[机器学习]回归--Decision Tree Regression
CART决策树又称分类回归树,当数据集的因变量为连续性数值时,该树算法就是一个回归树,可以用叶节点观察的均值作为预测值;当数据集的因变量为离散型数值时,该树算法就是一个分类树,可以很好的解决分类问题。但需要注意的是,该算法是一个二叉树,即每一个非叶节点只能引伸出两个分支,所以当某个非叶节点是多水平(2个以上)的离散变量时,该变量就有可能被多次使用。
在sklearn中我们可以用来提高决策树泛化能力的超参数主要有
- max_depth:树的最大深度,也就是说当树的深度到达max_depth的时候无论还有多少可以分支的特征,决策树都会停止运算.
- min_samples_split: 分裂所需的最小数量的节点数.当叶节点的样本数量小于该参数后,则不再生成分支.该分支的标签分类以该分支下标签最多的类别为准
- min_samples_leaf; 一个分支所需要的最少样本数,如果在分支之后,某一个新增叶节点的特征样本数小于该超参数,则退回,不再进行剪枝.退回后的叶节点的标签以该叶节点中最多的标签你为准
- min_weight_fraction_leaf: 最小的权重系数
- max_leaf_nodes:最大叶节点数,None时无限制,取整数时,忽略max_depth


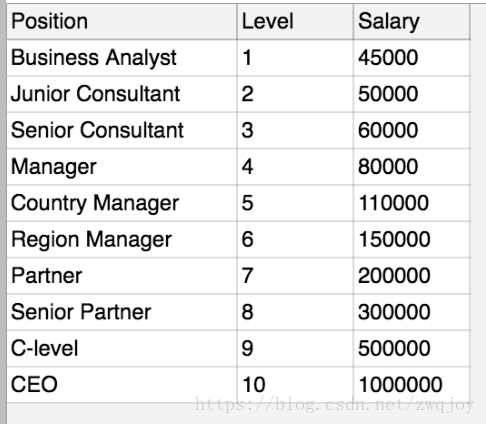
我们这次用的数据是公司内部不同的promotion level所对应的薪资
下面我们来看一下在Python中是如何实现的
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
dataset = pd.read_csv('Position_Salaries.csv')
X = dataset.iloc[:, 1:2].values
# 这里注意:1:2其实只有第一列,与1 的区别是这表示的是一个matrix矩阵,而非单一向量。
y = dataset.iloc[:, 2].values下来,进入正题,开始Decision Tree Regression回归:
from sklearn.tree import DecisionTreeRegressor
regressor = DecisionTreeRegressor(random_state = 0)
regressor.fit(X, y)
y_pred = regressor.predict(6.5)
# 图像中显示
X_grid = np.arange(min(X), max(X), 0.01)
X_grid = X_grid.reshape((len(X_grid), 1))
plt.scatter(X, y, color = 'red')
plt.plot(X_grid, regressor.predict(X_grid), color = 'blue')
plt.title('Truth or Bluff (Decision Tree Regression)')
plt.xlabel('Position level')
plt.ylabel('Salary')
plt.show()
下面的代码主要是对决策树最大深度与过拟合之间关系的探讨,可以看出对于最大深度对拟合关系影响.
与分类决策树一样的地方在于,最大深度的增加虽然可以增加对训练集拟合能力的增强,但这也就可能意味着其泛化能力的下降
import numpy as np
from sklearn.tree import DecisionTreeRegressor
import matplotlib.pyplot as plt
# Create a random dataset
rng = np.random.RandomState(1)
X = np.sort(10 * rng.rand(160, 1), axis=0)
y = np.sin(X).ravel()
y[::5] += 2 * (0.5 - rng.rand(32)) # 每五个点增加一次噪音
# Fit regression model
regr_1 = DecisionTreeRegressor(max_depth=2)
regr_2 = DecisionTreeRegressor(max_depth=4)
regr_3 = DecisionTreeRegressor(max_depth=8)
regr_1.fit(X, y)
regr_2.fit(X, y)
regr_3.fit(X, y)
