Phoenix系列:二级索引(1)
Phoenix使用HBase作为后端存储,对于HBase来说,我们通常使用字典序的RowKey来快速访问数据,除此之外,也可以使用自定义的Filter来搜索数据,但是它是基于全表扫描的。而Phoenix提供的二级索引是可以避开全表扫描,是在HBase中快速查找或批量检索数据的另一个选择。下面的例子使用如下表进行测试:
CREATE TABLE HAO1 ( id char(36) not null primary key, name varchar(50), age INTEGER, createtime DATE)
本文的SQL Client是SQuirrel 3.7.1。
覆盖索引 Covered Indexes
Phoenix提供了一种叫Covered Index覆盖索引的二级索引。这种索引在获取数据的过程中,内部不需要再去HBase上获取任何数据,你查询需要返回的列的数据都会被存储在索引中。要想达到这种效果,你的select 的列,where 的列都需要在索引中出现。举个例子,如果你的SQL语句是 select name from hao1 where age=2,要最大化查询效率和速度最快,你就需要建立覆盖索引:
CREATE INDEX index1_c ON hao1 (age) INCLUDE(name);
注意关键字INCLUDE,就是包含需要返回数据结果的列。这种索引方式的最大好处就是速度快,而我们也知道,索引就是空间换时间,所以缺点也很明显,存储空间耗费较多。Phoenix的索引其实就是建了一张HBase的表。你可以通过HBase Shell的list命令看到。查看表index1_c,你会发现,这张表一共三列,一列就是索引,第二列是RowKey,最后一列就是Name的值。很明显在这里记录的RowKey,就是为了快速查找HBase中的数据。只是这里用不到,Name已经被缓存在这张索引里面了,直接返回。

我们来看一下执行计划,首先看一下没有查询条件的计划,如下图,是一个全表扫描的计划:
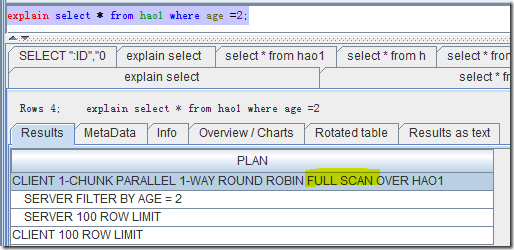
而加了索引以后,就是下图这样。很明显,已经是Range Scan,使用到了索引INDEX1_C。
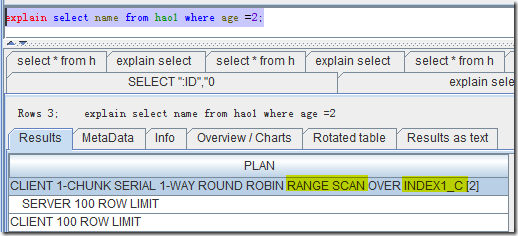
但要注意的是,如果是 select * from hao1 where age =2 的话,还是会看原数据表,只是使用RowKey去访问了,效率自然没有直接从索引表中回去。因为select 的其他列不在索引表内。
函数索引 Functional Indexes
函数索引从4.3版本就有,这种索引的内容不局限于列,还能在表达式上建立索引。如果你使用的表达式正好就是索引的话,数据也可以直接从这个索引获取,而不需要从数据库获取。比如说,在一个表达式上建立索引,这个表达式是UPPER(name) || '_test':
CREATE INDEX index2_f ON hao1 (UPPER(name) || '_test');
同样的index2_f表会被建立,里面存储了表达式求值后的结果,和RowKey的关系。当然也可以添加INCLUDE作为覆盖索引,做了覆盖索引,就不需要再去原数据表中获取数据。但是数据会多很多。

在索引范围上,Phoenix的索引可以分为全局索引和本地索引,两种索引适合的场景不同。
全局索引 Global Indexes
全局索引适合那些读多写少的场景。如果使用全局索引,读数据基本不损耗性能,所有的性能损耗都来源于写数据。数据表的添加、删除和修改都会更新相关的索引表(数据删除了,索引表中的数据也会删除;数据增加了,索引表的数据也会增加)。而查询数据的时候,Phoenix会通过索引表来快速低损耗的获取数据。默认情况下,如果你的查询语句中没有索引相关的列的时候,Phoenix不会使用索引。
本地索引 Local Indexes
本地索引适合那些写多读少,或者存储空间有限的场景。和全局索引一样,Phoenix也会在查询的时候自动选择是否使用本地索引。本地索引之所以是本地,只要是因为索引数据和真实数据存储在同一台机器上,这样做主要是为了避免网络数据传输的开销。如果你的查询条件没有完全覆盖索引列,本地索引还是可以生效。因为无法提前确定数据在哪个Region上,所以在读数据的时候,还需要检查每个Region上的数据而带来一些性能损耗。
