Kaggle竞赛 —— 泰坦尼克号(Titanic)
完整代码见kaggle kernel 或 GitHub
比赛页面:https://www.kaggle.com/c/titanic
Titanic大概是kaggle上最受欢迎的项目了,有7000多支队伍参加,多年来诞生了无数关于该比赛的经验分享。正是由于前人们的无私奉献,我才能无痛完成本篇。
事实上kaggle上的很多kernel都聚焦于某个特定的层面(比如提取某个不为人知的特征、使用超复杂的算法、专做EDA画图之类的),当然因为这些作者本身大都是大神级别的,所以平日里喜欢钻研一些奇淫巧技。而我目前阶段更加注重一些整体流程化的方面,因此这篇提供了一个端到端的解决方案。
关于Titanic,这里先贴一段比赛介绍:
The sinking of the RMS Titanic is one of the most infamous shipwrecks in history. On April 15, 1912, during her maiden voyage, the Titanic sank after colliding with an iceberg, killing 1502 out of 2224 passengers and crew. This sensational tragedy shocked the international community and led to better safety regulations for ships.
One of the reasons that the shipwreck led to such loss of life was that there were not enough lifeboats for the passengers and crew. Although there was some element of luck involved in surviving the sinking, some groups of people were more likely to survive than others, such as women, children, and the upper-class.
In this challenge, we ask you to complete the analysis of what sorts of people were likely to survive. In particular, we ask you to apply the tools of machine learning to predict which passengers survived the tragedy.
主要是让参赛选手根据训练集中的乘客数据和存活情况进行建模,进而使用模型预测测试集中的乘客是否会存活。乘客特征总共有11个,以下列出。当然也可以根据情况自己生成新特征,这就是特征工程(feature engineering)要做的事情了。
- PassengerId => 乘客ID
- Pclass => 客舱等级(1/2/3等舱位)
- Name => 乘客姓名
- Sex => 性别
- Age => 年龄
- SibSp => 兄弟姐妹数/配偶数
- Parch => 父母数/子女数
- Ticket => 船票编号
- Fare => 船票价格
- Cabin => 客舱号
- Embarked => 登船港口
总的来说Titanic和其他比赛比起来数据量算是很小的了,训练集合测试集加起来总共891+418=1309个。因为数据少,所以很容易过拟合(overfitting),一些算法如GradientBoostingTree的树的数量就不能太多,需要在调参的时候多加注意。
下面我先列出目录,然后挑几个关键的点说明一下:
- 数据清洗(Data Cleaning)
- 探索性可视化(Exploratory Visualization)
- 特征工程(Feature Engineering)
- 基本建模&评估(Basic Modeling & Evaluation)
- 参数调整(Hyperparameters Tuning)
- 集成方法(Ensemble Methods)
数据清洗(Data Cleaning)
full.isnull().sum()
