基于用户协同过滤--UserCF
UserCF
本系列文章主要介绍推荐系统领域相关算法原理及其实现。本文以项亮大神的《推荐系统实践》作为切入点,介绍推荐系统最基础的算法(可能也是最好用的)--基于用户的协同过滤算法(UserCF)。参考书中P44-50。
1.简述
假设在一个个性化的推荐系统中,用户A需要推荐,那么可以先找到与A有相似兴趣的用户,例如B、C、D把他们喜欢的,用户A没有听说过的物品推荐给A。这种方法被称为基于用户的协同过滤。
2.计算用户相似度
从算法原理中我们可以得到UserCF主要包括两个步骤:
1.找到和A用户兴趣相似的用户集合(B、C、D)。
2.找到这个集合中的用户喜欢,且目标用户A还未听说或购买过的物品推荐给目标用户。
步骤1.的关键其实就是计算用户兴趣的相似度。这里主要是利用用户行为来计算用户相似度。给定用户U和用户V,令N(u),N(v)分别表示用户u,v曾经有正反馈的用户集合。用Jaccard公式计算:
\]
或者通过余弦相似度计算:
\]
以书中数据为例:
train = {'A':('a','b','d'),'B':('a','c'),'C':('b','e'),'D':('c','d','e')}
\]
同理可计算Wac和Wad。
按书中对所有用户两两计算余弦相似度,时间复杂度是O(U*U),在用户量很大时非常耗时,事实上,很多用户之间并没有对同样的物品产生过行为,因此可以先过滤出N(u)交N(v)不等于0的用户对(u,v),然后再对其除以分母。
这里用item-user倒排表的方式,建立一个4*4的用户相似度矩阵C,最终得到的W[u][v]就是(u,v)对相似度的分子部分,再除以分母即可得到最终的用户相似度。如书中图2-7:

def UserSimilarity(train , IIF = False):
# IIF 是否对 过于热门即 购买人数过于多的物品 在计算用户相似度的时候进行惩罚
# 因为很多用户对之间并没有对相同的物品产生过行为,只计算对相同物品产生过行为的用户之间的相似度。
# 采用余弦相似度
# 建立倒排表,对每个物品保存只对其产生过行为的用户列表。
item_users = dict() # 物品-用户 倒排表
for u, items in train.items():
for i in items:
# 这里将 item_users.keys() 改为 item_users , 文中例子 应该用set 或 list存,而不是dict:
if i not in item_users:
item_users[i] = set()
item_users[i].add(u)
# 建立如图2-7所示的倒排矩阵
C = dict() # key 用户对 value 购买同一物品的次数
N = dict() # N(u) 表示用户购买的 商品数 {'A': 3, 'B': 2, 'C': 2, 'D': 3}
for i,users in item_users.items():
for u in users:
if u not in N.keys():
N[u] = 0
N[u] += 1
for v in users:
if u == v:
continue
if (u,v) not in C.keys():
C[u,v] = 0
if IIF:
# len(users) 表示购买此物品的用户数,越热门,购买用户越多,C[u,v] 就越小
# 相当于之前的分子是相交个数,现在是
C[u,v] += 1 / math.log(1 + len(users))
else:
C[u,v] += 1
W = dict()
for co_user, cuv in C.items():
W[co_user] = cuv / math.sqrt(N[co_user[0]]*N[co_user[1]])
return W
这里可以看下return的 W:
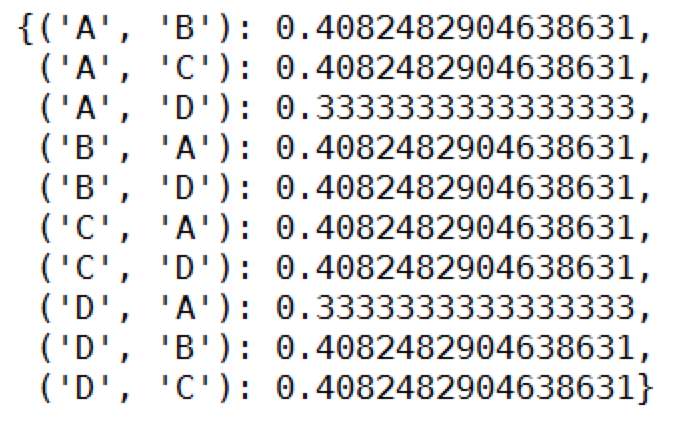
3.计算推荐结果
这里直接用书中P47的解释了,Wuv已经有了,其实就是根据W再乘一个权重r就可以了,r可以根据比如那些用户的行为更重要来改变,这里书中默认r都是1。