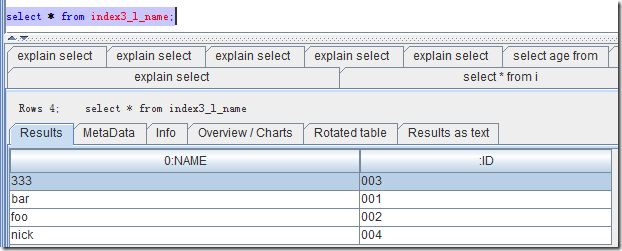
如下示例,创建了本地索引,然后查看了索引表的数据。
CREATE LOCAL INDEX index3_l_name ON hao1 (name);
异步创建索引
一般我们可以使用CREATE INDEX来创建一个索引,这是一种同步的方法。但是有时候我们创建索引的表非常大,我们需要等很长时间。Phoenix 4.5以后有一个异步创建索引的方式,使用关键字ASYNC来创建索引:
CREATE INDEX index1_c ON hao1 (age) INCLUDE(name) ASYNC;
这时候创建的索引表中不会有数据。你还必须要单独的使用命令行工具来执行数据的创建。当语句给执行的时候,后端会启动一个map reduce任务,只有等到这个任务结束,数据都被生成在索引表中后,这个索引才能被使用。启动工具的方法:
${HBASE_HOME}/bin/hbase org.apache.phoenix.mapreduce.index.IndexTool
--schema MY_SCHEMA --data-table MY_TABLE --index-table ASYNC_IDX
--output-path ASYNC_IDX_HFILES
这个任务不会因为客户端给关闭而结束,是在后台运行。你可以在指定的文件ASYNC_IDX_HFILES中找到最终实行的结果。
索引的使用
索引定义完之后,一般来说,Phoenix会判定使用哪个索引更加有效。但是,全局索引必须是查询语句中所有列都包含在全局索引中,它才会生效。举个例子,下面是创建索引的语句:
CREATE INDEX index1_c ON hao1 (age)
而查询语句是:
select name from hao1 where age = 35;
上例就不会用到索引index1_c。因为name并没有包含在索引中。所以使用全局索引,必须要所有的列都包含在索引中。那么怎样才能使用上索引呢?有三种方法。
1. 创建索引的时候使用覆盖索引。
CREATE INDEX index1_c ON hao1 (age) INCLUDE(name);
这种索引会把name加到索引表里面,同时name也会随着原数据表中的变化而变化。这种方式很明显的缺点是索引表的大小较大,然后就是全局索引不适合写特别多的情况。
2. 使用类似于Oracle的Hint,强制索引。
select /*+ INDEX(HAO1 index1_c)*/ name from hao1 where age = 35;
查询引擎会使用index1_c这个索引,由于它会发现索引表中没有name数据,所以每一行它都会去原数据表中获取name的值。这个强制索引只有在你认为索引有比较好的选择性的时候才是好的选择,也就是说age等于35的行数不多。不然的话,使用Phoenix默认的全表扫描的性能也许会更好。
3. 创建本地索引
CREATE LOCAL INDEX index1_c ON hao1 (age)
本地索引和全局索引不同的是,查询语句中,即使所有的列都不在索引定义中,它也会使用索引,这是本地索引的默认行为。Phoenix知道原数据和索引数据在同一个RegionServer上,能保证索引查找是本地的。
索引的删除
通过如下命令删除一个索引:
drop index index1_c ON hao1;
如果一个被索引的列被删除了,那么这个索引也会被自动删除。如果一个被覆盖索引的列被删除了,那么这个覆盖列也会自动从索引中删除。
Phoenix系列:二级索引(1)的更多相关文章
- Phoneix(三)HBase集成Phoenix创建二级索引
一.Hbase集成Phoneix 1.下载 在官网http://www.apache.org/dyn/closer.lua/phoenix/中选择提供的镜像站点中下载与安装的HBase版本对应的版本. ...
- phoenix创建二级索引
create table user (id varchar primary key, firstname varchar, lastname varchar); create index user_i ...
