ElasticStack系列之十六 & ElasticSearch5.x index/create 和 update 源码分析
开篇
在ElasticSearch 系列十四中提到的问题即 ElasticStack系列之十四 & ElasticSearch5.x bulk update 中重复 id 性能骤降,继续这个问题再继续查看更加多的源代码,看看底层在执行 index、create 和 update 操作到底有什么不同,有什么可以使得我们使用性能更加好的。
准备
使用 Intellij IDEA 来阅读 ElasticSearch 源码,操作相对来说比较简单。具体操作步骤如下:
1. 下载 ElasticSearch 源码
git clone https://github.com/elastic/elasticsearch.git
2. 下载安装 gradle,确保版本在 3.3 及以上,我电脑是 macOS,自动下载最新版本为:4.2.1
brew update && brew install gradle
在 mac 上按照上面的命令执行完毕之后它会自动安装到 /usr/local/bin/gradle , 源文件目录我到现在都没有找到,最后一怒之下直接下载对应最新版本的 zip 包,放到指定目录自己执行安装
首先,先download最新版本的gradle,网址:http://www.gradle.org/get-started
然后将下载下来的zip包放在你要安装的路径上,我安装在 /usr/myname/
然后打开电脑上的.bash_profile文件,输入以下命令:
export GRADLE_HOME=/Users/myname/gradle-4.2.
export PATH=$PATH:$GRADLE_HOME/bin
然后执行命令:source ~/.bash_profile 使刚才配置生效。
3. 进入到 ElasticSearch 源码目录,在该目录下执行以下命令准备导入 IntelliJ IDEA 需要的文件
gradle idea
以上命令执行完毕之后,打开 IntelliJ IDEA 工具它会自己进行编译,需要你配置对应的 gradle home 目录,即上面指定的 /Usrs/myname/gradle-4.2.1 ,配置完毕之后项目就算导入成功了。
注意:
1. 运行这个命令需要下载很多东西,有时候可能因为某一个包卡住,不要紧张,退出重新运行该命令,多尝试几次就好了。
2. 各个版本代码上有一定的差别,但是核心代码整体是不会有大改动的,我查看的源码版本为当前最新版本:5.6.3
Index/Create 源码分析
es index 和 create 最终都会调用 org/elasticsearch/index/engine/InternalEngine.java 中下面的方法:
public IndexResult index(Index index) throws IOException
注意这里的 index 中包含有要写入的 doc, 简单画下该方法的执行流程图,代码这里就不贴了
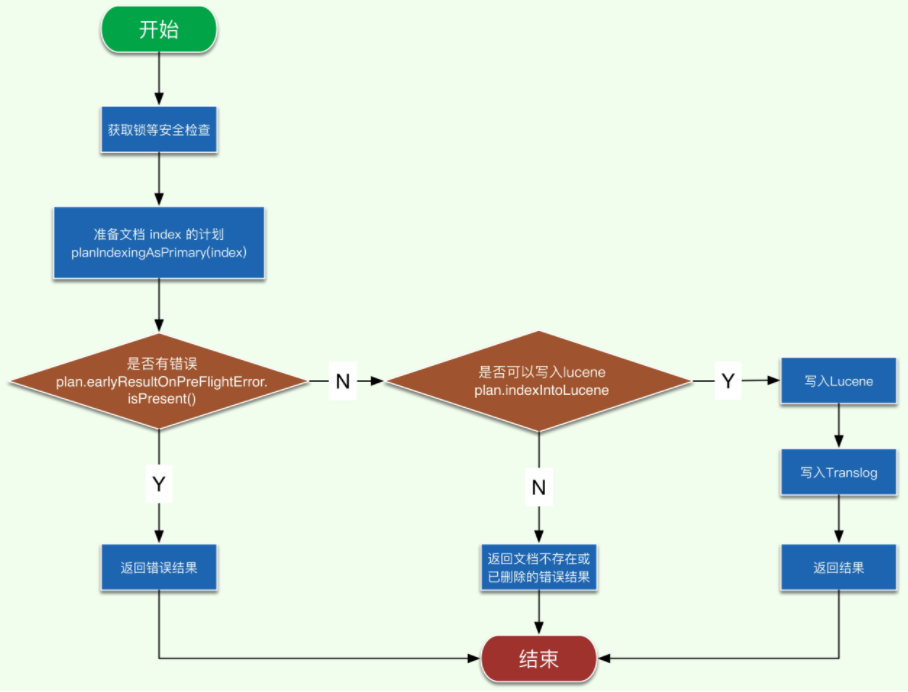
