rethinking imageNet pre-training
paper url: https://arxiv.org/abs/1811.08883
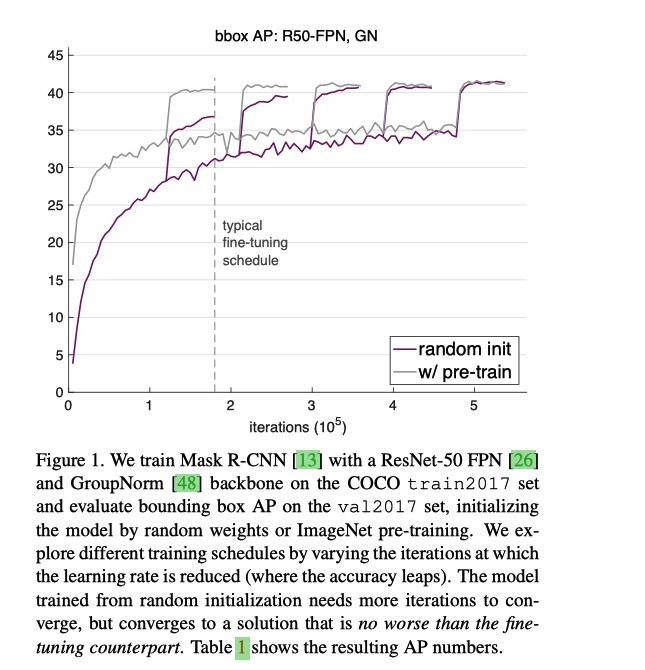 

当在数据量足够和训练iterations足够的情况下,ImageNet pretrain不会对最后的性能有帮助,但是会加速收敛(需要用GN或SyncBN);
当数据量不够的情况下, 模型是需要在 ImageNet 上预训练的
- training from scratch 是可行的, 但是需要合适的 normalization(如GN)和更多的迭代。
- 根据数据量等情况,training from scratch 可以不比 fine-tune 的效果差。
- fine-tune 的方式还是收敛速度快很多。
- 除非, 目标数据集规模很小, fine-tune 是没有办法减少过拟合的; fine-tune 时候, 需要让大的 lr迭代次数更多,如果小的lr迭代次数过多的话,很容易过拟合。
- 对于位置敏感的任务,在分类任务上预训练的模型进行 fine-tune 的效果会变小; 比如需要对目标精确定位的任务,在 ImageNet 上预训练的模型上 fine-tune 没效果,比如 keypoint 的任务。
rethinking imageNet pre-training的更多相关文章
- 对Rethinking ImageNet Pre-training的理解
Kaiming He的这篇论文提出了一个新问题,在目标检测.实例分割和人体关键点检测等领域,预训练的模型是否真的起了作用?通过实验,得出结论:迭代次数较少时,使用预训练模型效果更好:但是只要迭代次数充 ...
- ICCV 2019|70 篇论文抢先读,含目标检测/自动驾驶/GCN/等(提供PDF下载)
虽然ICCV2019已经公布了接收ID名单,但是具体的论文都还没放出来,为了让大家更快得看论文,我们汇总了目前已经公布的大部分ICCV2019 论文,并组织了ICCV2019论文汇总开源项目(http ...
- 转:谷歌大脑科学家 Caffe缔造者 贾扬清 微信讲座完整版
[转:http://blog.csdn.net/buaalei/article/details/46344675] 大家好!我是贾扬清,目前在Google Brain,今天有幸受雷鸣师兄邀请来和大家聊 ...
- 贾扬清分享_深度学习框架caffe
Caffe是一个清晰而高效的深度学习框架,其作者是博士毕业于UC Berkeley的 贾扬清,目前在Google工作.本文是根据机器学习研究会组织的online分享的交流内容,简单的整理了一下. 目录 ...
