一条SQL搞定信息增益的计算
欢迎大家关注腾讯云技术社区-博客园官方主页,我们将持续在博客园为大家推荐技术精品文章哦~
周东谕,2011年加入腾讯,现任职于腾讯互娱运营部数据中心,主要从事游戏相关的数据分析和挖掘工作。
信息增益原理介绍
介绍信息增益之前,首先需要介绍一下熵的概念,这是一个物理学概念,表示“一个系统的混乱程度”。系统的不确定性越高,熵就越大。假设集合中的变量X={x1,x2…xn},它对应在集合的概率分别是P={p1,p2…pn}。那么这个集合的熵表示为:
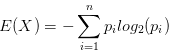
举一个的例子:对游戏活跃用户进行分层,分为高活跃、中活跃、低活跃,游戏A按照这个方式划分,用户比例分别为20%,30%,50%。游戏B按照这种方式划分,用户比例分别为5%,5%,90%。那么游戏A对于这种划分方式的熵为:
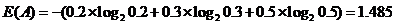
同理游戏B对于这种划分方式的熵为:
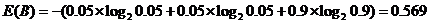
游戏A的熵比游戏B的熵大,所以游戏A的不确定性比游戏B高。用简单通俗的话来讲,游戏B要不就在上升期,要不就在衰退期,它的未来已经很确定了,所以熵低。而游戏A的未来有更多的不确定性,它的熵更高。
介绍完熵的概念,我们继续看信息增益。为了便于理解,我们还是以一个实际的例子来说明信息增益的概念。假设有下表样本
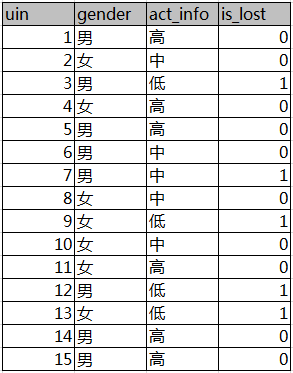 !
!
第一列为QQ,第二列为性别,第三列为活跃度,最后一列用户是否流失。我们要解决一个问题:性别和活跃度两个特征,哪个对用户流失影响更大?我们通过计算信息熵可以解决这个问题。
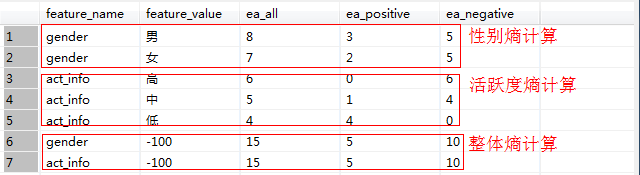
按照分组统计,我们可以得到如下信息:
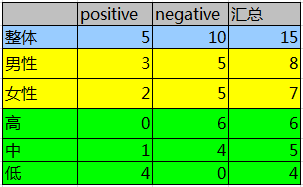
其中Positive为正样本(已流失),Negative为负样本(未流失),下面的数值为不同划分下对应的人数。那么可得到三个熵:
整体熵:
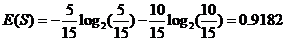
性别熵:
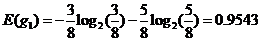
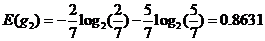
性别信息增益:
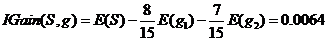
同理计算活跃度熵:
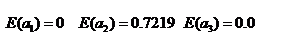
活跃度信息增益:
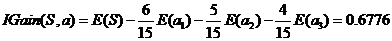
活跃度的信息增益比性别的信息增益大,也就是说,活跃度对用户流失的影响比性别大。在做特征选择或者数据分析的时候,我们应该重点考察活跃度这个指标。
使用Hive SQL实现信息熵的计算
从表2中我们不难发现,在计算信息熵和信息增益之前,需要对各维度做汇总计数,计算各公式中出现的分母。Hive SQL中,cube能帮助我们很快的做汇总计算,话不多说直接上代码:
SELECT
t1.feature_name,
SUM((ea_all/es)*EA) as gain,
SUM(NVL(-(ea_all/ES)*log2(ea_all/es),0)) as info,--计算信息增益率的分母
SUM((ea_all/es)*EA)/SUM(NVL(-(ea_all/es)*log2(ea_all/es),0)) as gain_rate--信息增益率计算
FROM
(
SELECT
feature_name,
feature_value,
ea_all,
--Key Step2 对于整体熵,要记得更换符号,NVL的出现是防止计算log2(0)得NULL
case
when feature_value='-100' then -(NVL((ea_positive/ea_all)*log2(ea_positive/ea_all),0)+NVL((ea_negative/ea_all)*log2(ea_negative/ea_all),0))