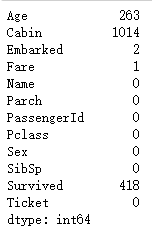
首先来看缺失数据,上图显示Age,Cabin,Embarked,Fare这些变量存在缺失值(Survived是预测值)。其中Embarked和Fare的缺失值较少,可以直接用众数和中位数插补。
Cabin的缺失值较多,可以考虑比较有Cabin数据和无Cabin数据的乘客存活情况。
pd.pivot_table(full,index=['Cabin'],values=['Survived']).plot.bar(figsize=(8,5))
plt.title('Survival Rate')
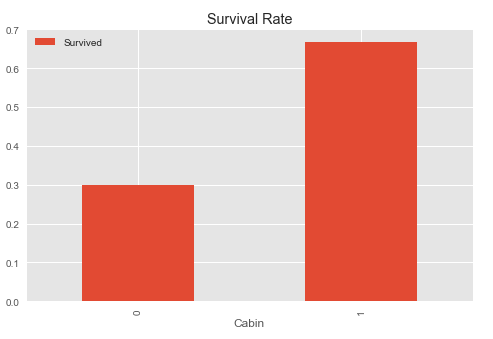
上面一张图显示在有Cabin数据的乘客的存活率远高于无Cabin数据的乘客,所以我们可以将Cabin的有无数据作为一个特征。
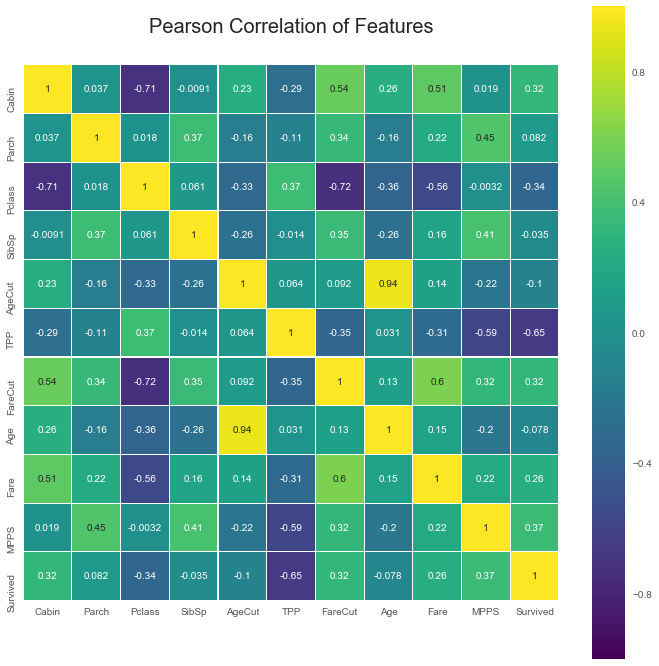
Age的缺失值有263个,网上有人说直接根据其他变量用回归模型预测Age的缺失值,我把训练集分成两份测试了一下,效果并不好,可能是因为Age和其他变量没有很强的相关性,从下面这张相关系数图也能看得出来。
所以这里采用的的方法是先根据‘Name’提取‘Title’,再用‘Title’的中位数对‘Age‘进行插补:
full['Title']=full['Name'].apply(lambda x: x.split(',')[1].split('.')[0].strip())
full.Title.value_counts()

Title中的Master主要代表little boy,然而却没有代表little girl的Title,由于小孩的生存率往往较高,所以有必要找出哪些是little girl,再填补Age的缺失值。
先假设little girl都没结婚(一般情况下该假设都成立),所以little girl肯定都包含在Miss里面。little boy(Master)的年龄最大值为14岁,所以相应的可以设定年龄小于等于14岁的Miss为little girl。对于年龄缺失的Miss,可以用(Parch!=0)来判定是否为little girl,因为little girl往往是家长陪同上船,不会一个人去。
以下代码创建了“Girl”的Title,并以Title各自的中位数填补Age缺失值。
def girl(aa):
if (aa.Age!=999)&(aa.Title=='Miss')&(aa.Age<=14):
return 'Girl'
elif (aa.Age==999)&(aa.Title=='Miss')&(aa.Parch!=0):
return 'Girl'
else:
return aa.Title full['Title']=full.apply(girl,axis=1) Tit=['Mr','Miss','Mrs','Master','Girl','Rareman','Rarewoman']
for i in Tit:
full.loc[(full.Age==999)&(full.Title==i),'Age']=full.loc[full.Title==i,'Age'].median()
至此,数据中已无缺失值。
探索性可视化(Exploratory Visualization)
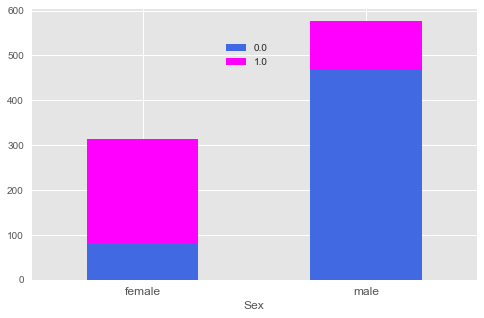
普遍认为泰坦尼克号中女人的存活率远高于男人,如下图所示:
pd.crosstab(full.Sex,full.Survived).plot.bar(stacked=True,figsize=(8,5),color=['#4169E1','#FF00FF'])
plt.xticks(rotation=0,size='large')
plt.legend(bbox_to_anchor=(0.55,0.9))
下图显示年龄与存活人数的关系,可以看出小于5岁的小孩存活率很高。

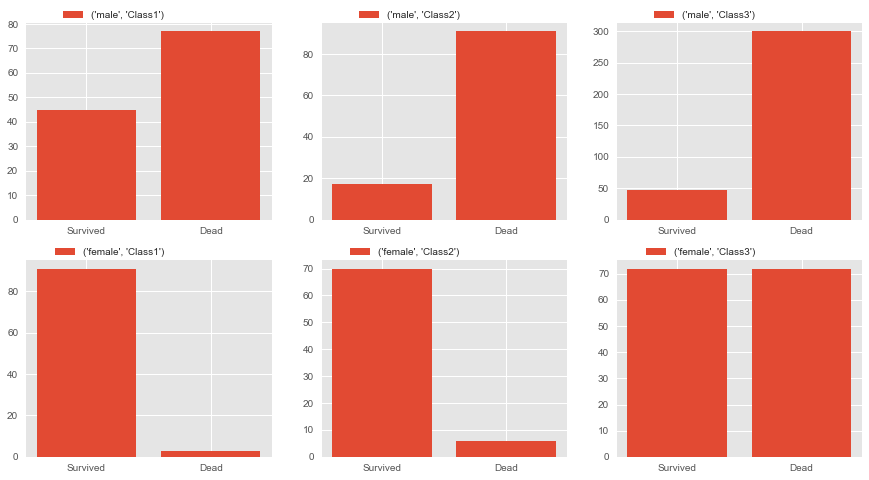
客舱等级(Pclass)自然也与存活率有很大关系,下图显示1号仓的存活情况最好,3号仓最差。
fig,axes=plt.subplots(2,3,figsize=(15,8))
Sex1=['male','female']