下述是推荐部分的代码:
def UserCFRecommend(user,train,W,k):
# rvi 代表用户v对物品i的权重
rvi = 1
rank = dict()
interacted_items = train[user]
related_user=[]
# 和 A 有相似度的用户 ,B,C,D
for co_user,sim in W.items():
if co_user[0] == user:S
related_user.append((co_user[1],sim))
# v : 有相似度的用户 , wuv : 用户间相似度
for v , wuv in sorted(related_user , key = lambda a:a[1], reverse = True)[0:k]:
for item in train[v]:
if item in interacted_items:
continue
else:
# 还是得初始化,才可以赋值
if item not in rank.keys():
rank[item] = 0
rank[item] += wuv*rvi
return rank
最后选择对A进行推荐,K取3,由于A对a,b,d有过行为,K=3又代表相似用户为B,C,D,所以会将c、e推荐给A。这里得到:

和书中结果一致。在书中对用户相似度的改进也在上述UserSimilarity部分的代码中体现了,只需在计算W的时候将参数 IIF=True 即可。该改进其实就是在计算u,v相似度时,对其进行惩罚,惩罚是基于在倒排表中所有购买此物品的用户长度,即此物品购买人数越多,提供的相似度越小,具体理解请参考代码。
代码详见:https://github.com/Alarical/Recommend/tree/master/UserCF
对于书中,表2-4 UserCF在movielens数据集中的运用,主要参考https://blog.csdn.net/u012050154/article/details/52268057大神的博客和代码,对与其代码增加了部分注释,详见我的github。
参考资料:
https://blog.csdn.net/guanbai4146/article/details/78016778
https://blog.csdn.net/u012050154/article/details/52268057
项亮 --《推荐系统实践》
基于用户协同过滤--UserCF的更多相关文章
- 推荐召回--基于用户的协同过滤UserCF
目录 1. 前言 2. 原理 3. 数据及相似度计算 4. 根据相似度计算结果 5. 相关问题 5.1 如何提炼用户日志数据? 5.2 用户相似度计算很耗时,有什么好的方法? 5.3 有哪些改进措施? ...
- 基于Python协同过滤算法的认识
Contents 1. 协同过滤的简介 2. 协同过滤的核心 3. 协同过滤的实现 4. 协同过滤的应用 1. 协同过滤的简介 关于协同过滤的一个最经典的例子就是看电影,有时候 ...
- (数据挖掘-入门-3)基于用户的协同过滤之k近邻
主要内容: 1.k近邻 2.python实现 1.什么是k近邻(KNN) 在入门-1中,简单地实现了基于用户协同过滤的最近邻算法,所谓最近邻,就是找到距离最近或最相似的用户,将他的物品推荐出来. 而这 ...
- Collaborative Filtering(协同过滤)算法详解
基本思想 基于用户的协同过滤算法是通过用户的历史行为数据发现用户对商品或内容的喜欢(如商品购买,收藏,内容评论或分享),并对这些喜好进行度量和打分.根据不同用户对相同商品或内容的态度和偏好程度计算用户 ...
- 【推荐系统实战】:C++实现基于用户的协同过滤(UserCollaborativeFilter)
好早的时候就打算写这篇文章,可是还是參加阿里大数据竞赛的第一季三月份的时候实验就完毕了.硬生生是拖到了十一假期.自己也是醉了... 找工作不是非常顺利,希望写点东西回想一下知识.然后再攒点人品吧,仅仅 ...
