第十六节、特征描述符BRIEF(附源码)
我们已经知道SIFT算法采用128维的特征描述子,由于描述子用的是浮点数,所以它将会占用512字节的空间。类似的SUFR算法,一般采用64维的描述子,它将占用256字节的空间。如果一幅图像中有1000个特征点,那么SIFT或SURF特征描述子将占用大量的内存空间,对于那些资源紧张的应用,尤其是嵌入式的应用,这样的特征描述子显然是不可行的。而且,越占有越大的空间,意味着越长的匹配时间。
但是实际上SIFT或SURF的特征描述子中,并不是所有维都在匹配中有着实质性的作用。我们可以用PCA、LDA等特征降维的方法来压缩特征描述子的维度。还有一些算法,例如局部敏感哈希(Locality-Sensitive Hashing, LSH),将SIFT的特征描述子转换为一个二值的码串,然后这个码串用汉明距离进行特征点之间的匹配。这种方法将大大提高特征之间的匹配,因为汉明距离的计算可以用异或操作然后计算二进制位数来实现,在现代计算机结构中很方便。下面我们来提取一种二值码串的特征描述子。
一 BRIEF简述
BRIEF(Binary Robust Independent Elementary Features)应运而生,它提供了一种计算二值化的捷径,并不需要计算一个类似于SIFT的特征描述子。它需要先平滑图像,然后在特征点周围选择一个Patch,在这个Patch内通过一种选定的方法来挑选出来$n_d$个点对。然后对于每一个点对$(p,q)$,我们比较这两个点的亮度值,如果$I(p)<I(q)$,则对应在二值串中的值为1,否则为0,。所有$n_d$个点对,都进行比较之间,我们就生成了一个$n_d$长的二进制串。
对于$n_d$的选择,我们可以设置为128,256或者512,这三个参数在OpenCV中都有提供,但是OpenCV中默认的参数是256,这种情况下,经过大量实验数据测试,不匹配的特征点的描述子的汉明距离在128左右,匹配点对描述子的汉明距离则远小于128。一旦维数选定了,我们就可以用汉明距离来匹配这些描述子了。
我们总结一下特征描述子的建立过程:
- 利用Harris或者FAST等方法检测特征点;
- 选定建立特征描述子的区域(特征点的一个正方形邻域);
- 对该邻域用$\sigma=2$窗口尺寸为9的的高斯核卷积,以消除一些噪声。因为该特征描述子随机性强,对噪声较为敏感;
- 以一定的随机化算法生成点对$(p,q)$,若点$I(p)<I(q)$的亮度,则返回1,否则返回0;
- 重复第三步若干次(如256次),得到一个256位的二进制码串,即该特征点的描述子;
值得注意的是,对于BRIEF,它仅仅是一种特征描述符,它不提供提取特征点的方法。所以,如果你必须使一种特征点定位的方法,如FAST、SIFT、SURF等。这里,我们将使用CenSurE方法来提取关键点,对BRIEF来说,CenSurE的表现比SURF特征点稍好一些。
总体来说,BRIEF是一个效率很高的提取特征描述子的方法,我们总结一下该特征描述子的优缺点:
首先,它抛弃了传统的利用图像局部邻域的灰度直方图或梯度直方图提取特征方法,改用检测随机响应,大大加快了描述子的建立速度;生成的二进制特征描述子便于高速匹配(计算汉明距离只需要通过异或操作加上统计二进制编码中"1"的个数,这些通过底层运算可以实现),且便于在硬件上实现。其次,该特征描述子的缺点很明显就是旋转不变形较差,需要通过新的方法来改进。
通过实验,作者进行结果比较:
- 在旋转程度较小的图像中,使用BRIEF特征描述子的匹配质量非常高,测试的大多数情况都超过了SURF,但是在旋转大于30°后,BRIEF特征描述子的匹配率快速降到0左右;
- BRIEF的耗时非常短,在相同情况下计算512个特征点的描述子是,SURF耗时335ms,BRIEF仅8.18ms;匹配SURF描述子需要28.3ms,BRIEF仅需要2.19ms,在要求不太高的情形下,BRIEF描述子更容易做到实时;
BRIEF的优点主要在于速度,缺点也很明显:
- 不具有旋转不变形;
- 对噪声敏感
- 不具有尺度不变性
因此为了解决前两个缺点,并且综合考虑速度和性能,提出了ORB算法,该算法将基于FAST关键点检测的技术和BRIEF特征描述子技术相结合。
二 点对的选择
设我们在特征点的邻域块大小为$S\times{S}$内选择$n_d$个点对$(p,q)$,Colonder的实验中测试了5种采样方法。
- 在图像块内平均采样;
- $p$和$q$都符合$(0,\frac{1}{25}S^2)$的 高斯分布;
- $p$符合$(0,\frac{1}{25}S^2)$的高斯分布,而$q$符合$(0,\frac{1}{100}S^2)$的高斯分布;
- 在空间量化极坐标下的离散位置随机采样;
- 把$p$固定为(0,0),$q$在周围平均采样;
下面是5种采样方法的结果示意图:


三 OpenCV实现
我们使用OpenCV演示一下特征点提取、BRIEF特征描述子提取、以及特征点匹配的过程:
# -*- coding: utf-8 -*-
"""
Created on Mon Sep 10 09:59:22 2018 @author: zy
""" '''
使用BRIEF特征描述符
'''
import cv2
import numpy as np def brief_test():