for i,ax in zip(Sex1,axes):
for j,pp in zip(range(1,4),ax):
PclassSex=full[(full.Sex==i)&(full.Pclass==j)]['Survived'].value_counts().sort_index(ascending=False)
pp.bar(range(len(PclassSex)),PclassSex,label=(i,'Class'+str(j)))
pp.set_xticks((0,1))
pp.set_xticklabels(('Survived','Dead'))
pp.legend(bbox_to_anchor=(0.6,1.1))
特征工程(Feature Engineering)
我将‘Title‘、’Pclass‘,’Parch‘三个变量结合起来画了这张图,以平均存活率的降序排列,然后以80%存活率和50%存活率来划分等级(1,2,3),产生新的’MPPS‘特征。
TPP.plot(kind='bar',figsize=(16,10))
plt.xticks(rotation=40)
plt.axhline(0.8,color='#BA55D3')
plt.axhline(0.5,color='#BA55D3')
plt.annotate('80% survival rate',xy=(30,0.81),xytext=(32,0.85),arrowprops=dict(facecolor='#BA55D3',shrink=0.05))
plt.annotate('50% survival rate',xy=(32,0.51),xytext=(34,0.54),arrowprops=dict(facecolor='#BA55D3',shrink=0.05))

基本建模&评估(Basic Modeling & Evaluation)
选择了7个算法,分别做交叉验证(cross-validation)来评估效果:
- K近邻(k-Nearest Neighbors)
- 逻辑回归(Logistic Regression)
- 朴素贝叶斯分类器(Naive Bayes classifier)
- 决策树(Decision Tree)
- 随机森林(Random Forest)
- 梯度提升树(Gradient Boosting Decision Tree)
- 支持向量机(Support Vector Machine)
由于K近邻和支持向量机对数据的scale敏感,所以先进行标准化(standard-scaling):
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
X_scaled=scaler.fit(X).transform(X)
test_X_scaled=scaler.fit(X).transform(test_X)
最后的评估结果如下: 逻辑回归,梯度提升树和支持向量机的效果相对较好。
# used scaled data
names=['KNN','LR','NB','Tree','RF','GDBT','SVM']
for name, model in zip(names,models):
score=cross_val_score(model,X_scaled,y,cv=5)
print("{}:{},{}".format(name,score.mean(),score))

接下来可以挑选一个模型进行错误分析,提取该模型中错分类的观测值,寻找其中规律进而提取新的特征,以图提高整体准确率。
用sklearn中的KFold将训练集分为10份,分别提取10份数据中错分类观测值的索引,最后再整合到一块。
# extract the indices of misclassified observations
rr=[]
for train_index, val_index in kf.split(X):
pred=model.fit(X.ix[train_index],y[train_index]).predict(X.ix[val_index])
rr.append(y[val_index][pred!=y[val_index]].index.values) # combine all the indices