请结合上面的流程图来看相应的代码,整个逻辑应该还是很清晰的,接下来我们看 planIndexingAsPrimary 的逻辑。
private IndexingStrategy planIndexingAsPrimary(Index index) throws IOException
这个方法最终返回一个 IndexingStrategy,即一个索引的策略,总共有如下几个策略:
- optimizedAppendOnly
- skipDueToVersionConflict
- processNormally
- overrideExistingAsIfNotThere
- skipAsStale
不同的策略对应了不同的处理逻辑,前面3个是常用的,我们来看下流程图。
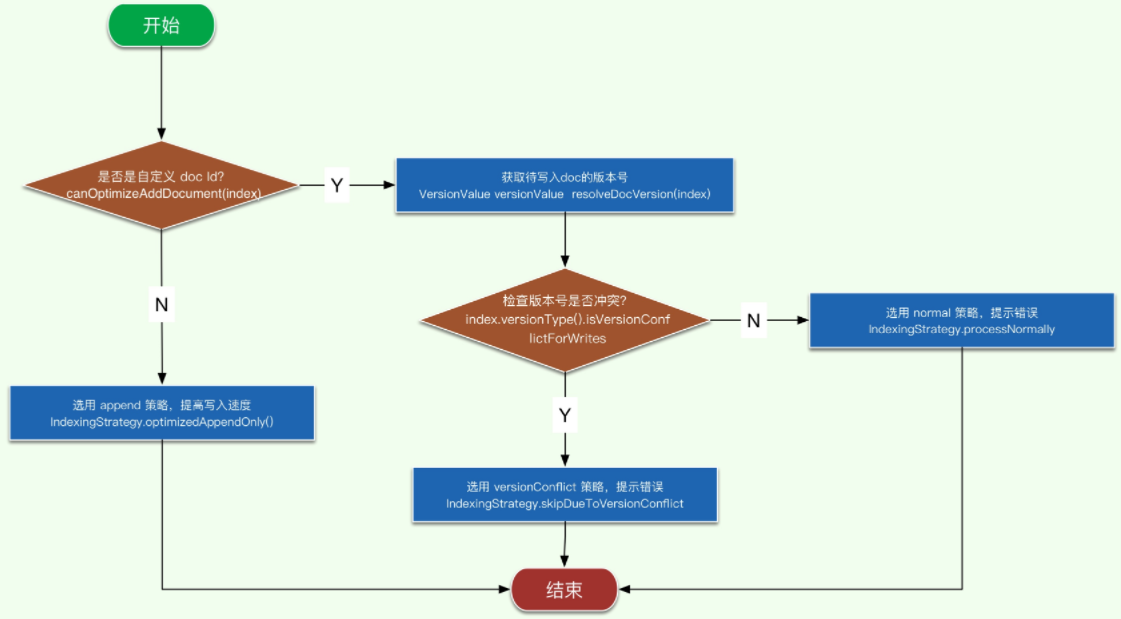
这里的第一步判断:是否是自定义 doc id? 这一步就是 es 对于日志类非自定义 doc id 的优化,感兴趣的可以自己去看下代码,简单讲就是在非自定义 id 的情况下,直接将文档 add ,否则需要 update,而 update 比 add 成本高很多。
而第二个判断:检查版本号是否冲突? 涉及到是如何根据 文档版本号(doc version) 来确认文档可写入,代码都在 index.versionType().isVersionConflictForWrites 方法里,逻辑也比较简单,不展开讲了,感兴趣的自己去看吧。
上面的流程图也比较清晰地列出了策略选择的逻辑,除去 optimizedAppendOnly 策略,其他都需要根据待写入文档的版本号来做出决策。接下来我们就看下获取文档版本号的方法。
private VersionValue resolveDocVersion(final Operation op) throws IOException
该方法逻辑比较简单,主要分为2步:
- 尝试从 versionMap 中读取待写入文档的 version,也即从内存中读取。versionMap 会暂存还没有 commit 到磁盘的文档版本信息。
- 如果第 1 步中没有读到,则从 index 中读取,也即从文件中读取。
看到这里,开篇问题便有了答案。es 在 index 或者 create 的时候并不会 get 整个文档,而是只会获取文档的版本号做对比,而这个开销不会很大。
Update 源码分析
es update 的核心代码在 org/elasticsearch/action/update/UpdateHelper.java 中,具体方法如下:
public Result prepare(UpdateRequest request, IndexShard indexShard, LongSupplier nowInMillis) {
final GetResult getResult = indexShard.getService().get(request.type(), request.id(),
new String[]{RoutingFieldMapper.NAME, ParentFieldMapper.NAME},
