python爬虫之win7Mongod安装使用
1、下载地址:https://www.mongodb.com/download-center#community
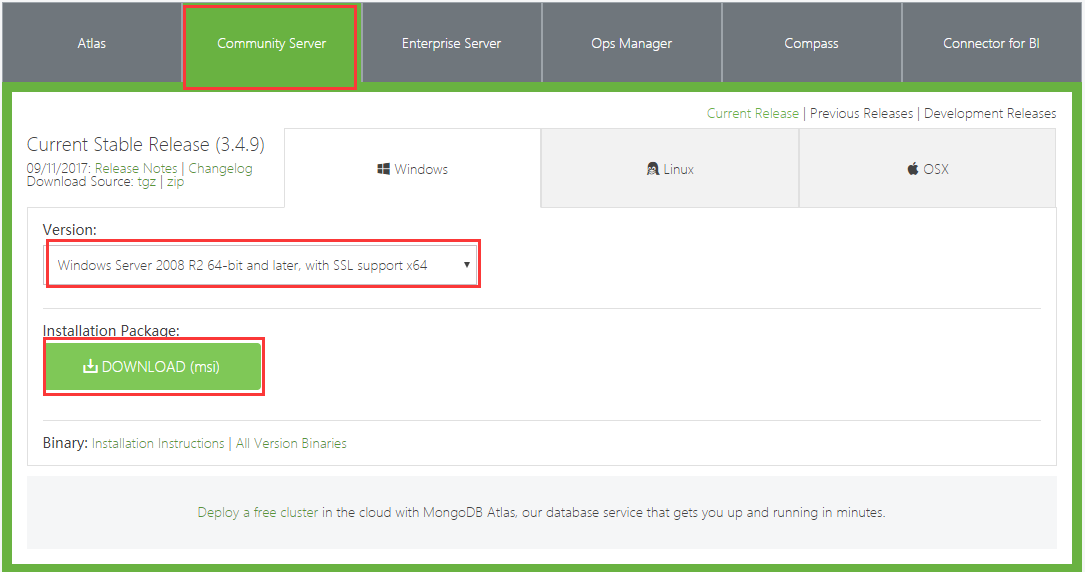
下载完成以后下一步下一步安装。
安装路径
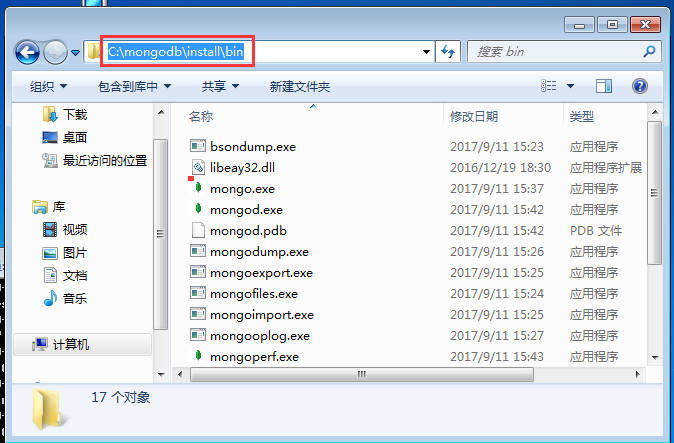
还需要建立一个数据库存储位置C:\mongodb\data\db

2、添加环境变量,然后打开cmd执行如下命令告诉数据库数据存储位置。
#mongod --dbpath C:\mongodb\data\db
然后测试一下是否成功:
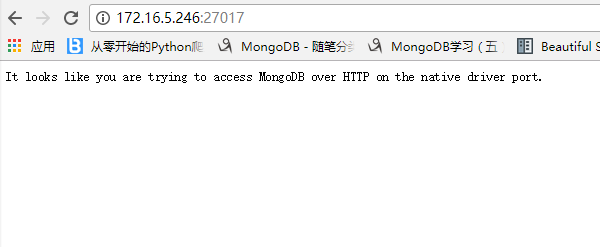
执行上面的命令时候的cmd对话框先不要关闭,然后再打开一个cmd框输入mongodb:
它告诉你已经连接上了,现在就可以执行mongodb的命令了

3、建立日志文件
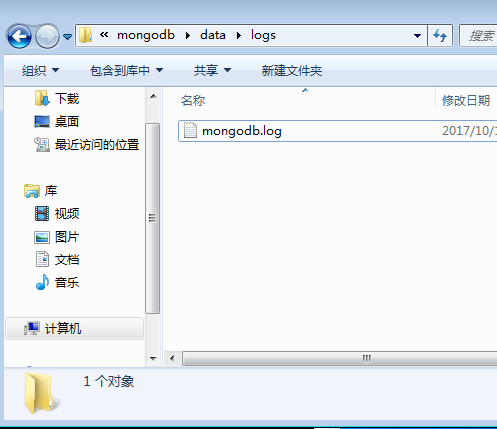
4、配置成服务:
因为我已经配置了环境变量所以直接敲mongod命令即可(注意:命令中的双引号放到cmd里面可就不一定了,需要手动更改,这里还可能有个问题,你是看不到MongoDB这个服务的,不过你使用net start MongoDB这个命令启动后,就能看到了,但是报一个什么错误,你服务停掉后,直接修复,再启动服务器就可以了,我这是3.2的版本,原来3.0并没有发现这个问题)。