whole_index=np.concatenate(rr)
len(whole_index)
先查看错分类观测值的整体情况:
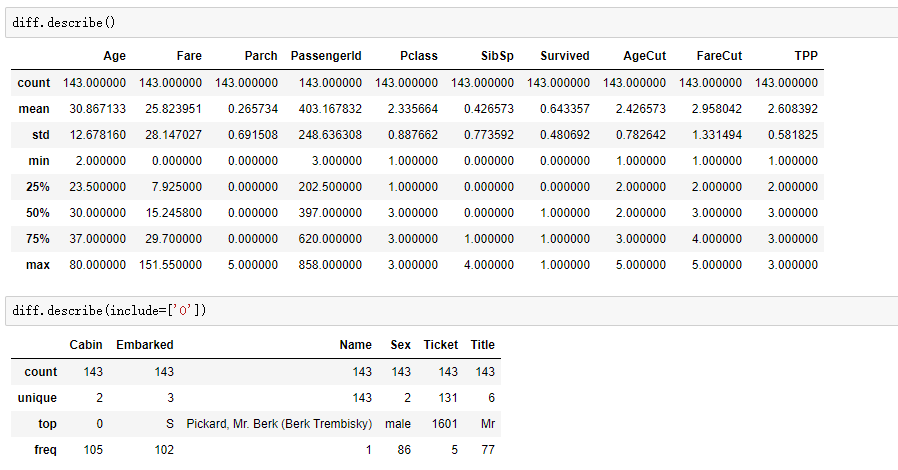
下面通过分组分析可发现:错分类的观测值中男性存活率高达83%,女性的存活率则均不到50%,这与我们之前认为的女性存活率远高于男性不符,可见不论在男性和女性中都存在一些特例,而模型并没有从现有特征中学习到这些。
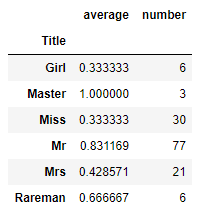
通过进一步分析我最后新加了个名为”MPPS”的特征。
full.loc[(full.Title=='Mr')&(full.Pclass==1)&(full.Parch==0)&((full.SibSp==0)|(full.SibSp==1)),'MPPS']=1
full.loc[(full.Title=='Mr')&(full.Pclass!=1)&(full.Parch==0)&(full.SibSp==0),'MPPS']=2
full.loc[(full.Title=='Miss')&(full.Pclass==3)&(full.Parch==0)&(full.SibSp==0),'MPPS']=3
full.MPPS.fillna(4,inplace=True)
参数调整(Hyperparameters tuning)
这部分没什么好说的,选定几个参数用grid search死命调就是了~
param_grid={'n_estimators':[100,120,140,160],'learning_rate':[0.05,0.08,0.1,0.12],'max_depth':[3,4]}
grid_search=GridSearchCV(GradientBoostingClassifier(),param_grid,cv=5)
grid_search.fit(X_scaled,y)
grid_search.best_params_,grid_search.best_score_
({'learning_rate': 0.12, 'max_depth': 4, 'n_estimators': 100}, 0.85072951739618408)
通过调参,Gradient Boosting Decision Tree能达到85%的交叉验证准确率,迄今为止最高。
集成方法(Ensemble Methods)
我用了三种集成方法:Bagging、VotingClassifier、Stacking。
调参过的单个算法和Bagging以及VotingClassifier的总体比较如下:
names=['KNN','LR','NB','CART','RF','GBT','SVM','VC_hard','VC_soft','VCW_hard','VCW_soft','Bagging']
for name,model in zip(names,models):
score=cross_val_score(model,X_scaled,y,cv=5)
print("{}: {},{}".format(name,score.mean(),score))

scikit-learn中目前没有stacking的实现方法,所以我参照了这两篇文章中的实现方法:
https://dnc1994.com/2016/04/rank-10-percent-in-first-kaggle-competition/
https://www.kaggle.com/arthurtok/introduction-to-ensembling-stacking-in-python
我用了逻辑回归、K近邻、支持向量机、梯度提升树作为第一层模型,随机森林作为第二层模型。
from sklearn.model_selection import StratifiedKFold
n_train=train.shape[0]
n_test=test.shape[0]
kf=StratifiedKFold(n_splits=5,random_state=1,shuffle=True) def get_oof(clf,X,y,test_X):
oof_train=np.zeros((n_train,))
oof_test_mean=np.zeros((n_test,))
