【hive】count() count(if) count(distinct if) sum(if)的区别
表名: user_active_day (用户日活表)
表内容:
user_id(用户id) user_is_new(是否新用户 1:新增用户 0:老用户) location_city(用户所在地区) partition_date(日期分区)
需求:
找出20180901至今的xxx地区的用户日活量以及新增用户量
思路:
筛选日期分区和地区,统计user_id的数量为用户日活量,统计user_is_new = 1的数量为新增用户量.
最开始写的hql语句
select partition_date,count(user_id),
count(if(user_is_new = 1, user_id, 0)) --注意新增用户量的统计
from dw.nice_live_dw_user_active_day
where location_city like '%xxx%' and partition_date >= 20180901
group by partition_date;
我们使用count(if())来进行筛选统计,但是效果并没有达到,出现的结果如下
20180901 16737 16737
根本就没有达到筛选的目的,为什么?
这就要从count的机制说起
首先count()是对数据进行计数,说白了就是你来一条数据我计数一条,我不关心你怎么分类,我只对数据计数
每条数据从if()函数出来,还是一条数据,所以count+1
所以count(user_id)跟count(if(user_id))没有任何的区别.
我们稍做修改
select partition_date,count(user_id),
count(distinct if(user_is_new = 1, user_id, 0)) --注意新增用户量的统计,加了distinct去重
from dw.nice_live_dw_user_active_day
where location_city like '%xxx%' and partition_date >= 20180901
group by partition_date;
结果如下
20180901 16737 261
这次看着就像是对了吧,我们加了distinct进行去重
每次来一条数据先过if()然后再进行去重最后统计.但是实际上结果依旧是错误的.
我们来模拟一下筛选统计的过程
我们有这样四条数据
user_id user_is_new
1 1
2 0
3 1
4 0
表中的数据是一条一条遍历的,
(1)当user_id = 1的数据过来的时候,我们先过if函数 user_is_new = 1 ==> count(distinct user_id = 1),
然后我们把user_id = 1进行重复判断,我们用一个模拟容器来模拟去重,
从容器里找user_id = 1的数据,发现没有,不重复,所以通过我们把count+1,然后把user_id = 1的数据放入,用于下条去重
(2)当user_id = 2的数据过来的时候,我们先过if函数 user_is_new = 0 ==> count(distinct 0),
然后我们把0进行重复判断,
从容器里找0的数据,发现没有,不重复,所以通过我们把count+1,然后把0的数据放入,用于下条去重
(3)当user_id = 3的数据过来的时候,我们先过if函数 user_is_new = 1 ==> count(distinct user_id = 3),
然后我们把user_id = 3进行重复判断,
从容器里找user_id = 3的数据,发现没有,不重复,所以通过我们把count+1,然后把user_id = 3的数据放入,用于下条去重
(4)当user_id = 4的数据过来的时候,我们先过if函数 user_is_new = 0 ==> count(distinct 0),
然后我们把0进行重复判断,
从容器里找0的数据,发现重复,是之前user_id = 2的时候过if()转化成0的那条数据,所以count不执行
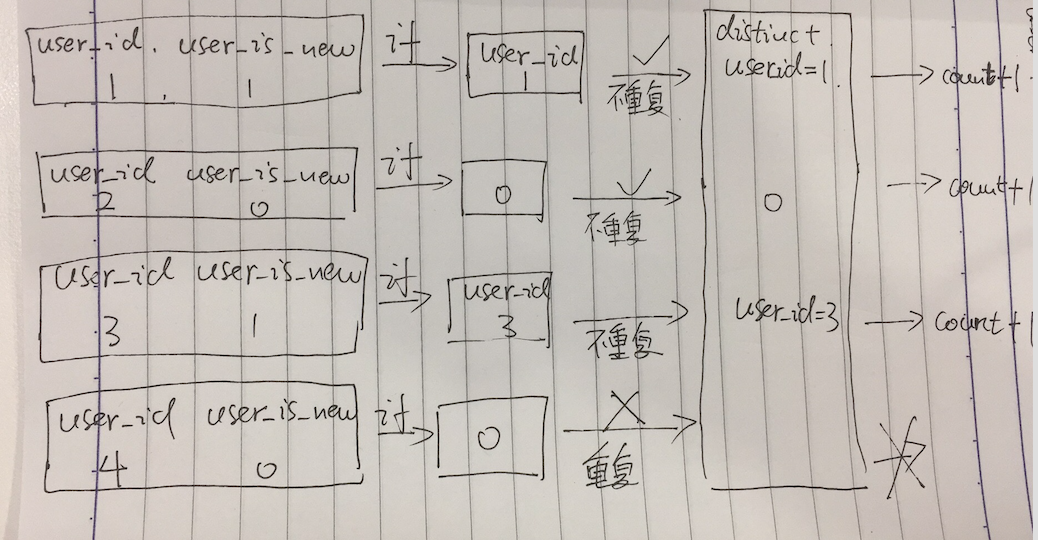
我们通过模拟count(distinct if)过程发现,在count的时候我们把不符合条件的最开始的那条语句也count进去了一次
导致最终结果比正确结果多了1.
我们在原基础语句上再减去1就是正确的hql语句
其实在日常中我们做分类筛选统计的时候一般是用sum来完成的,符合条件sum+1,不符合条件sum+0
select partition_date,count(user_id),
sum(if(user_is_new = 1, 1, 0)) --用sum进行筛选统计
from dw.nice_live_dw_user_active_day
where location_city like '%xxx%' and partition_date >= 20180901
group by partition_date;
结果如下
20180901 16737 260
sum(if)只试用于单个条件判断,如果筛选条件很多,我们可以用sum(case when then else end)来进行多条件筛选
注意,hive中并没有sum(distinct col1)这种使用方式,我们可以使用sum(col) group by col来达到相同效果.
