Storm知识点

1. 离线计算是什么?
2. 流式计算是什么?
3. storm核心组件和架构?
- 核心组件
- 架构
4. 并发度
5. Storm运行模式
6. Storm常见的分组策略
7. Storm操作命令
- 任务提交命令:storm jar 【jar路径】 【拓扑包名.拓扑类名】 【拓扑名称】
storm jar /export/servers/storm/examples/storm-starter/storm-starter-topologies-1.0.3.jar org.apache.storm.starter.WordCountTopology wordcount
hadoop jar /usr/local/wordcount.jar /data.txt /wcout
- 杀死任务命令:storm kill 【拓扑名称】 -w 10(执行kill命令时可以通过-w [等待秒数]指定拓扑停用以后的等待时间)
storm kill topology-name -w 10
- 停用任务命令:storm deactive 【拓扑名称】
storm deactive topology-name
- 启用任务命令:storm activate 【拓扑名称】
storm activate topology-name
- 重新部署任务命令:storm rebalance 【拓扑名称】
storm rebalance topology-name
- Spout创建一个新的Tuple时,会发一个消息通知acker去跟踪;
- Bolt在处理Tuple成功或失败后,也会发一个消息通知acker;
- acker会找到发射该Tuple的Spout,回调其ack或fail方法。
//BaseBasicBolt 实现可靠消息传递
public class SplitSentence extends BaseBasicBolt {//自动建立 anchor,自动 ack
public void execute(Tuple tuple, BasicOutputCollector collector) {
String sentence = tuple.getString(0);
for(String word: sentence.split(" ")) {
collector.emit(new Values(word));
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
//BaseRichBolt 实现可靠消息传递
public class SplitSentence extends BaseRichBolt {//建立 anchor 树以及手动 ack 的例子
OutputCollector _collector;
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
_collector = collector;
}
public void execute(Tuple tuple) {
String sentence = tuple.getString(0);
for(String word: sentence.split(" ")) {
_collector.emit(tuple, new Values(word)); // 建立 anchor 树
}
_collector.ack(tuple); //手动 ack,如果想让 Spout 重发该 Tuple,则调用 _collector.fail(tuple);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
9. 调整可靠性
- 在build topology时,设置acker数目为0,即conf.setNumAckers(0);
- 在Spout中,不指定messageId,使得Storm无法追踪;
- 在Bolt中,使用Unanchor方式发射新的Tuple。
10. Jstorm查看CPU核数
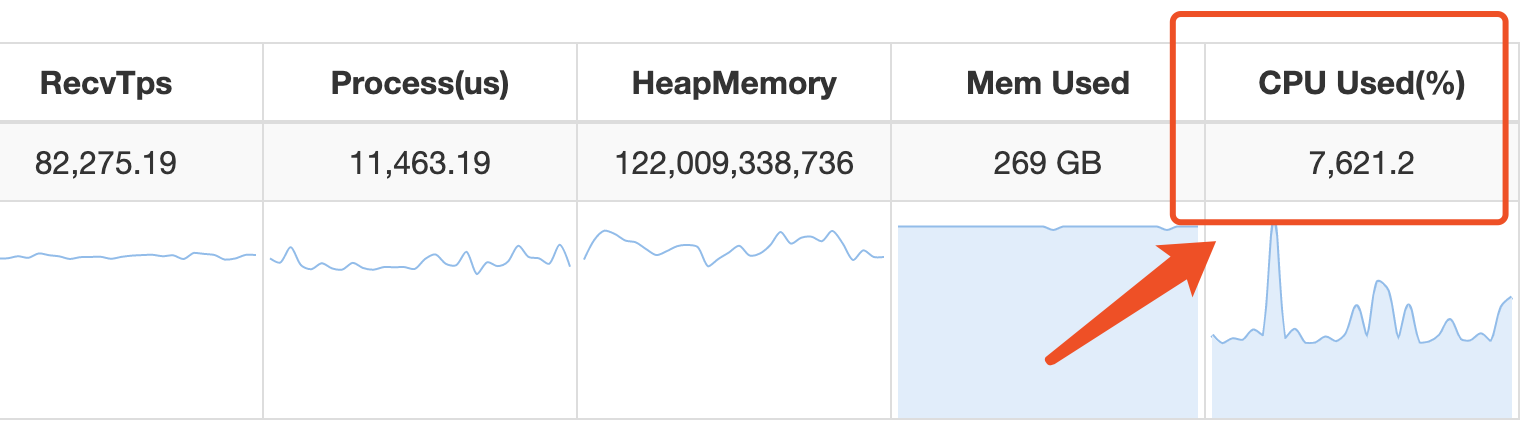
11. Jstorm消费kakfa单条数据太大起Lag
Kafka spoutConfig.fetchSizeBytes = ;
Kafka spoutConfig.bufferSizeBytes = ;
Storm知识点的更多相关文章
- Storm知识点笔记
Spark和Storm Spark基于MapReduce算法实现的分布式计算,不同于MapReduce的是,作业中间结果可以保存在内存中,而不要再读写HDFS, Spark适用于数据挖掘和机器学习等需 ...