oof_test_single=np.empty((5,n_test))
for i, (train_index,val_index) in enumerate(kf.split(X,y)):
kf_X_train=X[train_index]
kf_y_train=y[train_index]
kf_X_val=X[val_index] clf.fit(kf_X_train,kf_y_train) oof_train[val_index]=clf.predict(kf_X_val)
oof_test_single[i,:]=clf.predict(test_X)
oof_test_mean=oof_test_single.mean(axis=0)
return oof_train.reshape(-1,1), oof_test_mean.reshape(-1,1) LR_train,LR_test=get_oof(LogisticRegression(C=0.06),X_scaled,y,test_X_scaled)
KNN_train,KNN_test=get_oof(KNeighborsClassifier(n_neighbors=8),X_scaled,y,test_X_scaled)
SVM_train,SVM_test=get_oof(SVC(C=4,gamma=0.015),X_scaled,y,test_X_scaled)
GBDT_train,GBDT_test=get_oof(GradientBoostingClassifier(n_estimators=120,learning_rate=0.12,max_depth=4),X_scaled,y,test_X_scaled) stack_score=cross_val_score(RandomForestClassifier(n_estimators=1000),X_stack,y_stack,cv=5)
# cross-validation score of stacking
stack_score.mean(),stack_score
Stacking的最终结果:
0.84069254167070062, array([ 0.84916201, 0.79888268, 0.85393258, 0.83707865, 0.86440678]))
总的来说根据交叉验证的结果,集成算法并没有比单个算法提升太多,原因可能是:
- 开头所说Titanic这个数据集太小,模型没有得到充分的训练
- 集成方法中子模型的相关性太强
- 集成方法可能本身也需要调参
- 我实现的方法错了???
最后是提交结果:
pred=RandomForestClassifier(n_estimators=500).fit(X_stack,y_stack).predict(X_test_stack)
tt=pd.DataFrame({'PassengerId':test.PassengerId,'Survived':pred})
tt.to_csv('submission.csv',index=False)
Kaggle竞赛 —— 泰坦尼克号(Titanic)的更多相关文章
- 数据挖掘竞赛kaggle初战——泰坦尼克号生还预测
1.题目 这道题目的地址在https://www.kaggle.com/c/titanic,题目要求大致是给出一部分泰坦尼克号乘船人员的信息与最后生还情况,利用这些数据,使用机器学习的算法,来分析预测 ...
- 初窥Kaggle竞赛
初窥Kaggle竞赛 原文地址: https://www.dataquest.io/mission/74/getting-started-with-kaggle 1: Kaggle竞赛 我们接下来将要 ...
- 《Python机器学习及实践:从零开始通往Kaggle竞赛之路》
<Python 机器学习及实践–从零开始通往kaggle竞赛之路>很基础 主要介绍了Scikit-learn,顺带介绍了pandas.numpy.matplotlib.scipy. 本书代 ...
- Kaggle入门——泰坦尼克号生还者预测
前言 这个是Kaggle比赛中泰坦尼克号生存率的分析.强烈建议在做这个比赛的时候,再看一遍电源<泰坦尼克号>,可能会给你一些启发,比如妇女儿童先上船等.所以是否获救其实并非随机,而是基于一 ...