else (NVL((ea_positive/ea_all)*log2(ea_positive/ea_all),0)+NVL((ea_negative/ea_all)*log2(ea_negative/ea_all),0))
end as EA
FROM
(
SELECT
feature_name,
feature_value,
SUM(case when is_lost=-100 then user_cnt else 0 end) as ea_all,
SUM(case when is_lost=1 then user_cnt else 0 end) as ea_positive,
SUM(case when is_lost=0 then user_cnt else 0 end) as ea_negative
FROM
(
SELECT
feature_name,
--Key Step1 对feature值和label值做汇总统计,1、用于熵计算的分母,2、计算整体熵情况
case when grouping(feature_value)=1 then '-100' else feature_value end as feature_value,
case when grouping(is_lost)=1 then -100 else is_lost end as is_lost,
COUNT(1) as user_cnt
FROM
(
SELECT feature_name,feature_value,is_lost FROM gain_caculate
)GROUP BY feature_name,cube(feature_value,is_lost)
)GROUP BY feature_name,feature_value
)
)t1 join
(
--Key Step3信息增益计算时,需要给出样本总量作为分母
SELECT feature_name,COUNT(1) as es FROM gain_caculate
GROUP BY feature_name
)t2 on t1.feature_name=t2.feature_name
GROUP BY t1.feature_name
数据表结构如下:
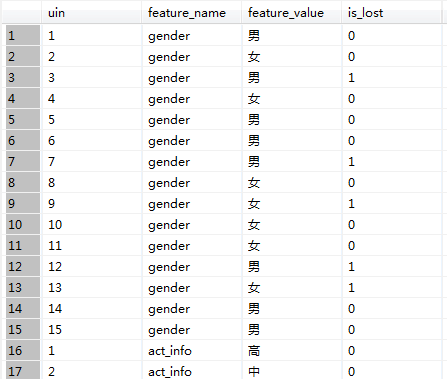
关键步骤说明:
KeyStep1:各特征的熵计算
KeyStep2:各feature下的信息增熵
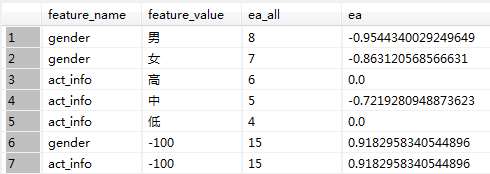
信息增益计算结果:

结束语:
以上为信息熵计算过程的SQL版本,其关键点在于使用cube实现了feature和label所需要的汇总计算。需要的同学只需要按照规定的表结构填入数据,修改SQL代码即可计算信息增益。文中如有不足的地方,还请各位指正。
参考文档
[1] 算法杂货铺——分类算法之决策树(Decision tree)
http://www.cnblogs.com/leoo2sk/archive/2010/09/19/decision-tree.html
[2] c4.5为什么使用信息增益比来选择特征?
https://www.zhihu.com/question/22928442
相关推荐
一条SQL搞定卡方检验计算
【腾讯云的1001种玩法】自建SQL Server迁移云SQL Server过程小记
小菜鸟对周志华大神gcForest的理解
此文已由作者授权腾讯云技术社区发布,转载请注明文章出处
原文链接:https://www.qcloud.com/community/article/826876001491038171
获取更多腾讯海量技术实践干货,欢迎大家前往腾讯云技术社区
一条SQL搞定信息增益的计算的更多相关文章
- 实战课堂 | DMS企业版教你用一条SQL搞定跨实例查询
背景 数据管理DMS企业版提供了安全.高效地管理大规模数据库的服务.面对多元的数据库实例,为了更方便地查询被“散落”在各个地方的业务数据,我们在DMS企业版中提供了跨数据库实例查询服务. 什么是跨实例 ...