【hive】count() count(if) count(distinct if) sum(if)的区别的更多相关文章
- 【MySQL】汇总数据 - avg()、count()、max()、min()、sum()函数的使用
第12章 汇总数据 文章目录 第12章 汇总数据 1.聚集函数 1.1.AVG()函数 avg() 1.2.COUNT()函数 count() 1.3. MAX()函数 max() 1.4.MIN() ...
- [MongoDB]count,gourp,distinct
摘要 上篇文章介绍了CRUD的操作,会了这些,基本上可以完成很多工作了.但如果遇到统计类的操作,那么就需要学习下本篇的内容了. 相关文章 [MongoDB]入门操作 [MongoDB]增删改查 cou ...
- 【优化】COUNT(1)、COUNT(*)、COUNT(常量)、COUNT(主键)、COUNT(ROWID)、COUNT(非空列)、COUNT(允许为空列)、COUNT(DISTINCT 列名)
[优化]COUNT(1).COUNT(*).COUNT(常量).COUNT(主键).COUNT(ROWID).COUNT(非空列).COUNT(允许为空列).COUNT(DISTINCT 列名) 1. ...
- Django学习路17_聚合函数(Avg平均值,Count数量,Max最大,Min最小,Sum求和)基本使用
使用方法: 类名.objects.aggregate(聚合函数名('表的列名')) 聚合函数名: Avg 平均值 Count数量 Max 最大 Min 最小 Sum 求和 示例: Student.ob ...
- Oracle 中count(1) 和count(*) 的区别
count()与count(*)比较: 如果你的数据表没有主键,那么count()比count(*)快 如果有主键的话,那主键(联合主键)作为count的条件也比count(*)要快 如果你的表只有一 ...
- 【MySQL】技巧 之 count(*)、count(1)、count(col)
只看结果的话,Select Count(*) 和 Select Count(1) 两着返回结果是一样的. 假如表沒有主键(Primary key), 那么count(1)比count(*)快,如果有主 ...
- 关于count(1) 和 count(*)
Q:What is the difference between count(1) and count(*) in a sql queryeg.select count(1) from emp; an ...
- select count(*)和select count(1)的区别 (转)
A 一般情况下,Select Count (*)和Select Count(1)两着返回结果是一样的 假如表沒有主键(Primary key), 那么count(1)比count(*)快, 如果有主键 ...
- 【转载】Oracle 中count(1) 、count(*) 和count(列名) 函数的区别
1)count(1)与count(*)比较: 1.如果你的数据表没有主键,那么count(1)比count(*)快2.如果有主键的话,那主键(联合主键)作为count的条件也比count(*)要快3. ...
随机推荐
- 浅谈vuex
很多技术,刚接触的时候:这是啥?用的时候:哟嚯,是挺好用的!加以研究:卧槽,就是这么个逼玩意儿! 最近接手了一个别人写了1/5的vue项目(页面画了1/3,接口啥都没对); 对于表格中的数据项操作以及 ...
- mysql 数据操作 多表查询 子查询 带EXISTS关键字的子查询
带EXISTS关键字的子查询 EXISTS关字键字表示存在. EXISTS 判断某个sql语句的有没有查到结果 有就返回真 true 否则返回假 False 如果条件成立 返回另外一条sql语句的返 ...
- 1.Anaconda安装Tensorflow报错UnicodeDecodeError: 'utf-8' codec can't decode ## invalid start byte的问题之解决
安装TensorFlow pip install --ignore-installed --upgrade tensorflow 报错: UnicodeDecodeError: 'utf-8' cod ...
- SLAM FOR DUMMIES 第5-8章 中文翻译
5,SLAM的处理过程 SLAM过程包括许多步骤,该过程的目标是使用环境更新机器人的位置.由于机器人的里程计通常是存在误差的,我们不能直接依赖于里程计.我们可以用激光扫描环境来校正机器人的位置,这是通 ...
- Webwork 学习笔记
1. 首先配置一个简单的webwork应用 核心jar: commons-logging.jarognl.jaroscore.jarvelocity-dep.jarwebwork-2.1.7.jarx ...
- in `connect': SSL_connect returned=1 errno=0 state=SSLv3 read server certificate B: certificate verify failed (OpenSSL::SSL::SSLError)
最近在用ruby的一些库的时候,总是出现这个错误. 在使用net/imap库的时候,或者net/http库(主要是用到了https,https是用了ssl) 的时候,具体如下: 错误提示:E:/Rub ...
- ACM ICPC, Damascus University Collegiate Programming Contest(2018) Solution
A:Martadella Stikes Again 水. #include <bits/stdc++.h> using namespace std; #define ll long lon ...
- AVAudioFoundation(4):音视频录制
本文转自:AVAudioFoundation(4):音视频录制 | www.samirchen.com 本文主要内容来自 AVFoundation Programming Guide. 采集设备的音视 ...
- Linux学习笔记之Centos7设置Linux静态IP
***如下资料源自互联网*** 这里以CentOS 7系列为例设置静态IP,原来RedHat系列的Linux发行版可以通过setup工具方便的设置静态IP,但是在版本7之后setup工具的功能就逐渐减 ...
- Django学习笔记之form组件的局部钩子和全局钩子
本文通过注册页面的form组件,查看其中使用的全局钩子和局部钩子. # Create your views here. class RegForm(forms.Form): username = fo ...