#加载图片 灰色
img1 = cv2.imread('./image/match1.jpg')
img1 = cv2.resize(img1,dsize=(600,400))
gray1 = cv2.cvtColor(img1,cv2.COLOR_BGR2GRAY)
img2 = cv2.imread('./image/match2.jpg')
img2 = cv2.resize(img2,dsize=(600,400))
gray2 = cv2.cvtColor(img2,cv2.COLOR_BGR2GRAY)
image1 = gray1.copy()
image2 = gray2.copy() image1 = cv2.medianBlur(image1,5)
image2 = cv2.medianBlur(image2,5) '''
1.使用SURF算法检测关键点
'''
#创建一个SURF对象 阈值越高,能识别的特征就越少,因此可以采用试探法来得到最优检测。
surf = cv2.xfeatures2d.SURF_create(3000)
keypoints1 = surf.detect(image1)
keypoints2 = surf.detect(image2)
#在图像上绘制关键点
image1 = cv2.drawKeypoints(image=image1,keypoints = keypoints1,outImage=image1,color=(255,0,255),flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
image2 = cv2.drawKeypoints(image=image2,keypoints = keypoints2,outImage=image2,color=(255,0,255),flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
#显示图像
cv2.imshow('sift_keypoints1',image1)
cv2.imshow('sift_keypoints2',image2)
cv2.waitKey(20) '''
2.计算特征描述符
'''
brief = cv2.xfeatures2d.BriefDescriptorExtractor_create(32)
keypoints1, descriptors1 = brief.compute(image1, keypoints1)
keypoints2, descriptors2 = brief.compute(image2, keypoints2) print('descriptors1:',len(descriptors1),'descriptors2',len(descriptors2)) '''
3.匹配 汉明距离匹配特征点
'''
matcher = cv2.BFMatcher_create(cv2.HAMMING_NORM_TYPE)
matchePoints = matcher.match(descriptors1,descriptors2)
print(type(matchePoints),len(matchePoints),matchePoints[0]) #提取强匹配特征点
minMatch = 1
maxMatch = 0
for i in range(len(matchePoints)):
if minMatch > matchePoints[i].distance:
minMatch = matchePoints[i].distance
if maxMatch < matchePoints[i].distance:
maxMatch = matchePoints[i].distance
print('最佳匹配值是:',minMatch)
print('最差匹配值是:',maxMatch) #获取排雷在前边的几个最优匹配结果
goodMatchePoints = []
for i in range(len(matchePoints)):
if matchePoints[i].distance < minMatch + (maxMatch-minMatch)/3:
goodMatchePoints.append(matchePoints[i]) #绘制最优匹配点
outImg = None
outImg = cv2.drawMatches(img1,keypoints1,img2,keypoints2,goodMatchePoints,outImg,matchColor=(0,255,0),flags=cv2.DRAW_MATCHES_FLAGS_DEFAULT)
cv2.imshow('matche',outImg)
cv2.waitKey(0)
cv2.destroyAllWindows() if __name__ == '__main__':
brief_test()

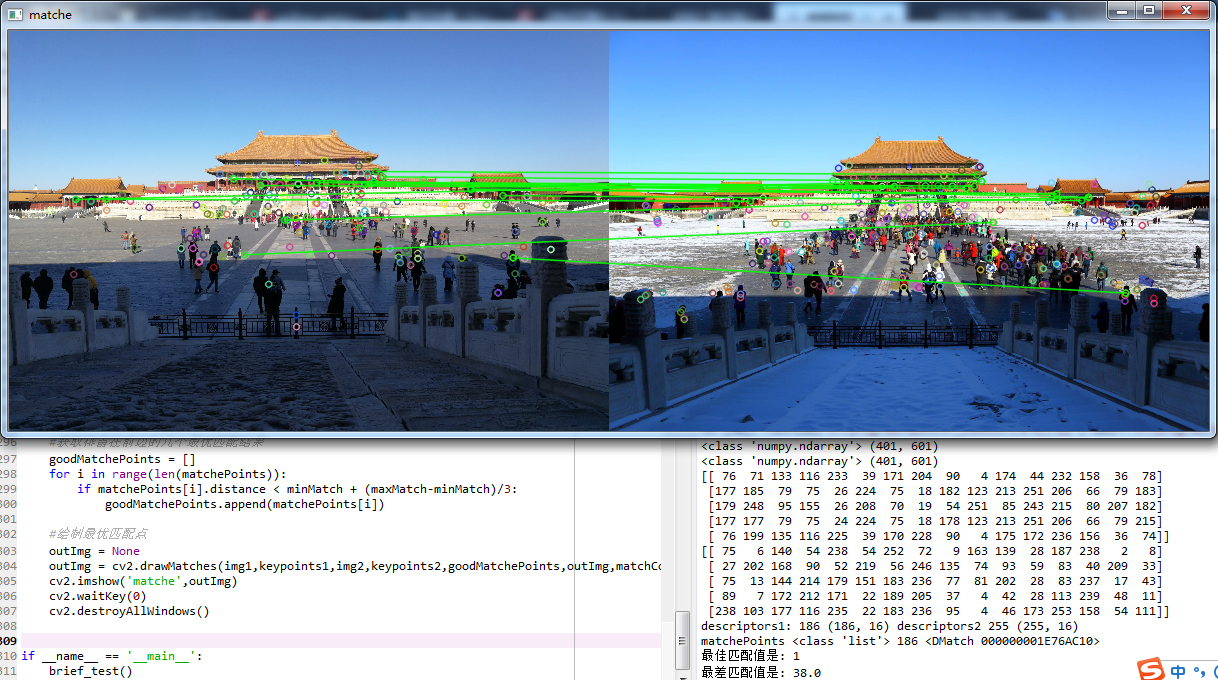
由于BRIEF描述子对噪声比较敏感,因此我们对图片进行了中值滤波处理,虽然消除了部分误匹配点,但是从上图中可以看到匹配的效果并不是很好。在实际应用上,我们应该选取两个近似一致并且噪声点较少的图像,这样才能取得较高的匹配质量。