- [Phoenix] 五、二级索引
摘要: 目前HBASE只有基于字典序的主键索引,对于非主键过滤条件的查询都会变成扫全表操作,为了解决这个问题Phoenix引入了二级索引功能.然而此二级索引又有别于传统关系型数据库的二级索引,本文将详 ...
- phoenix中添加二级索引
Phoenix创建Hbase二级索引 官方文档 1. 配置Hbase支持Phoenix创建二级索引 1. 添加如下配置到Hbase的Hregionserver节点的hbase-site.xml ...
- 「从零单排HBase 12」HBase二级索引Phoenix使用与最佳实践
Phoenix是构建在HBase上的一个SQL层,能让我们用标准的JDBC APIs对HBase数据进行增删改查,构建二级索引.当然,开源产品嘛,自然需要注意“避坑”啦,阿丸会把使用方式和最佳实践都告 ...
- Apache Phoenix系列 | 从入门到精通(转载)
原文地址:https://cloud.tencent.com/developer/article/1498057 来源: 云栖社区 作者: 瑾谦 By 大数据技术与架构 文章简介:Phoenix是一个 ...
- Phoenix系列:二级索引(2)
上一篇介绍了Phoenix基于HBase的二级索引的基本知识,这一篇介绍一下和索引相关的一致性和优化相关内容. 一致性的保证 Phoenix客户端在成功提交一个操作并且得到成功响应后,就代表你所做的操 ...
- HBase的二级索引,以及phoenix的安装(需再做一次)
一:HBase的二级索引 1.讲解 uid+ts 11111_20161126111111:查询某一uid的某一个时间段内的数据 查询某一时间段内所有用户的数据:按照时间 索引表 rowkey:ts+ ...
- Phoenix二级索引(Secondary Indexing)的使用
摘要 HBase只提供了一个基于字典排序的主键索引,在查询中你只能通过行键查询或扫描全表来获取数据,使用Phoenix提供的二级索引,可以避免在查询数据时全表扫描,提高查过性能,提升查询效率 测试 ...
随机推荐
- linux -- 查看磁盘空间的大小
Ubuntu 查看磁盘空间大小命令 df -h Df命令是linux系统以磁盘分区为单位查看文件系统,可以加上参数查看磁盘剩余空间信息, 命令格式: df -hl 显示格式为: 文件系统 容量 已 ...
- 微信小程序页面带参数跳转及接收参数内容navigator
功能从index页面跳转到draw页面,并在draw页面获取id及imgUrl index.wxml <navigator class='looks-view' wx:for="{{i ...
- 在DevExpress程序中使用内置的图标构建美观的界面元素【转】
https://www.cnblogs.com/wuhuacong/p/6217012.html 在我们一般的程序中,为一般的界面元素添加一定的图标展示,有助于提升界面的整体的美观.结合排版布局,以及 ...
- C# System.Collections.SortedList
using System; using System.Collections; public class SamplesSortedList { public static void Main() { ...
- about the libiconv.2.dylib
https://stackoverflow.com/questions/5835847/libiconv-2-dylib-mac-os-x-problem https://blog.csdn.net/ ...
- 基于Ubuntu + nextCloud 搭建自己的私人网盘
系统要求:Ubuntu 16.04.1 LTS 64 位操作系统 基础设置 切换为 root 账号 Ubutu 系统默认登录的用户为非 root 权限用户,为了能正常安装 nextCloud,需要切换 ...
- JAVA常用代码
一. 判断是否包含某个注解. 1). 声明接口 @Retention(RetentionPolicy.RUNTIME) @Target(ElementType.TYPE) @Documented ...
- [AaronYang原创] 大话ASP.NET MVC3+ (C#与DOM与JS页面上的很炫的技巧)
案例一:比如我要传递一个新闻标题和新闻内容 存储到数据库去 1.最简单的通用Url公式就是 function getUrl() { var d = $("#表单ID").seria ...
- cocos2d-x与UIKit混合编程实现半透明效果
关键词 cocos2d-x, UIKit, transparent 问题 cocos2d-x使用一个专门的OpenGL View进行渲染, 它的渲染和UIKit是分开进行的, 因此我们使用时一般是把c ...
- CS页面-Asp.net+Spring.Net.Framework--SNF快速开发平台3.0
SNF快速平台有BS和CS两种,之前介绍了BS界面,下面发几张图看一下CS界面看看是什么样的 这是SNF快速开发平台的CS框架 1.有多种主页和登录页面. 2.多种页面风格 下面就先先看看页面显示的效 ...