# Predict
X_test = np.arange(0.0, 10.0, 0.01)[:, np.newaxis]
y_1 = regr_1.predict(X_test)
y_2 = regr_2.predict(X_test)
y_3 = regr_3.predict(X_test)
# Plot the results
plt.figure()
plt.scatter(X, y, s=20, edgecolor="black",
c="darkorange", label="data")
plt.plot(X_test, y_1, color="cornflowerblue",
label="max_depth=2", linewidth=2)
plt.plot(X_test, y_2, color="yellowgreen", label="max_depth=4", linewidth=2)
plt.plot(X_test, y_3, color="r", label="max_depth=8", linewidth=2)
plt.xlabel("data")
plt.ylabel("target")
plt.title("Decision Tree Regression")
plt.legend()
plt.show()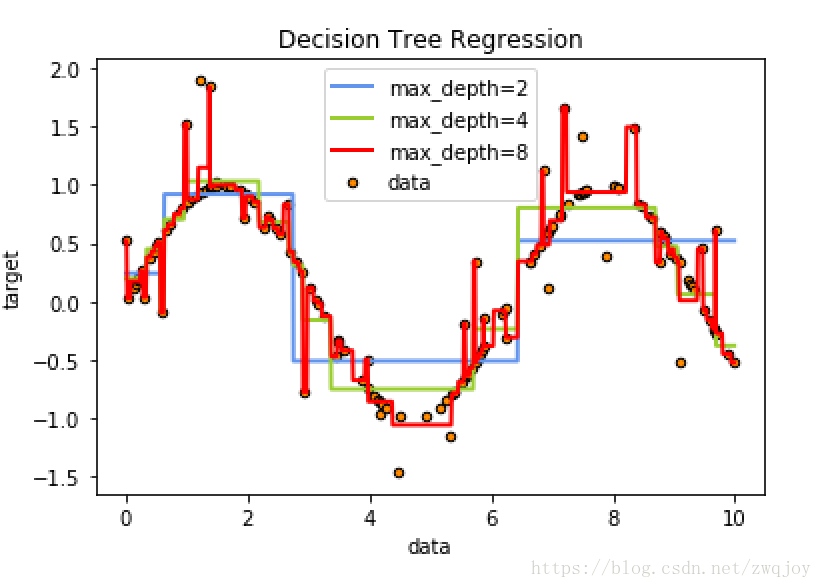
从上面的测试可以看出随着决策树最大深度的增加,决策树的拟合能力不断上升.
在这个例子中一共有160个样本,当最大深度为8(大于lg(200))时,我们的决策树已经不仅仅拟合了我们的正确样本,同时也拟合了我们添加的噪音,这导致了其泛化能力的下降.
最大深度与训练误差测试误差的关系
下面我们进行对于不同的最大深度决策树的训练误差与测试误差进行绘制.
当然你也可以通过改变其他可以控制决策树生成的超参数进行相关测试.
from sklearn import model_selection
def creat_data(n):
np.random.seed(0)
X = 5 * np.random.rand(n, 1)
y = np.sin(X).ravel()
noise_num=(int)(n/5)
y[::5] += 3 * (0.5 - np.random.rand(noise_num)) # 每第5个样本,就在该样本的值上添加噪音
return model_selection.train_test_split(X, y,test_size=0.25,random_state=1)
def test_DecisionTreeRegressor_depth(*data,maxdepth):
X_train,X_test,y_train,y_test=data
depths=np.arange(1,maxdepth)
training_scores=[]
testing_scores=[]
for depth in depths:
regr = DecisionTreeRegressor(max_depth=depth)
regr.fit(X_train, y_train)
training_scores.append(regr.score(X_train,y_train))
testing_scores.append(regr.score(X_test,y_test))
## 绘图
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
ax.plot(depths,training_scores,label="traing score")
ax.plot(depths,testing_scores,label="testing score")
ax.set_xlabel("maxdepth")
ax.set_ylabel("score")
ax.set_title("Decision Tree Regression")
ax.legend(framealpha=0.5)
plt.show()
X_train,X_test,y_train,y_test=creat_data(200)
test_DecisionTreeRegressor_depth(X_train,X_test,y_train,y_test,maxdepth=12)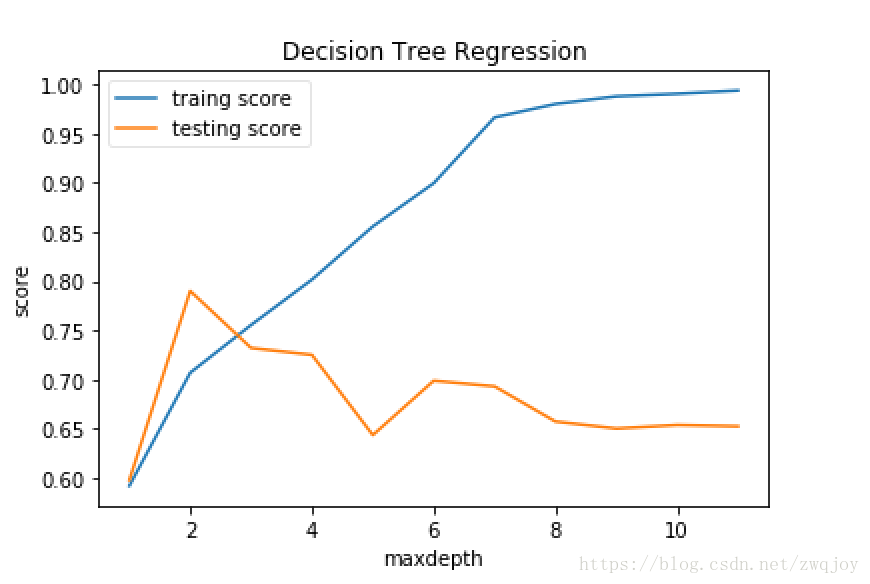
由上图我们可以看出,当我们使用train_test进行数据集的分割的时候,最大深度2即为我们需要的最佳超参数.