四 自己实现
下面我们尝试自己去实现BRIEF描述符,代码如下(注意这个代码是仿照OpenCV的C++实现):
# -*- coding: utf-8 -*-
"""
Created on Mon Sep 10 15:38:39 2018 @author: zy
""" '''
自己实现一个BRIEF特征描述符
参考:Opencv2.4.9源码分析——BRIEF https://blog.csdn.net/zhaocj/article/details/44236863
'''
import cv2
import numpy as np
import functools class BriefDescriptorExtractor(object):
'''
BRIEF描述符实现
'''
def __init__(self,byte=16):
'''
args:
byte:描述子占用的字节数,这里只实现了16,32和64的没有实现
'''
#邻域范围
self.__patch_size = 48
#平均积分核大小
self.__kernel_size = 9
#占用字节数16,对应描述子长度16*8=128 128个点对
self.__bytes = byte def compute(self,image,keypoints):
'''
计算特征描述符 args:
image:输入图像
keypoints:图像的关键点集合
return:
特征点,特征描述符元组
'''
if len(image.shape) == 3:
gray_image = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
else:
gray_image = image.clone()
#计算积分图像
self.__image_sum = cv2.integral(gray_image,sdepth = cv2.CV_32S)
print(type(self.__image_sum),self.__image_sum.shape) #移除接近边界的关键点
keypoints_res = []
rows,cols = image.shape[:2]
for keypoint in keypoints:
point = keypoint.pt
if point[0] > (self.__patch_size + self.__kernel_size)/2 and point[0] < cols-(self.__patch_size + self.__kernel_size/2):
if point[1] > (self.__patch_size+self.__kernel_size)/2 and point[1] < rows - (self.__patch_size + self.__kernel_size )/2:
keypoints_res.append(keypoint) #计算特征点描述符
return keypoints_res,self.pixelTests16(keypoints_res) def pixelTests16(self,keypoints):
'''
创建BRIEF描述符 args:
keypoints:关键点
return:
descriptors:返回描述符
'''
descriptors = np.zeros((len(keypoints),self.__bytes),dtype=np.uint8)
for i in range(len(keypoints)):
#固定默认参数
SMOOTHED = functools.partial(self.smoothed_sum,keypoint=keypoints[i])
descriptors[i][0] = (((SMOOTHED(-2, -1) < SMOOTHED(7, -1)) << 7) +
((SMOOTHED(-14, -1) < SMOOTHED(-3, 3)) << 6) +
((SMOOTHED(1, -2) < SMOOTHED(11, 2)) << 5) +
((SMOOTHED(1, 6) < SMOOTHED(-10, -7)) << 4) +
((SMOOTHED(13, 2) < SMOOTHED(-1, 0)) << 3) +
((SMOOTHED(-14, 5) < SMOOTHED(5, -3)) << 2) +
((SMOOTHED(-2, 8) < SMOOTHED(2, 4)) << 1) +
((SMOOTHED(-11, 8) < SMOOTHED(-15, 5)) << 0))
descriptors[i][1] = (((SMOOTHED(-6, -23) < SMOOTHED(8, -9)) << 7) +
((SMOOTHED(-12, 6) < SMOOTHED(-10, 8)) << 6) +
((SMOOTHED(-3, -1) < SMOOTHED(8, 1)) << 5) +
((SMOOTHED(3, 6) < SMOOTHED(5, 6)) << 4) +
((SMOOTHED(-7, -6) < SMOOTHED(5, -5)) << 3) +