- [大数据面试题]storm核心知识点
1.storm基本架构 storm的主从分别为Nimbus.Supervisor,工作进程为Worker. 2.计算模型 Storm的计算模型分为Spout和Bolt,Spout作为管口.Bolt作为 ...
- 初版storm项目全流程自动化测试代码实现
由于项目需要,写了版针对业务的自动化测试代码,主要应用场景在于由于业务日趋复杂,一些公共代码的改动,担心会影响已有业务.还没进行重写,但知识点还是不少的与大家分享实践下.首先,介绍下整个流处理的业务流 ...
- 升级版:深入浅出Hadoop实战开发(云存储、MapReduce、HBase实战微博、Hive应用、Storm应用)
Hadoop是一个分布式系统基础架构,由Apache基金会开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力高速运算和存储.Hadoop实现了一个分布式文件系 ...
- 亿级流量场景下,大型架构设计实现【2】---storm篇
承接之前的博:亿级流量场景下,大型缓存架构设计实现 续写本博客: ****************** start: 接下来,我们是要讲解商品详情页缓存架构,缓存预热和解决方案,缓存预热可能导致整个系 ...
- Hadoop storm大数据分析 知识体系结构
最近工作工作有用到hadoop 和storm,最近看到一个网站上例句的hadoop 和storm的知识体系.所以列出来供大家了解和学习.来自哪个网站就不写了以免以为我做广告额. 目录结构知识点还是挺全 ...
- Storm系列二: Storm拓扑设计
Storm系列二: Storm拓扑设计 在本篇中,我们就来根据一个案例,看看如何去设计一个拓扑, 如何分解问题以适应Storm架构,同时对Storm拓扑内部的并行机制会有一个基本的了解. 本章代码都在 ...
- mysql常见知识点总结
mysql常见知识点总结 参考: http://www.cnblogs.com/hongfei/archive/2012/10/20/2732516.html https://www.cnblogs. ...
- 牛客网Java刷题知识点之Java 集合框架的构成、集合框架中的迭代器Iterator、集合框架中的集合接口Collection(List和Set)、集合框架中的Map集合
不多说,直接上干货! 集合框架中包含了大量集合接口.这些接口的实现类和操作它们的算法. 集合容器因为内部的数据结构不同,有多种具体容器. 不断的向上抽取,就形成了集合框架. Map是一次添加一对元素. ...
随机推荐
- GitHub for Windows离线安装包
国内安装github客户端,真的很痛!! 偶然找到了离线安装包,感谢作者的资源分享!!! 地址:http://download.csdn.net/download/lyg468088/8723039? ...
- 二路归并算法的java实现
“归并”的含义是将两个或者两个以上的有序表组合成一个新的有序表. 假设待排序表含有n个元素,则可以看成是n个有序的子表,每个子表的长度为1,然后两两归并,得到(n/2)或者(n/2+1)个长度为2或1 ...
- Android为TV端助力 Intent匹配action,category和data原则
1.当你在androidmanifest里面定义了一个或多个action时 你使用隐式意图其他activity或者service时,规定你隐式里面的action必须匹配XML中定义的action,可以 ...
- Android开发学习之RecyclerView
1.在app/build.gradle中添加RecyclerView依赖 implementation 'com.android.support:recyclerview-v7:28.0.0' 注意依 ...
- git 入门教程之版本控制
版本控制 我们知道 git 是分布式版本控制系统,所以称被控制对象是版本本身没错,但是从git 命令中发现,并没有版本这个名词,有的只是commit,所以前几节我一直称其为提交. 为了避免后续教程引发 ...
- MySQL优化技巧【持续更新】
前言 应用程序或web网页有时慢的像蜗牛爬似的,可能是网络原因,可能是系统架构原因,还有可能是数据库原因.那么如何提高数据库SQL语句执行速度呢?下面是积累的一些优化技巧,望对君有用. 正文 1.比较 ...
- SQL Server OPTION (OPTIMIZE FOR UNKNOWN) 测试总结
关于SQL Server的查询提示OPTION (OPTIMIZE FOR UNKNOWN) ,它是解决参数嗅探的方法之一. 而且对应的SQL语句会缓存,不用每次都重编译.关键在于它的执行计划的准 ...
- 图文并茂 RAID 技术全解 – RAID0、RAID1、RAID5、RAID10
RAID 技术相信大家都有接触过,尤其是服务器运维人员,RAID 概念很多,有时候会概念混淆.这篇文章为网络转载,写得相当不错,它对 RAID 技术的概念特征.基本原理.关键技术.各种等级和发展现状进 ...
- 在CentOS上配置SAMBA共享目录(转载)
在CentOS上配置SAMBA共享目录 From: https://blog.csdn.net/qiumei1101381170/article/details/53265341 2016年11月21 ...
- AspNet MVC中使用Hangfire执行定时任务
Hangfire在Aspnet中执行定时任务: 第一步: NuGet中加入Hangfire包 第二步: 添加Owin的自启动 第三步.Hangfire的后台控制仪表盘默认情况下只能本地访问,外网访问需 ...