java多线程中 volatile与synchronized的区别-阿里面试
volatile 与 synchronized 的比较(阿里面试官问的问题)
①volatile轻量级,只能修饰变量。synchronized重量级,还可修饰方法
②volatile只能保证数据的可见性,不能用来同步,因为多个线程并发访问volatile修饰的变量不会阻塞。
synchronized不仅保证可见性,而且还保证原子性,因为,只有获得了锁的线程才能进入临界区,从而保证临界区中的所有语句都全部执行。多个线程争抢synchronized锁对象时,会出现阻塞。
volatile本质是在告诉jvm当前变量在寄存器中的值是不确定的,需要从主存中读取,synchronized则是锁定当前变量,只有当前线程可以访问该变量,其他线程被阻塞住.
volatile仅能使用在变量级别,synchronized则可以使用在变量,方法.
volatile仅能实现变量的修改可见性,但不具备原子特性,而synchronized则可以保证变量的修改可见性和原子性.
volatile不会造成线程的阻塞,而synchronized可能会造成线程的阻塞.
volatile标记的变量不会被编译器优化,而synchronized标记的变量可以被编译器优化.
二,线程安全性
线程安全性包括两个方面,①可见性。②原子性。
仅仅使用volatile并不能保证线程安全性。而synchronized则可实现线程的安全性。
三,volatile关键字的可见性
要想理解volatile关键字,得先了解下JAVA的内存模型,Java内存模型的抽象示意图如下:
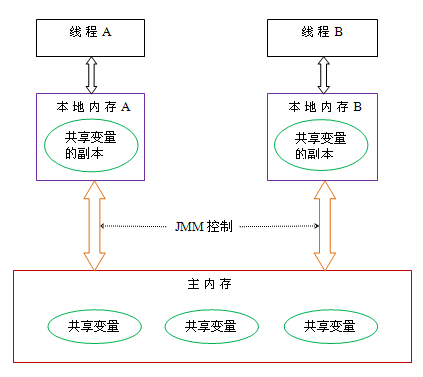
从图中可以看出:
①每个线程都有一个自己的本地内存空间--线程栈空间 线程执行时,先把变量从主内存读取到线程自己的本地内存空间,然后再对该变量进行操作
②对该变量操作完后,在某个时间再把变量刷新回主内存
在Java中,为了保证多线程读写数据时保证数据的一致性,可以采用两种方式:
(a)如用synchronized关键字,或者使用锁对象.
(b)使用volatile关键字,用一句话概括volatile,它能够使变量在值发生改变时能尽快地让其他线程知道.
synchronized
所有加上synchronized 和 块语句,在多线程访问的时候,同一时刻只能有一个线程能够用synchronized 修饰的方法 或者 代码块。
volatile
首先我们要先意识到有这样的现象,编译器为了加快程序运行的速度,对一些变量的写操作会先在寄存器或者是CPU缓存上进行,最后才写入内存.
而在这个过程,变量的新值对其他线程是不可见的.而volatile的作用就是使它修饰的变量的读写操作都必须在内存中进行!
用volatile修饰的变量,线程在每次使用变量的时候,都会读取变量修改后的最的值。volatile很容易被误用,用来进行原子性操作。
对于volatile修饰的变量,JVM虚拟机只保证从主内存加载到线程工作内存的值是最新的。
因此,就存在内存可见性问题,看一个示例程序: 自己试过,确实这样:
public class RunThread extends Thread {
private boolean isRunning = true;
public boolean isRunning() {
return isRunning;
}
public void setRunning(boolean isRunning) {
this.isRunning = isRunning;
}
@Override
public void run() {
System.out.println("进入到run方法中了");
while (isRunning == true) {
}
System.out.println("线程执行完成了");
}
}
public class Run {
public static void main(String[] args) {
try {
RunThread thread = new RunThread();
thread.start();
Thread.sleep(1000);
thread.setRunning(false);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
Run.java 第28行,main线程 将启动的线程RunThread中的共享变量设置为false,从而想让RunThread.java 第14行中的while循环结束。
如果,我们使用JVM -server参数执行该程序时,RunThread线程并不会终止!从而出现了死循环!!