((SMOOTHED(22, -2) < SMOOTHED(-11, -8)) << 2) +
((SMOOTHED(14, 7) < SMOOTHED(8, 5)) << 1) +
((SMOOTHED(-1, 14) < SMOOTHED(-5, -14)) << 0))
descriptors[i][2] = (((SMOOTHED(-14, 9) < SMOOTHED(2, 0)) << 7) +
((SMOOTHED(7, -3) < SMOOTHED(22, 6)) << 6) +
((SMOOTHED(-6, 6) < SMOOTHED(-8, -5)) << 5) +
((SMOOTHED(-5, 9) < SMOOTHED(7, -1)) << 4) +
((SMOOTHED(-3, -7) < SMOOTHED(-10, -18)) << 3) +
((SMOOTHED(4, -5) < SMOOTHED(0, 11)) << 2) +
((SMOOTHED(2, 3) < SMOOTHED(9, 10)) << 1) +
((SMOOTHED(-10, 3) < SMOOTHED(4, 9)) << 0))
descriptors[i][3] = (((SMOOTHED(0, 12) < SMOOTHED(-3, 19)) << 7) +
((SMOOTHED(1, 15) < SMOOTHED(-11, -5)) << 6) +
((SMOOTHED(14, -1) < SMOOTHED(7, 8)) << 5) +
((SMOOTHED(7, -23) < SMOOTHED(-5, 5)) << 4) +
((SMOOTHED(0, -6) < SMOOTHED(-10, 17)) << 3) +
((SMOOTHED(13, -4) < SMOOTHED(-3, -4)) << 2) +
((SMOOTHED(-12, 1) < SMOOTHED(-12, 2)) << 1) +
((SMOOTHED(0, 8) < SMOOTHED(3, 22)) << 0))
descriptors[i][4] = (((SMOOTHED(-13, 13) < SMOOTHED(3, -1)) << 7) +
((SMOOTHED(-16, 17) < SMOOTHED(6, 10)) << 6) +
((SMOOTHED(7, 15) < SMOOTHED(-5, 0)) << 5) +
((SMOOTHED(2, -12) < SMOOTHED(19, -2)) << 4) +
((SMOOTHED(3, -6) < SMOOTHED(-4, -15)) << 3) +
((SMOOTHED(8, 3) < SMOOTHED(0, 14)) << 2) +
((SMOOTHED(4, -11) < SMOOTHED(5, 5)) << 1) +
((SMOOTHED(11, -7) < SMOOTHED(7, 1)) << 0))
descriptors[i][5] = (((SMOOTHED(6, 12) < SMOOTHED(21, 3)) << 7) +
((SMOOTHED(-3, 2) < SMOOTHED(14, 1)) << 6) +
((SMOOTHED(5, 1) < SMOOTHED(-5, 11)) << 5) +
((SMOOTHED(3, -17) < SMOOTHED(-6, 2)) << 4) +
((SMOOTHED(6, 8) < SMOOTHED(5, -10)) << 3) +
((SMOOTHED(-14, -2) < SMOOTHED(0, 4)) << 2) +
((SMOOTHED(5, -7) < SMOOTHED(-6, 5)) << 1) +
((SMOOTHED(10, 4) < SMOOTHED(4, -7)) << 0))
descriptors[i][6] = (((SMOOTHED(22, 0) < SMOOTHED(7, -18)) << 7) +
((SMOOTHED(-1, -3) < SMOOTHED(0, 18)) << 6) +
((SMOOTHED(-4, 22) < SMOOTHED(-5, 3)) << 5) +
((SMOOTHED(1, -7) < SMOOTHED(2, -3)) << 4) +
((SMOOTHED(19, -20) < SMOOTHED(17, -2)) << 3) +
((SMOOTHED(3, -10) < SMOOTHED(-8, 24)) << 2) +
((SMOOTHED(-5, -14) < SMOOTHED(7, 5)) << 1) +
((SMOOTHED(-2, 12) < SMOOTHED(-4, -15)) << 0))
descriptors[i][7] = (((SMOOTHED(4, 12) < SMOOTHED(0, -19)) << 7) +
((SMOOTHED(20, 13) < SMOOTHED(3, 5)) << 6) +
((SMOOTHED(-8, -12) < SMOOTHED(5, 0)) << 5) +
((SMOOTHED(-5, 6) < SMOOTHED(-7, -11)) << 4) +