- 『计算机视觉』物体检测之RefineDet系列
Two Stage 的精度优势 二阶段的分类:二步法的第一步在分类时,正负样本是极不平衡的,导致分类器训练比较困难,这也是一步法效果不如二步法的原因之一,也是focal loss的motivation ...
- Batch_Size对网络训练结果的影响
最近在跑一些网络时发现,训练完的网络在测试集上的效果总是会受Batch_Size 大小的影响.这种现象跟以往自己所想象的有些出入,于是出于好奇,各种搜博客,大致得出了自己想要的答案,现写一篇博客记录一 ...
- 『计算机视觉』Mask-RCNN_项目文档翻译
基础介绍 项目地址:Mask_RCNN 语言框架:Python 3, Keras, and TensorFlow Python 3.4, TensorFlow 1.3, Keras 2.0.8 其他依 ...
- 谷歌大脑科学家 Caffe缔造者 贾扬清 微信讲座完整版
谷歌大脑科学家 Caffe缔造者 贾扬清 微信讲座完整版 一.讲座正文: 大家好!我是贾扬清237,目前在Google Brain83,今天有幸受雷鸣师兄邀请来和大家聊聊Caffe60.没有太多准备, ...
- Google大脑科学家贾杨清(Caffe缔造者)-微信讲座
Google大脑科学家贾杨清(Caffe缔造者)-微信讲座 机器学习Caffe 贾扬清 caffe 一.讲座正文: 大家好!我是贾扬清178,目前在Google Brain69,今天有幸受雷鸣师兄 ...
随机推荐
- openstack第六章:dashboard
第六篇horizon— Web管理界面 一.horizon 介绍: 理解 horizon Horizon 为 Openstack 提供一个 WEB 前端的管理界面 (UI 服务 )通过 ...
- Python-包-65
包 包是一种通过使用‘.模块名’来组织python模块名称空间的方式. 1. 无论是import形式还是from...import形式,凡是在导入语句中(而不是在使用时)遇到带点的,都要第一时间提高警 ...
- Unity TimeLine 资源结构
---恢复内容开始--- 先看一个TimeLine,如图 再来看看在Inspector中的PlayableDirector 其他参数字面意思很清楚了不再赘述,着重讲一下一个TimeLine绑定的资源. ...
- No repeats please 全排列
把一个字符串中的字符重新排列生成新的字符串,返回新生成的字符串里没有连续重复字符的字符串个数.连续重复只以单个字符为准 例如, aab 应该返回 2 因为它总共有6中排列 (aab, aab, aba ...
- JavaScript加载次序问题
3个文件,一个index.html如下 <!DOCTYPE html> <html> <head> <meta charset="UTF-8&quo ...
- 01——Solr学习之全文检索服务系统的基础认识
一.为什么要用Solr,Solr是个什么东西? 1.1.Solr是个开源的搜索服务器 1.2.我们用Solr主要实现搜索功能,一般的网站首页都会有一个大大的搜索框,用来搜索此网站上的商品啊什么的,如下 ...
- Vuex 存储||获取后台接口数据
如果你对 Vuex 有一定的了解的话呢,可以继续这一篇的学习了,如果没有的话, 建议先看一看我的上一篇 Vuex基础:地址在下面 Vuex的详解与使用 Vuex刷新数据不丢失 这篇接着上一篇: 这篇将 ...
- kubernetes 1.14安装部署metrics-server插件
简单介绍: 如果使用kubernetes的自动扩容功能的话,那首先得有一个插件,然后该插件将收集到的信息(cpu.memory..)与自动扩容的设置的值进行比对,自动调整pod数量.关于该插件,在ku ...
- SAM求多个串的最长公共子串
又学到一个\(SAM\)的新套路QvQ 思路 考虑用其中的一个串建个\(SAM\),然后用其他的串在上面匹配,匹配时更新答案 首先有一个全局变量\(len\),表示当前已匹配的长度.假设目前在点\(u ...
- pandas的读写
import as pd import numpy as np import matplotlib.pyplot as plt #df.to_excel('C:Users/history/Deskto ...