- 如何使用Python在Kaggle竞赛中成为Top15
如何使用Python在Kaggle竞赛中成为Top15 Kaggle比赛是一个学习数据科学和投资时间的非常的方式,我自己通过Kaggle学习到了很多数据科学的概念和思想,在我学习编程之后的几个月就开始 ...
- 《机器学习及实践--从零开始通往Kaggle竞赛之路》
<机器学习及实践--从零开始通往Kaggle竞赛之路> 在开始说之前一个很重要的Tip:电脑至少要求是64位的,这是我的痛. 断断续续花了个把月的时间把这本书过了一遍.这是一本非常适合基于 ...
- 由Kaggle竞赛wiki文章流量预测引发的pandas内存优化过程分享
pandas内存优化分享 缘由 最近在做Kaggle上的wiki文章流量预测项目,这里由于个人电脑配置问题,我一直都是用的Kaggle的kernel,但是我们知道kernel的内存限制是16G,如下: ...
- kaggle竞赛分享:NFL大数据碗(上篇)
kaggle竞赛分享:NFL大数据碗 - 上 竞赛简介 一年一度的NFL大数据碗,今年的预测目标是通过两队球员的静态数据,预测该次进攻推进的码数,并转换为该概率分布: 竞赛链接 https://www ...
- Kaggle竞赛入门:决策树算法的Python实现
本文翻译自kaggle learn,也就是kaggle官方最快入门kaggle竞赛的教程,强调python编程实践和数学思想(而没有涉及数学细节),笔者在不影响算法和程序理解的基础上删除了一些不必要的 ...
随机推荐
- 字符串数组与字符串之间的互转(join/split)
1.Java 1-1.字符串数组=>字符串:StringUtils: join(Object[] array, String separator) 例: Java代码 收藏代码 import o ...
- php session_start()报错 解决办法
1.php.ini中的output_buffering=off 改成output_buffering=4096 2.php.ini中的session.save_path是否设置好了 3.php.ini ...
- Vue和Bootstrap的整合之路
我是一个刚刚接触前端开发的新手,所以有必要记录如何将Bootstrap和Vue进行整合. 如果你是老手,请直接绕道而过.作为一个新手,里面的步骤,过程或者专业术语未必正确,如果你发现哪里错误了,请发邮 ...
- 微信小程序的开发环境搭建(Windows版本)
前言: 小程序是指微信公众平台小程序,小程序可以帮助开发者快速的开发小程序,小程序可以在微信内被便捷地获取和传播:是一种不需要下载安装即可使用的应用小程序,和原有的三种公众号是并行的体系.2017年1 ...
- JavaScript 定义 类
JavaScript 定义 类 一 构建类的原则 构造函数 等于 原型的constructor //构造函数 function Hero(name,skill){ this.name = name; ...
- java 关于 hashmap 的实现原理的测试
网上关于HashMap的工作原理的文章多了去了,所以我也不打算再重复别人的文章.我就是有点好奇,我怎么样能更好的理解他的原理,或者说使用他的特性呢?最好的开发就是测试~ 虽说不详讲hashmap的工作 ...
- spring注解@service("service")括号中的service有什么用
相当于 xml配置中得 bean id = service 也可以不指定 不指定相当于 bean id = com. service.service 就是这个类的全限定名 好处是:同一个接口可以有多个 ...
- DotNetCore跨平台~EFCore连接Mysql的方式
回到目录 在.net frameworks的ef里连接mysql我们已经测试通过了,而在dotnet core里的efCore上去连接mysql我们需要测试一下,并且在测试过程中出现了一些问题,当然最 ...
- 集群之mysql主从配置(windows和linux版)
起因 由于网站进一步开发运行的需求,要求主机7*24小时运行正常,同时要求能够防止数据库灾难.考虑到后期的开发程度和业务量,准备向高可用系统进行改变,同时通过负载均衡提高网络性能.于是第一步就考虑到了 ...
- Oracle PIVOT 行转列方法
数据库中業種的存储如下图: SELECT * FROM M_TORIHIKISAKI_GYOSYU 其中GYIUSYU_CD字段代表不同的業種 而画面需要实现下图所示样式:(将每条数据的業種横向展开显 ...