((SMOOTHED(6, -11) < SMOOTHED(-3, -22)) << 3) +
((SMOOTHED(15, 4) < SMOOTHED(10, 1)) << 2) +
((SMOOTHED(-7, -4) < SMOOTHED(15, -6)) << 1) +
((SMOOTHED(5, 10) < SMOOTHED(0, 24)) << 0))
descriptors[i][8] = (((SMOOTHED(3, 6) < SMOOTHED(22, -2)) << 7) +
((SMOOTHED(-13, 14) < SMOOTHED(4, -4)) << 6) +
((SMOOTHED(-13, 8) < SMOOTHED(-18, -22)) << 5) +
((SMOOTHED(-1, -1) < SMOOTHED(-7, 3)) << 4) +
((SMOOTHED(-19, -12) < SMOOTHED(4, 3)) << 3) +
((SMOOTHED(8, 10) < SMOOTHED(13, -2)) << 2) +
((SMOOTHED(-6, -1) < SMOOTHED(-6, -5)) << 1) +
((SMOOTHED(2, -21) < SMOOTHED(-3, 2)) << 0))
descriptors[i][9] = (((SMOOTHED(4, -7) < SMOOTHED(0, 16)) << 7) +
((SMOOTHED(-6, -5) < SMOOTHED(-12, -1)) << 6) +
((SMOOTHED(1, -1) < SMOOTHED(9, 18)) << 5) +
((SMOOTHED(-7, 10) < SMOOTHED(-11, 6)) << 4) +
((SMOOTHED(4, 3) < SMOOTHED(19, -7)) << 3) +
((SMOOTHED(-18, 5) < SMOOTHED(-4, 5)) << 2) +
((SMOOTHED(4, 0) < SMOOTHED(-20, 4)) << 1) +
((SMOOTHED(7, -11) < SMOOTHED(18, 12)) << 0))
descriptors[i][10] = (((SMOOTHED(-20, 17) < SMOOTHED(-18, 7)) << 7) +
((SMOOTHED(2, 15) < SMOOTHED(19, -11)) << 6) +
((SMOOTHED(-18, 6) < SMOOTHED(-7, 3)) << 5) +
((SMOOTHED(-4, 1) < SMOOTHED(-14, 13)) << 4) +
((SMOOTHED(17, 3) < SMOOTHED(2, -8)) << 3) +
((SMOOTHED(-7, 2) < SMOOTHED(1, 6)) << 2) +
((SMOOTHED(17, -9) < SMOOTHED(-2, 8)) << 1) +
((SMOOTHED(-8, -6) < SMOOTHED(-1, 12)) << 0))
descriptors[i][11] = (((SMOOTHED(-2, 4) < SMOOTHED(-1, 6)) << 7) +
((SMOOTHED(-2, 7) < SMOOTHED(6, 8)) << 6) +
((SMOOTHED(-8, -1) < SMOOTHED(-7, -9)) << 5) +
((SMOOTHED(8, -9) < SMOOTHED(15, 0)) << 4) +
((SMOOTHED(0, 22) < SMOOTHED(-4, -15)) << 3) +
((SMOOTHED(-14, -1) < SMOOTHED(3, -2)) << 2) +
((SMOOTHED(-7, -4) < SMOOTHED(17, -7)) << 1) +
((SMOOTHED(-8, -2) < SMOOTHED(9, -4)) << 0))
descriptors[i][12] = (((SMOOTHED(5, -7) < SMOOTHED(7, 7)) << 7) +
((SMOOTHED(-5, 13) < SMOOTHED(-8, 11)) << 6) +
((SMOOTHED(11, -4) < SMOOTHED(0, 8)) << 5) +
((SMOOTHED(5, -11) < SMOOTHED(-9, -6)) << 4) +
((SMOOTHED(2, -6) < SMOOTHED(3, -20)) << 3) +
((SMOOTHED(-6, 2) < SMOOTHED(6, 10)) << 2) +
((SMOOTHED(-6, -6) < SMOOTHED(-15, 7)) << 1) +
((SMOOTHED(-6, -3) < SMOOTHED(2, 1)) << 0))
descriptors[i][13] = (((SMOOTHED(11, 0) < SMOOTHED(-3, 2)) << 7) +
((SMOOTHED(7, -12) < SMOOTHED(14, 5)) << 6) +
((SMOOTHED(0, -7) < SMOOTHED(-1, -1)) << 5) +