同样的你也可以对其他超参数进行测试,或者换用cv进行测试,再或者使用hyperopt or auto-sklearn等神器
[机器学习]回归--Decision Tree Regression的更多相关文章
- 机器学习-决策树 Decision Tree
咱们正式进入了机器学习的模型的部分,虽然现在最火的的机器学习方面的库是Tensorflow, 但是这里还是先简单介绍一下另一个数据处理方面很火的库叫做sklearn.其实咱们在前面已经介绍了一点点sk ...
- [机器学习]回归--Support Vector Regression(SVR)
来计算其损失. 而支持向量回归则认为只要f(x)与y偏离程度不要太大,既可以认为预测正确,不用计算损失,具体的,就是设置阈值α,只计算|f(x)−y|>α的数据点的loss,如下图所示,阴影部分 ...
- 【机器学习实战】第9章 树回归(Tree Regression)
第9章 树回归 <script type="text/javascript" src="http://cdn.mathjax.org/mathjax/latest/ ...
- 回归树(Regression Tree)
目录 回归树 理论解释 算法流程 ID3 和 C4.5 能不能用来回归? 回归树示例 References 说到决策树(Decision tree),我们很自然会想到用其做分类,每个叶子代表有限类别中 ...
- Decision tree(决策树)算法初探
0. 算法概述 决策树(decision tree)是一种基本的分类与回归方法.决策树模型呈树形结构(二分类思想的算法模型往往都是树形结构) 0x1:决策树模型的不同角度理解 在分类问题中,表示基于特 ...
- 吴裕雄 python 机器学习——回归决策树模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_s ...
- CART分类与回归树与GBDT(Gradient Boost Decision Tree)
一.CART分类与回归树 资料转载: http://dataunion.org/5771.html Classification And Regression Tree(CART)是决策 ...
- 机器学习算法实践:决策树 (Decision Tree)(转载)
前言 最近打算系统学习下机器学习的基础算法,避免眼高手低,决定把常用的机器学习基础算法都实现一遍以便加深印象.本文为这系列博客的第一篇,关于决策树(Decision Tree)的算法实现,文中我将对决 ...
- 机器学习/逻辑回归(logistic regression)/--附python代码
个人分类: 机器学习 本文为吴恩达<机器学习>课程的读书笔记,并用python实现. 前一篇讲了线性回归,这一篇讲逻辑回归,有了上一篇的基础,这一篇的内容会显得比较简单. 逻辑回归(log ...
随机推荐
- cropper.js 裁剪图片
https://blog.csdn.net/weixin_38023551/article/details/78792400
- vuex创建store并用computed获取数据
vuex中的store是一个状态管理器,用于分发数据.相当于父组件数据传递给子组件. 1.安装vuex npm i vuex --save 2.在src目录中创建store文件夹,里面创建store. ...
- Qt打包发布exe
1.首先以 release 方式编译源代码,然后将生成的a. exe 程序放到一个单独的文件夹中. 2.再从开始菜单打开 Qt 命令行工具. 3.在命令行中,进入到第一步中a. exe 程序所在的文件 ...
- 环境搭建文档——Windows下的Python3环境搭建
前言 背景介绍: 自己用Python开发了一些安卓性能自动化测试的脚本, 但是想要运行这些脚本的话, 本地需要Python的环境. 测试组的同事基本都没有安装Python环境, 于是乎, 我就想直接在 ...
- idea 中dao层自动生成接口
1.在生成接口的类上右键 2.选中要生成的接口方法 3.点击Yes 4.出现(? reference in ? file)即生成成功
- Android程序backtrace分析方法
如何分析Android程序的backtrace 最近碰到Android apk crash的问题,单从log很难定位.从tombstone里面得到下面的backtrace. *** *** *** * ...
- git 创建项目
Command line instructions Git global setup git config --global user.name "quliangliang" gi ...
- PIL库图像处理
PIL有如下几个模块 Image模块.ImageChops模块.ImageCrackCode模块 ImageDraw模块.ImageEnhance模块.ImageFile模块 ImageFileIO模 ...
- 【Solidity】学习(2)
address 地址类型 40个16进制数,160位 地址包括合约地址和账户地址 payable 合约充值 balance,指的是当前地址的账户value,单位是wei this指的是当前合约的地址 ...
- 6 week work 3
sticky vs fixed sticky:表示粘贴到某个位置.当组件设置了该属性值后,当页面滑动时,组件会跟着页面移动,当组件触及到窗体后,页面若继续滑动,组件则处在与窗体接触的位置不动.元素的定 ...