- 基于协同过滤的个性化Web推荐
下面这是论文笔记,其实主要是摘抄,这片博士论文很有逻辑性,层层深入,所以笔者保留的比较多. 看到第二章,我发现其实这片文章对我来说更多是科普,科普吧…… 一.论文来源 Personalized Web ...
- 用Maven构建Mahout项目实现协同过滤userCF--单机版
本文来自:http://blog.fens.me/hadoop-mahout-maven-eclipse/ 前言 基于Hadoop的项目,不管是MapReduce开发,还是Mahout的开发都是在一个 ...
- 推荐系统-协同过滤在Spark中的实现
作者:vivo 互联网服务器团队-Tang Shutao 现如今推荐无处不在,例如抖音.淘宝.京东App均能见到推荐系统的身影,其背后涉及许多的技术.本文以经典的协同过滤为切入点,重点介绍了被工业界广 ...
- 电影推荐系统---协同过滤算法(SVD,NMF)
SVD 参考 https://www.zybuluo.com/rianusr/note/1195225 1 推荐系统概述 1.1 项目安排 1.2 三大协同过滤 1.3 项目开发工具 ...
随机推荐
- Virtualbox Ubuntu 虚拟机命令行挂载共享文件夹及设置静态IP
挂载共享文件夹 参考 [1], VirtualBox/GuestAdditions [2], VirtualBox/SharedFolders 步骤 在Virtualbox 虚拟机的菜单『设备』中,点 ...
- Ubantu更新hostname & hosts
一.概述 Hostname 即主机名,一般存放在 /etc/hostname 中.而hosts则是本地域名解析文件,存放于 /etc/hosts. 二.测试 2.1 hostname musion@m ...
- Spring Cloud配置中心搭建(集成Git)
1. 在Github(或其他)创建配置中心仓库bounter-config-repo,然后在仓库创建两个配置文件:simon.properties.susan.properties,链接如下: htt ...
- Union 与 Union all 的区别【坑】
UNION操作符用于合并两个或多个SELECT语句的结果集 请注意,UNION 内部的 SELECT 语句必须拥有相同数量的列.列也必须拥有相似的数据类型.同时,每条 SELECT 语句中的列的顺序必 ...
- phpredis扩展实现LBS距离计算和范围筛选
来源 public function geo(){ $redis = new \redis(); $redis -> connect('127.0.0.1',6379); //位置增加 $res ...
- python学习记录20190121
print 语句默认会给每一行添加一个换行符.只要在print 语句的最后添加一个逗号(,),就可以改变它这种行为 带逗号的print语句输出的元素之间会自动添加一个空格 print 没有任何参数的p ...
- Web前端-网站首页和注册界面的实现
首页用到的知识如下: 1.bootstrap框架 2.jQuerry实现页面定时弹出广告 注册界面用到的知识: 1.bootstrap框架 2.jQuerry实现省市联动操作 3.jQuerry实现表 ...
- bzoj 3697
题目描述:这里 发现还是点对之间的问题,于是还是上点分 只不过是怎么做的问题 首先对每条边边权给成1和-1(即把原来边权为0的边边权改为-1),那么合法的路径总权值一定为0! 还是将路径分为经过当前根 ...
- OPPO F9 Pro在哪里打开usb调试模式的完美方法
经常我们使用pc通过数据线连接到安卓手机的时候,如果手机没有开启USB调试模式,pc则没能够成功读到我们的手机,此情况我们需要找处理方法将手机的USB调试模式开启,今天我们介绍OPPO F9 Pro如 ...
- [原创]免固件开发USB2.0 FPGA方案 速度40Mbyte/s+
USB 2.0接口,实测速度40Mbyte/s: 一个接口实现两种功能(USB2.0+FPGA配置): 免固件开发: 完整的FPGA代码,即拿即用: FPGA逻辑工程师开发USB接口福音: 平台可移植 ...