((SMOOTHED(-16, 0) < SMOOTHED(6, 8)) << 4) +
((SMOOTHED(22, 11) < SMOOTHED(0, -3)) << 3) +
((SMOOTHED(19, 0) < SMOOTHED(5, -17)) << 2) +
((SMOOTHED(-23, -14) < SMOOTHED(-13, -19)) << 1) +
((SMOOTHED(-8, 10) < SMOOTHED(-11, -2)) << 0))
descriptors[i][14] = (((SMOOTHED(-11, 6) < SMOOTHED(-10, 13)) << 7) +
((SMOOTHED(1, -7) < SMOOTHED(14, 0)) << 6) +
((SMOOTHED(-12, 1) < SMOOTHED(-5, -5)) << 5) +
((SMOOTHED(4, 7) < SMOOTHED(8, -1)) << 4) +
((SMOOTHED(-1, -5) < SMOOTHED(15, 2)) << 3) +
((SMOOTHED(-3, -1) < SMOOTHED(7, -10)) << 2) +
((SMOOTHED(3, -6) < SMOOTHED(10, -18)) << 1) +
((SMOOTHED(-7, -13) < SMOOTHED(-13, 10)) << 0))
descriptors[i][15] = (((SMOOTHED(1, -1) < SMOOTHED(13, -10)) << 7) +
((SMOOTHED(-19, 14) < SMOOTHED(8, -14)) << 6) +
((SMOOTHED(-4, -13) < SMOOTHED(7, 1)) << 5) +
((SMOOTHED(1, -2) < SMOOTHED(12, -7)) << 4) +
((SMOOTHED(3, -5) < SMOOTHED(1, -5)) << 3) +
((SMOOTHED(-2, -2) < SMOOTHED(8, -10)) << 2) +
((SMOOTHED(2, 14) < SMOOTHED(8, 7)) << 1) +
((SMOOTHED(3, 9) < SMOOTHED(8, 2)) << 0))
return descriptors def smoothed_sum(self,y,x,keypoint):
'''
这里我们采用随机点平滑,不采用论文中的高斯平滑,而是采用随机点邻域内积分和代替,同样可以降低噪声的影响
args:
self.__image_sum:图像积分图 属性
keypoint:其中一个关键点
y,x:x和y表示点对中某一个像素相对于特征点的坐标
return:
函数返回滤波的结果
'''
half_kernel = self.__kernel_size // 2 #计算点对中某一个像素的绝对坐标
img_y = int(keypoint.pt[1] + 0.5) + y
img_x = int(keypoint.pt[0] + 0.5) + x #计算以该像素为中心,以KERNEL_SIZE为边长的正方形内所有像素灰度值之和,本质上是均值滤波
ret = self.__image_sum[img_y + half_kernel+1][img_x + half_kernel+1] \
-self.__image_sum[img_y + half_kernel+1][img_x - half_kernel] \
-self.__image_sum[img_y - half_kernel][img_x + half_kernel+1] \
+self.__image_sum[img_y - half_kernel][img_x - half_kernel]
return ret def brief_test():
#加载图片 灰色
img1 = cv2.imread('./image/match1.jpg')
img1 = cv2.resize(img1,dsize=(600,400))
gray1 = cv2.cvtColor(img1,cv2.COLOR_BGR2GRAY)
img2 = cv2.imread('./image/match2.jpg')
img2 = cv2.resize(img2,dsize=(600,400))
gray2 = cv2.cvtColor(img2,cv2.COLOR_BGR2GRAY)
image1 = gray1.copy()
image2 = gray2.copy() image1 = cv2.medianBlur(image1,5)
image2 = cv2.medianBlur(image2,5) '''
1.使用SURF算法检测关键点
'''
#创建一个SURF对象 阈值越高,能识别的特征就越少,因此可以采用试探法来得到最优检测。
surf = cv2.xfeatures2d.SURF_create(3000)
keypoints1 = surf.detect(image1)
keypoints2 = surf.detect(image2)
#print(keypoints1[0].pt) #(x,y)