#mongod --bind_ip 0.0.0.0 --logpath “C:\mongodb\data\logs\mongodb.log” --logappend --dbpath “C:\mongodb\data\db” --port 27017 --serviceName "MongoDB" --serviceDisplayName "MongoDB" --install
--bind_ip 运行访问ip,设为所有
--logpath 日志路径及文件名
--logappend 日志以追加的方式存储
--dbpath mongodb数据库安装路径
--port 27017 端口号
--serviceName 服务名称
--serviceDisplayName 服务名称
检查:
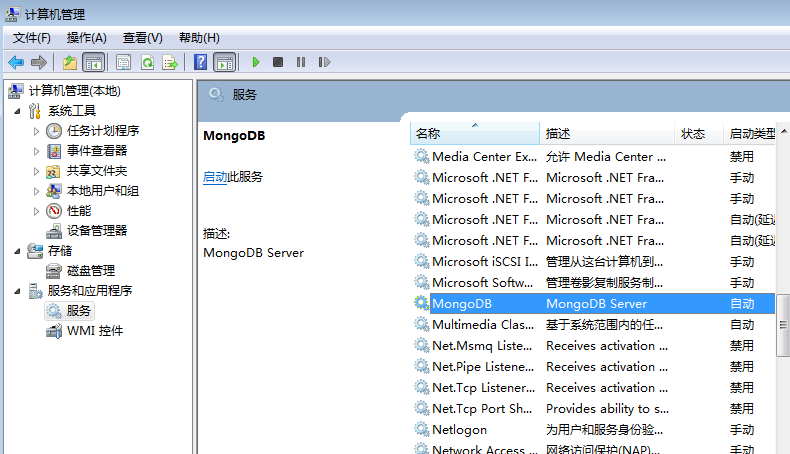
MongoDB可视化工具可参考Robomongo工具
https://robomongo.org/download
python爬虫之win7Mongod安装使用的更多相关文章
- 1,Python爬虫环境的安装
前言 很早以前就听说了Python爬虫,但是一直没有去了解:想着先要把一个方面的知识学好再去了解其他新兴的技术. 但是现在项目有需求,要到网上爬取一些信息,然后做数据分析.所以便从零开始学习Pytho ...
- Python爬虫框架Scrapy安装使用步骤
一.爬虫框架Scarpy简介Scrapy 是一个快速的高层次的屏幕抓取和网页爬虫框架,爬取网站,从网站页面得到结构化的数据,它有着广泛的用途,从数据挖掘到监测和自动测试,Scrapy完全用Python ...