true, request.version(), request.versionType(), FetchSourceContext.FETCH_SOURCE);
return prepare(indexShard.shardId(), request, getResult, nowInMillis);
}
代码逻辑很清晰,分两步走:
- 获取待更新文档的数据
- 执行更新文档的操作
第 1 步最终会调用 InternalEngine 中的 get 方法,如下:
public GetResult get(Get get, Function<String, Searcher> searcherFactory, LongConsumer onRefresh) throws EngineExceptio
update 操作需要先获取原始文档的原因也很简单,因为这里是允许用户做部分更新的,而 es 底层每次更新时要求必须是完整的文档(因为 lucene 的更新实际是删除老文档,新增新文档),如果不拿到原始数据的话,就不能组装出更新后的完整文档了。
因此,比较看重效率的业务,最好还是不要用 update 这种操作,直接用上面的 index 会更好一些。
总结
本文通过源码分析的方式解决了开篇提到的问题,答案简单总结在下面。
es 在 index 和 create 操作的时候,如果没有自定义 doc id,那么会使用 append 优化模式,否则会获取待写入文档的版本号(doc version),进行版本检查后再决定是否写入 lucene。所以这里不会去做一个 get 操作,即获取完整的文档信息。
ElasticStack系列之十六 & ElasticSearch5.x index/create 和 update 源码分析的更多相关文章
- ElasticStack系列之十四 & ElasticSearch5.x bulk update 中重复 id 性能骤降
目前在绝对多数公司在使用 ElasticSearch 将其当做数据库使用,将多个数据库中的数据同步到 ElasticSearch 索引是非常常见的应用场景.那么自然而然就会涉及到数据频繁的新增和更新, ...
- 第三十六节,目标检测之yolo源码解析
在一个月前,我就已经介绍了yolo目标检测的原理,后来也把tensorflow实现代码仔细看了一遍.但是由于这个暑假事情比较大,就一直搁浅了下来,趁今天有时间,就把源码解析一下.关于yolo目标检测的 ...
- 并发编程(十六)——java7 深入并发包 ConcurrentHashMap 源码解析
以前写过介绍HashMap的文章,文中提到过HashMap在put的时候,插入的元素超过了容量(由负载因子决定)的范围就会触发扩容操作,就是rehash,这个会重新将原数组的内容重新hash到新的扩容 ...
- ElasticStack系列之十九 & bulk时 index 和 create 的区别
区别: 两篇文章 id 都一样的情况下,index 是将第二篇文章覆盖第一篇:create 是在第二篇插入的时候抛出一个已经存在的异常 解释: 在批量请求的时候最好使用 create 方式进行导入.假 ...