#在图像上绘制关键点
image1 = cv2.drawKeypoints(image=image1,keypoints = keypoints1,outImage=image1,color=(255,0,255),flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
image2 = cv2.drawKeypoints(image=image2,keypoints = keypoints2,outImage=image2,color=(255,0,255),flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
#显示图像
#cv2.imshow('surf_keypoints1',image1)
#cv2.imshow('surf_keypoints2',image2)
#cv2.waitKey(20) '''
2.计算特征描述符
'''
brief = BriefDescriptorExtractor(16)
keypoints1,descriptors1 = brief.compute(image1, keypoints1)
keypoints2,descriptors2 = brief.compute(image2, keypoints2)
print(descriptors1[:5])
print(descriptors2[:5]) print('descriptors1:',len(descriptors1),descriptors1.shape,'descriptors2',len(descriptors2),descriptors2.shape) '''
3.匹配 汉明距离匹配特征点
'''
matcher = cv2.BFMatcher_create(cv2.HAMMING_NORM_TYPE)
matchePoints = matcher.match(descriptors1,descriptors2)
print('matchePoints',type(matchePoints),len(matchePoints),matchePoints[0]) #提取强匹配特征点
minMatch = 1
maxMatch = 0
for i in range(len(matchePoints)):
if minMatch > matchePoints[i].distance:
minMatch = matchePoints[i].distance
if maxMatch < matchePoints[i].distance:
maxMatch = matchePoints[i].distance
print('最佳匹配值是:',minMatch)
print('最差匹配值是:',maxMatch) #获取排雷在前边的几个最优匹配结果
goodMatchePoints = []
for i in range(len(matchePoints)):
if matchePoints[i].distance < minMatch + (maxMatch-minMatch)/3:
goodMatchePoints.append(matchePoints[i]) #绘制最优匹配点
outImg = None
outImg = cv2.drawMatches(img1,keypoints1,img2,keypoints2,goodMatchePoints,outImg,matchColor=(0,255,0),flags=cv2.DRAW_MATCHES_FLAGS_DEFAULT)
cv2.imshow('matche',outImg)
cv2.waitKey(0)
cv2.destroyAllWindows() if __name__ == '__main__':
brief_test()
参考文章:
[1]BRIEF特征简介
[2]Binary Robust Independent Elementary Features
[3]【特征匹配】BRIEF特征描述子原理及源码解析
[4]图像特征描述子之BRIEF
[5]Calonder M, Lepetit V, Strecha C, et al. BRIEF: binary robust independent elementary features[C]// European Conference on Computer Vision. 2010:778-792.
[6]【特征匹配】BRIEF特征描述子原理及源码解析
第十六节、特征描述符BRIEF(附源码)的更多相关文章
- 第三十六节,目标检测之yolo源码解析
在一个月前,我就已经介绍了yolo目标检测的原理,后来也把tensorflow实现代码仔细看了一遍.但是由于这个暑假事情比较大,就一直搁浅了下来,趁今天有时间,就把源码解析一下.关于yolo目标检测的 ...
- 并发编程(十六)——java7 深入并发包 ConcurrentHashMap 源码解析
以前写过介绍HashMap的文章,文中提到过HashMap在put的时候,插入的元素超过了容量(由负载因子决定)的范围就会触发扩容操作,就是rehash,这个会重新将原数组的内容重新hash到新的扩容 ...