- python爬虫之scrapy安装(一)
简介: Scrapy,Python开发的一个快速.高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据挖掘.监测和自动化测试. Scrap ...
- python爬虫的scrapy安装+pymongo的安装
我的:python2.7版本 32位 注意scrapy只支持2.7及以上的版本. 1.安装python 2.安装pip 安装pip就不赘述了,网上很多教学 pip安装时要注意更新,如果pip版本 ...
- python爬虫之Anaconda安装
Anaconda概述 Anaconda是一个用于科学计算的Python发行版,支持 Linux, Mac, Windows系统,提供了包管理与环境管理的功能,可以很方便地解决多版本python并存.切 ...
- python爬虫框架—Scrapy安装及创建项目
linux版本安装 pip3 install scrapy 安装完成 windows版本安装 pip install wheel 下载twisted,网址:http://www.lfd.uci.edu ...
- Python爬虫常用库安装
建议更换pip源到国内镜像,下载会快很多:https://www.cnblogs.com/believepd/p/10499844.html requests pip3 install request ...
- Python爬虫框架--Scrapy安装以及简单实用
scrapy框架 框架 -具有很多功能且具有很强通用性的一个项目模板 环境安装: Linux: pip3 install scrapy Windows: ...
- Python爬虫常用模块安装
安装:pip3 install requestspip3 install seleniumpip3 install bs4pip3 install pyquerypip3 install pymysq ...
随机推荐
- Python代码分行问题
可以用“\”符号把一行过长的Python代码分解成几行,多个语句也可以写在同一行,语句之间要用“;”隔开.
- Node.js读取某个目录下的所有文件夹名字并将其写入到json文件
针对解决的问题是,有些时候我们需要读取某个文件并将其写入到对应的json文件(xml文件也行,不过目前用json很多,json是主流). 源码如下:index.js var fs = require( ...
- Flask 框架 重定向,捕获异常,钩子方法及使用jsonify在网页返回json数据
Flask 框架中常用到重定向方法来实现路由的跳转 ,路由跳转又分为站内跳转和站外跳转 常用的站内跳转方法为url_for 而常用的站外跳转为redirect 在这里提示一下: 在使用两种方法是须调 ...
- freopen
一定要记住哇 求求你了 记住吧 freopen("balabala.in","r",stdin); freopen("balabala.out&quo ...
- python:利用logbook模块管理日志
日志管理作为软件项目的通用部分,无论是开发还是自动化测试过程中,都显得尤为重要. 最初是打算利用python的logging模块来管理日志的,后来看了些github及其他人的自动化框架设计,做了个比对 ...
- Jenkins集成openshift容器中进行代码扫描
1.Dockerfile sonarDockerfile: (基础slave镜像参考上篇博文) FROM registry.it.com/openshift/jenkins-slave:latest ...
- kafka模型理解
1.消息发送至一个topic,而这个topic可以由多个partition组成,每条消息在partition中的位置称为offset 2.消息存在有效期,如果设置为2天,则消息2天后会被删除 3.每个 ...
- 断路器(Curcuit Breaker)模式
在分布式环境下,特别是微服务结构的分布式系统中, 一个软件系统调用另外一个远程系统是非常普遍的.这种远程调用的被调用方可能是另外一个进程,或者是跨网路的另外一台主机, 这种远程的调用和进程的内部调用最 ...
- Java系统高并发之Redis后端缓存优化
一:前端优化 暴露接口,按钮防重复(点击一次按钮后就变成禁用,禁止重复提交) 采用CDN存储静态化的页面和一些静态资源(css,js等) 二:Redis后端缓存优化 Redis 是完全开源免费的,遵守 ...
- A2D JS框架 - loadScript实现
其实这个功能比较小,本着自己造轮子的优良传统....就自己造一个好了 <head> <title></title> <script src="A2D ...