- ElasticStack系列之十八 & ElasticSearch5.x XPack 过期新 License 更新
摘要 当你某一天打开 Kibana 对应的 Monitoring 选项卡的时候,发现提示需要下载新的 license,旧的 license 已经过期了,试用期为30天,如果不是很需要其他的复杂监控.报 ...
- (转)spring boot实战(第六篇)加载application资源文件源码分析
原文:http://blog.csdn.net/liaokailin/article/details/48878447
- 设计模式(二十四)——职责链模式(SpringMVC源码分析)
1 学校 OA 系统的采购审批项目:需求是 采购员采购教学器材 1) 如果金额 小于等于 5000, 由教学主任审批 (0<=x<=5000) 2) 如果金额 小于等于 10000, ...
- jQuery-1.9.1源码分析系列完毕目录整理
jQuery 1.9.1源码分析已经完毕.目录如下 jQuery-1.9.1源码分析系列(一)整体架构 jQuery-1.9.1源码分析系列(一)整体架构续 jQuery-1.9.1源码分析系列(二) ...
- jQuery源码分析系列
声明:本文为原创文章,如需转载,请注明来源并保留原文链接Aaron,谢谢! 版本截止到2013.8.24 jQuery官方发布最新的的2.0.3为准 附上每一章的源码注释分析 :https://git ...
随机推荐
- Scrum Meeting 11.08
成员 今日任务 明日计划 用时 徐越 赵庶宏 薄霖 卞忠昊 WebView和JavaScript交互基础 Bitmap(位图)全解析 Part1 3h 武鑫 设计 ...
- 20145214《网络攻防》逆向及Bof基础实践
20145214<网络攻防>逆向及Bof基础实践 实践说明 本次实践的对象是一个名为pwn1的linux可执行文件. 该程序正常执行流程是:main调用foo函数,foo函数会简单回显任何 ...
- Task 7 买书最低价格问题
任务: 书店针对<哈利波特>系列书籍进行促销活动,一共5卷,用编号0.1.2.3.4表示,单独一卷售价8元, 具体折扣如下所示: 本数 折扣 2 5% 3 ...
- C# CHM帮助文档
1.生成chm文件 首先,下载EasyCHM软件,此软件可将HTML文件.TXT文件.图片和文件夹按照文件层次生成.chm文件.EasyCHM打开界面如图所示: 点击“新建”,选择需要生成.chm文件 ...
- java拓荒者
因为是初学者 最近在看那个<java从入门到精通 韩顺平>的视频 觉得好不错 虽然视频的分辨率强差人意 但仍可接受 学知识嘛 用我们广东话说 :“鬼叫你穷,顶硬上” 韩老师的声音较好 课堂 ...
- “吃神么,买神么”的第二个Sprint计划
“吃神么,买神么”的第二个Sprint计划 一.现状 前台布局设计完成一个主页,可以让浏览者了解我们网站的功能,这是第一个阶段的Spring完成的事情.由于没有实际的功能体现,所以第二阶段开始 ...
- week3a:个人博客作业
1.博客上的问题 阅读下面程序,请回答如下问题: using System; using System.Collections.Generic; using System.Text; namespac ...
- Effective Modern C++翻译(5)-条款4:了解如何观察推导出的类型
条款4:了解如何观察推导出的类型 那些想要知道编译器推导出的类型的人通常分为两种,第一种是实用主义者,他们的动力通常来自于软件产生的问题(例如他们还在调试解决中),他们利用编译器进行寻找,并相信这个能 ...
- node path模块
一.在nodejs中path模块时使用频率很高的模块,其中不乏有很多API写得很模糊,但仔细琢磨下来,也不是很难理解. 1.获取文件所在路径 var path = require('path'); v ...
- Java如何查看死锁?
转载自 https://blog.csdn.net/u014039577/article/details/52351626 Java中当我们的开发涉及到多线程的时候,这个时候就很容易遇到死锁问题,刚开 ...