- ElasticStack系列之十六 & ElasticSearch5.x index/create 和 update 源码分析
开篇 在ElasticSearch 系列十四中提到的问题即 ElasticStack系列之十四 & ElasticSearch5.x bulk update 中重复 id 性能骤降,继续这个问 ...
- arcgis api 3.x for js 入门开发系列十四最近设施点路径分析(附源码下载)
前言 关于本篇功能实现用到的 api 涉及类看不懂的,请参照 esri 官网的 arcgis api 3.x for js:esri 官网 api,里面详细的介绍 arcgis api 3.x 各个类 ...
- arcgis api 3.x for js 入门开发系列六地图分屏对比(附源码下载)
前言 关于本篇功能实现用到的 api 涉及类看不懂的,请参照 esri 官网的 arcgis api 3.x for js:esri 官网 api,里面详细的介绍 arcgis api 3.x 各个类 ...
- Android 音视频深入 十五 FFmpeg 推流mp4文件(附源码下载)
源码地址https://github.com/979451341/Rtmp 1.配置RTMP服务器 这个我不多说贴两个博客分别是在mac和windows环境上的,大家跟着弄 MAC搭建RTMP服务器h ...
- Android 音视频深入 十二 FFmpeg视频替换声音(附源码下载)
项目地址,求starhttps://github.com/979451341/AudioVideoStudyCodeTwo/tree/master/FFmpeg%E7%BB%99%E8%A7%86%E ...
- Android 音视频深入 六 使用FFmpeg播放视频(附源码下载)
本篇项目地址,求starhttps://github.com/979451341/Audio-and-video-learning-materials/tree/master/FFmpeg%E6%92 ...
- 第十六节、基于ORB的特征检测和特征匹配
之前我们已经介绍了SIFT算法,以及SURF算法,但是由于计算速度较慢的原因.人们提出了使用ORB来替代SIFT和SURF.与前两者相比,ORB有更快的速度.ORB在2011年才首次发布.在前面小节中 ...
随机推荐
- 《笔记》Apache2 mod_wsgi的配置
接手了一台古老的服务器的还使用的是mod_wsgi,所以需要配置一下.其实这里有点怀念,记得当年自己折腾第一个app的时候,还是个什么都不懂的菜鸡.当时用django搜方案的时候,还不知道有uwsgi ...
- Selenium简单回顾
一.Selenium介绍 1.Selenium(浏览器自动化测试框架): Selenium 是一个用于Web应用程序测试的工具.Selenium测试直接运行在浏览器中,就像真正的用户在操作一样.支持的 ...
- DNS_PROBE_FINISHED_NXDOMAIN & MacOS
DNS_PROBE_FINISHED_NXDOMAIN 内网 DNS bug 8.8.8.8 8.8.4.4 # new inner Wi-Fi 10.1.3.10 10.1.3.13 Windows ...
- Docker最全教程——从理论到实战
Docker最全教程——从理论到实战(一) Docker最全教程——从理论到实战(二) Docker最全教程——从理论到实战(三) Docker最全教程——从理论到实战(四) Docker最全教程—— ...
- How to create ISO on macOS
hdiutil makehybrid -iso -joliet -o test1.iso /users/test/test1
- CSS遮罩效果和毛玻璃效果
前面的话 本文将详细介绍CSS遮罩效果和毛玻璃效果 遮罩效果 普通遮罩 一般地,处理全屏遮罩的方法是使用额外标签 <style>.overlay{ position:fixed; top: ...
- mysql 自带的性能压力测试工具
mysqlslap -h127.0.0.1 -uroot -p --concurrency=100 --iterations=1 --auto-generate-sql --auto-generate ...
- [Codeforces266E]More Queries to Array...——线段树
题目链接: Codeforces266E 题目大意:给出一个序列$a$,要求完成$Q$次操作,操作分为两种:1.$l,r,x$,将$[l,r]$的数都变为$x$.2.$l,r,k$,求$\sum\li ...
- PHP——emjoin表情存入数据库
前言 还有一种解决的方法是更改数据库,这里就不写了,这里直接对emoji进行转码 代码 mb_strlen() | strlen() | rawurlencode() | rawurldecode() ...
- Cetos 7 系统安装备注事项
说明:此篇内容为个人记录备注事项,具体的安装操作请参考其他教程: 系统安装: 公司的服务器型号为戴尔R330 卡片式服务器,安装过程中遇到一些问题,此文章中简单记录下 1.下载一份Cetos 系统镜像 ...