原因分析:
现在有两个线程,一个是main线程,另一个是RunThread。它们都试图修改 第三行的 isRunning变量。按照JVM内存模型,main线程将isRunning读取到本地线程内存空间,修改后,再刷新回主内存。
而在JVM 设置成 -server模式运行程序时,线程会一直在私有堆栈中读取isRunning变量。因此,RunThread线程无法读到main线程改变的isRunning变量
从而出现了死循环,导致RunThread无法终止
解决方法,在第三行代码处用 volatile 关键字修饰即可。这里,它强制线程从主内存中取 volatile修饰的变量。
volatile private boolean isRunning = true;
扩展一下,当多个线程之间需要根据某个条件确定 哪个线程可以执行时,要确保这个条件在 线程 之间是可见的。因此,可以用volatile修饰。
综上,volatile关键字的作用是:使变量在多个线程间可见(可见性)
二,volatile关键字的非原子性
所谓原子性,就是某系列的操作步骤要么全部执行,要么都不执行。
比如,变量的自增操作 i++,分三个步骤:
①从内存中读取出变量 i 的值
②将 i 的值加1
③将 加1 后的值写回内存
这说明 i++ 并不是一个原子操作。因为,它分成了三步,有可能当某个线程执行到了第②时被中断了,那么就意味着只执行了其中的两个步骤,没有全部执行。
关于volatile的非原子性,看个示例:
public class MyThread extends Thread {
public volatile static int count;
private static void addCount() {
for (int i = 0; i < 100; i++) {
count++;
}
System.out.println("count=" + count);
}
@Override
public void run() {
addCount();
}
}
public class Run {
public static void main(String[] args) {
MyThread[] mythreadArray = new MyThread[100];
for (int i = 0; i < 100; i++) {
mythreadArray[i] = new MyThread();
}
for (int i = 0; i < 100; i++) {
mythreadArray[i].start();
}
}
}
MyThread类第2行,count变量使用volatile修饰
Run.java 第20行 for循环中创建了100个线程,第25行将这100个线程启动去执行 addCount(),每个线程执行100次加1
期望的正确的结果应该是 100*100=10000,但是,实际上count并没有达到10000
原因是:volatile修饰的变量并不保证对它的操作(自增)具有原子性。(对于自增操作,可以使用JAVA的原子类AutoicInteger类保证原子自增)
比如,假设 i 自增到 5,线程A从主内存中读取i,值为5,将它存储到自己的线程空间中,执行加1操作,值为6。此时,CPU切换到线程B执行,从主从内存中读取变量i的值。由于线程A还没有来得及将加1后的结果写回到主内存,线程B就已经从主内存中读取了i,因此,线程B读到的变量 i 值还是5
相当于线程B读取的是已经过时的数据了,从而导致线程不安全性。这种情形在《Effective JAVA》中称之为“安全性失败”
综上,仅靠volatile不能保证线程的安全性。(原子性)
此外,volatile关键字修饰的变量不会被指令重排序优化。这里以《深入理解JAVA虚拟机》中一个例子来说明下自己的理解:
线程A执行的操作如下:
Map configOptions ;
char[] configText; volatile boolean initialized = false; //线程A首先从文件中读取配置信息,调用process...处理配置信息,处理完成了将initialized 设置为true
configOptions = new HashMap();
configText = readConfigFile(fileName);
processConfig(configText, configOptions);//负责将配置信息configOptions 成功初始化
initialized = true;
线程B等待线程A把配置信息初始化成功后,使用配置信息去干活.....线程B执行的操作如下:
while(!initialized)
{
sleep();
} //使用配置信息干活
doSomethingWithConfig();
如果initialized变量不用 volatile 修饰,在线程A执行的代码中就有可能指令重排序。
即:线程A执行的代码中的最后一行:initialized = true 重排序到了 processConfig方法调用的前面执行了,这就意味着:配置信息还未成功初始化,但是initialized变量已经被设置成true了。那么就导致 线程B的while循环“提前”跳出,拿着一个还未成功初始化的配置信息去干活(doSomethingWithConfig方法)。。。。
因此,initialized 变量就必须得用 volatile修饰。这样,就不会发生指令重排序,也即:只有当配置信息被线程A成功初始化之后,initialized 变量才会初始化为true。综上,volatile 修饰的变量会禁止指令重排序(有序性)