- oracle 利用over 查询数据和总条数,一条sql搞定
select count(*) over()总条数 ,a.*from table a
- centos7以上安装python3,一条命令搞定。
直接复制下面的命令就搞定 yum install python34 python34-pip python34-setuptools 使用方法: python3 ---.py pip3 install ...
- sql分页 一条语句搞定
select top 每页条数 * from ( SELECT ROW_NUMBER() OVER (ORDER BY id desc) AS RowNumber,* FROM Article 条件 ...
- 四条命令搞定mysql主从
一 . 环境准备 先上拓扑图
- ORACLE 数据库的级联查询 一句sql搞定(部门多级)
在ORACLE 数据库中有一种方法可以实现级联查询 select * //要查询的字段 from table //具有子接点ID与父接点I ...
- 【网站建设】Linux上安装MySQL - 12条命令搞定MySql
从零开始安装mysql数据库 : 按照该顺序执行 : a. 查看是否安装有mysql:yum list installed mysql*, 如果有先卸载掉, 然后在进行安装; b. 安装mysql客 ...
- Linux上安装MySQL - 12条命令搞定MySql
从零开始安装mysql数据库 : 按照该顺序执行 : a. 查看是否安装有mysql:yum list installed mysql*, 如果有先卸载掉, 然后在进行安装; b. 安装mysql客 ...
- Oracle 使用MERGE INTO 语句 一条语句搞定新增编辑
MERGE INTO RDP_CHARTS_SETTING T1 USING (SELECT '10001' AS PAGE_ID, 'test' AS CHART_OPTION FROM DUAL) ...
随机推荐
- Windows 黑屏问题
这两天使用Microsoft Visual Studio编译项目,不断黑屏闪现!回想下应该是之前设置的DOS窗口全屏的原因. 记得又一次使用MSDOS,老感觉屏幕台下,于是就设置成了全屏显示,全屏后发 ...
- 基于nodejs模拟浏览器post请求爬取json数据
今天想爬取某网站的后台传来的数据,中间遇到了很多阻碍,花了2个小时才请求到数据,所以我在此总结了一些经验. 首先,放上我所爬取的请求地址http://api.chuchujie.com/api/?v= ...
- Repcached实现memcached复制
1.介绍 repcached是日本人开发的实现memcached复制功能,它是一个单 master单 slave的方案,但它的master/slave都是可读写的,而且可以相互同步,如果 ma ...
- Java反射机制深度剖析
版权声明:本文为博主原创文章,转载请注明出处,欢迎交流学习! Java反射机制是Java语言中一种很重要的机制,可能在工作中用到的机会不多,但是在很多框架中都有用到这种机制.我们知道Java是一门静态 ...
- 动态规划略有所得 数字三角形(POJ1163)
在上面的数字三角形中寻找一条从顶部到底边的路径,使得路径上所经过的数字之和最大.路径上的每一步都只能往左下或 右下走.只需要求出这个最大和即可,不必给出具体路径. 三角形的行数大于1小于等于100,数 ...
- Android Material Design 系列之 SnackBar详解
SnackBar是google Material Design提供的一种轻量级反馈组件.支持从布局的底部显示一个简洁的提示信息,支持手动滑动取消操作,同时在同一个时间内只能显示一个SnackBar. ...
- 因为本地没有配置 localhost 导致的 eclipse 的奇葩问题
因为电脑没有配置 127.0.0.1 localhost,已经碰到两次奇葩问题了. 问题一: 我的博文http://www.cnblogs.com/sonofelice/p/5143746.html中 ...
- self-question
需要即刻提升的几大能力: 1.重装系统和安装各种软件 2.自学能力,多从实际案例中总结,多归纳反思 3.拓展人际关系,和别人沟通交流 4.遇到困难迎刃而上,而不是回避退缩
- ZJOI2017 Day3 滚粗记
私のZJOI Day3 2017-3-21 07:52:53 今天,考了人生当中的第一次省选(虽然只是普及组三等奖但仍然有幸能体会一下).据胡老师说,这就是来体验一下被大神虐--真的是这样,听课听不懂 ...
- Fireworks快捷键大全和ps查看切图的坐标颜色
记住后方便了许多