素贝叶斯是一个线性分类器.处理数值数据时,最好使用聚类技术(eg:K均值)和k-近邻方法,不过对于名字.符号.电子邮件和文本的分类,则最好使用概率方法,朴素贝叶斯就可以.在某些情况 ...
- 数据算法 --hadoop/spark数据处理技巧 --(15.查找、统计和列出大图中的所有三角形 16.k-mer计数)
十五.查找.统计和列出大图中的所有三角形 第一步骤的mr: 第二部mr: 找出三角形 第三部:去重 spark: 十六: k-mer计数 spark:
- 数据算法 --hadoop/spark数据处理技巧 --(7.共同好友 8. 使用MR实现推荐引擎)
七,共同好友. 在所有用户对中找出“共同好友”. eg: a b,c,d,g b a,c,d,e map()-> <a,b>,<b,c,d,g> ;< ...
- 基于隐马尔科夫模型(HMM)的地图匹配(Map-Matching)算法
文章目录 1. 1. 摘要 2. 2. Map-Matching(MM)问题 3. 3. 隐马尔科夫模型(HMM) 3.1. 3.1. HMM简述 3.2. 3.2. 基于HMM的Map-Matchi ...
随机推荐
- 微信小程序---自定义三级联动
在开发的很多电商类型的项目中,免不了会遇到三级联动选择地址信息,如果单纯的使用文本框给用户选择,用户体检可能就会差很多.今天我给大家整理了关于小程序开发利用picker-view组件和animatio ...
- 【DPDK】【ring】从DPDK的ring来看无锁队列的实现
[前言] 队列是众多数据结构中最常见的一种之一.曾经有人和我说过这么一句话,叫做“程序等于数据结构+算法”.因此在设计模块.写代码时,队列常常作为一个很常见的结构出现在模块设计中.DPDK不仅是一个加 ...
- Egret学习-TiledMap使用
环境说明: 引擎版本:5.2.4 Egret Wing 4.1.6 1.下载依赖,下载地址https://github.com/egret-labs/egret-game-library/tree/m ...
- MyBatis5——Mybatis整合log4j、延迟加载
开启日志:Log4j (1)加入jar包 (2)在conf.xml中配置开启日志: <settings> <!-- 开启日志,并指定要使用的具体日志为log4j -- ...
- allegro设置内存分配器的一个坑
看过<游戏引擎架构>后我开始对内存的分配问题关注,一直想用内存分配器来管理游戏的内存.前两天发现了有许多第三方内存分配器可以用.最后挑中了nedmalloc,这个库也是ogre所使用的,测 ...
- c# 一维数组和二维数组的几种定义方式<转>
using System; using System.Collections.Generic; using System.Linq; using System.Text; namespace Cons ...
- SpringDataRedis入门到实战
1.项目常见问题思考 对于电商系统的广告后台管理和广告前台展示,首页每天有大量的人访问,对数据库造成很大的访问压力,甚至是瘫痪.那如何解决呢?我们通常的做法有两种:一种是数据缓存.一种是网页静态化.我 ...
- VirtualBox 虚拟机 从入门到入坑
...
- 深入并发锁,解析Synchronized锁升级
这篇文章分为六个部分,不同特性的锁分类,并发锁的不同设计,Synchronized中的锁升级,ReentrantLock和ReadWriteLock的应用,帮助你梳理 Java 并发锁及相关的操作. ...
- HTML5的基础学习
课前预习:HTML又被叫做超文本标记语言,它不是编程语言,是web中最微不足道的,但又是web中最微不足道的基石, 对零基础学习HTML的人员来说先认识HTML的标签和字体是必不可少的,万丈高楼平地起 ...