在 java 垃圾回收整理一文中,描述了jvm运行时刻内存的分配。其中有一个内存区域是jvm虚拟机栈,每一个线程运行时都有一个线程栈,
线程栈保存了线程运行时候变量值信息。当线程访问某一个对象时候值的时候,首先通过对象的引用找到对应在堆内存的变量的值,然后把堆内存
变量的具体值load到线程本地内存中,建立一个变量副本,之后线程就不再和对象在堆内存变量值有任何关系,而是直接修改副本变量的值,
在修改完之后的某一个时刻(线程退出之前),自动把线程变量副本的值回写到对象在堆中变量。这样在堆中的对象的值就产生变化了。下面一幅图
描述这写交互
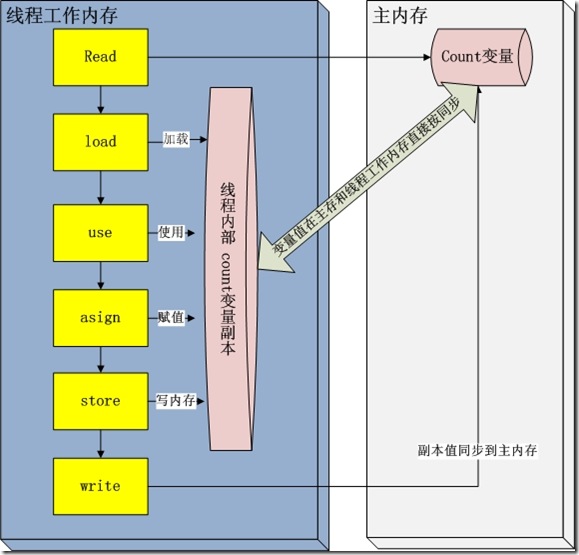
read and load 从主存复制变量到当前工作内存
use and assign 执行代码,改变共享变量值
store and write 用工作内存数据刷新主存相关内容
其中use and assign 可以多次出现
但是这一些操作并不是原子性,也就是 在read load之后,如果主内存count变量发生修改之后,线程工作内存中的值由于已经加载,不会产生对应的变化,所以计算出来的结果会和预期不一样
对于volatile修饰的变量,jvm虚拟机只是保证从主内存加载到线程工作内存的值是最新的
例如假如线程1,线程2 在进行read,load 操作中,发现主内存中count的值都是5,那么都会加载这个最新的值
在线程1堆count进行修改之后,会write到主内存中,主内存中的count变量就会变为6
线程2由于已经进行read,load操作,在进行运算之后,也会更新主内存count的变量值为6
导致两个线程及时用volatile关键字修改之后,还是会存在并发的情况。
下面看一个例子,我们实现一个计数器,每次线程启动的时候,会调用计数器inc方法,对计数器进行加一
执行环境——jdk版本:jdk1.6.0_31 ,内存 :3G cpu:x86 2.4G
public class Counter {
public static int count = 0;
public static void inc() {
//这里延迟1毫秒,使得结果明显
try {
Thread.sleep(1);
} catch (InterruptedException e) {
}
count++;
}
public static void main(String[] args) {
//同时启动1000个线程,去进行i++计算,看看实际结果
for (int i = 0; i < 1000; i++) {
new Thread(new Runnable() {
@Override
public void run() {
Counter.inc();
}
}).start();
}
//这里每次运行的值都有可能不同,可能为1000
System.out.println("运行结果:Counter.count=" + Counter.count);
}
}
输出为:
运行结果:Counter.count=995
实际运算结果每次可能都不一样,本机的结果为:运行结果:Counter.count=995,可以看出,在多线程的环境下,Counter.count并没有期望结果是100
很多人以为,这个是多线程并发问题,只需要在变量count之前加上volatile就可以避免这个问题,那我们在修改代码看看,看看结果是不是符合我们的期望
public class Counter {
public volatile static int count = 0;
public static void inc() {
//这里延迟1毫秒,使得结果明显
try {
Thread.sleep(1);
} catch (InterruptedException e) {
}
count++; }
public static void main(String[] args) {
//同时启动1000个线程,去进行i++计算,看看实际结果
for (int i = 0; i < 1000; i++) {
new Thread(new Runnable() {
@Override
public void run() {
Counter.inc();
}
}).start();
}
//这里每次运行的值都有可能不同,可能为1000
System.out.println("运行结果:Counter.count=" + Counter.count);
}
}
运行结果:
运行结果:Counter.count=992
运行结果还是没有我们期望的1000
java多线程中 volatile与synchronized的区别-阿里面试的更多相关文章
- 云时代架构阅读笔记七——Java多线程中如何使用synchronized关键字
关于线程的同步,可以使用synchronized关键字,或者是使用JDK 5中提供的java.util.concurrent.lock包中的Lock对象.本文探讨synchronized关键字. sy ...
- 转 Java多线程中Sleep与Wait的区别
Java中的多线程是一种抢占式的机制,而不是分时机制.抢占式的机制是有多个线程处于可运行状态,但是只有一个线程在运行. 共同点: 1. 他们都是在多线程的环境下,都可以在程序的调用处阻塞指定的毫秒数, ...
- Java多线程中Sleep与Wait的区别
Java中的多线程是一种抢占式的机制 而不是分时机制.抢占式机制指的是有多个线程处于可运行状态,但是只有一个线程在运行. 共同点: 1. 他们都是在多线程的环境下,都可以在程序的调用处阻塞指定的毫秒数 ...
- Java多线程中start()和run()的区别
Java的线程是通过java.lang.Thread类来实现的.VM启动时会有一个由主方法所定义的线程.可以通过创建Thread的实例来创建新的线程.每个线程都是通过某个特定Thread对象所对应的方 ...
- 多线程学习:Volatile与Synchronized的区别、什么是重排序
java线程的内存模型 java的线程内存模型中定义了每个线程都有一份自己的共享变量副本(本地内存),里面存放自己私有的数据,其他线程不能直接访问,而一些共享变量则存在主内存中,供所有线程访问. 上图 ...
- 多线程的指令重排问题:as-if-serial语义,happens-before语义;volatile关键字,volatile和synchronized的区别
一.指令重排问题 你写的代码有可能,根本没有按照你期望的顺序执行,因为编译器和 CPU 会尝试指令重排来让代码运行更高效,这就是指令重排. 1.1 虚拟机层面 我们都知道CPU执行指令的时候,访问内存 ...
- java线程中的sleep和wait区别
面试题:java线程中sleep和wait的区别以及其资 ...
- java多线程中的三种特性
java多线程中的三种特性 原子性(Atomicity) 原子性是指在一个操作中就是cpu不可以在中途暂停然后再调度,既不被中断操作,要不执行完成,要不就不执行. 如果一个操作时原子性的,那么多线程并 ...
- volatile和synchronized的区别
volatile和synchronized特点 首先需要理解线程安全的两个方面:执行控制和内存可见. 执行控制的目的是控制代码执行(顺序)及是否可以并发执行. 内存可见控制的是线程执行结果在内存中对其 ...
随机推荐
- Java开发笔记(三十三)字符包装类型
正如整型int有对应的包装整型Integer那样,字符型char也有对应的包装字符型Character.初始化字符包装变量也有三种方式,分别是:直接用等号赋值.调用包装类型的valueOf方法.使用关 ...
- 命令行BASH的基本操作
前面说了,我们要尽量少用GNOME图形界面,而应该以使用BASH命令行为主. SHELL Shell是操作系统内核的壳,因为我们不能直接操作系统的内核Kernel,只能通过Shell去操作,Shell ...
- 网络最大流算法—EK算法
前言 EK算法是求网络最大流的最基础的算法,也是比较好理解的一种算法,利用它可以解决绝大多数最大流问题. 但是受到时间复杂度的限制,这种算法常常有TLE的风险 思想 还记得我们在介绍最大流的时候提到的 ...
- Dynamics 365的系统作业实体记录增长太快怎么回事?
摘要: 本人微信公众号:微软动态CRM专家罗勇 ,回复294或者20190111可方便获取本文,同时可以在第一间得到我发布的最新博文信息,follow me!我的网站是 www.luoyong.me ...
- windows蓝屏代码
原始链接 引用自 https://docs.microsoft.com/zh-cn/windows-hardware/drivers/debugger/bug-check-code-referenc ...
- po编程——自动化测试面试必问
先来看一个在腾讯课堂首页搜索机构的操作步骤: 1:首先打开腾讯课堂的首页:https://ke.qq.com 2:点击课程或机构的下拉选择图标 3:选择机构 4:在搜索框输入要搜索的机构名称 5:点击 ...
- python开发规范和(configparser、random模块)
目录结构: bin:存放程序入口,程序启动文件. conf:存放配置文件,配置文件主要是一些全局变量,路径信息等. core:程序核心文件,不涉及到业务逻辑. app:存放和系统业务相关的逻辑. db ...
- python正则表达式模块re
正则表达式的特殊元素 匹配符号 描述 '.'(点dot) 在默认模式下,它匹配除换行符之外的任何字符.如果指定了DOTALL标志,则匹配包括换行符在内的任何字符 '^'(Caret) 匹配以字符串开头 ...
- c/c++ 继承与多态 继承中的public, protected, private
问题:类B私有继承类A,类A有个protected成员,那么在类B的成员函数里是否可以使用类A的protected成员? 可以使用. 估计有的同学说不对吧,类B都私有继承了类A了,怎么还能访问类A的p ...
- 利用java实现excel转pdf文件
在有些需求当中我们需要抓取字段并且填充到excel表格里面,最后将excel表格转换成pdf格式进行输出,我第一次接触这个需求时,碰到几个比较棘手的问题,现在一一列出并且提供解决方案. 1:excel ...