【Python】Scrapy基础
一、Scrapy 架构
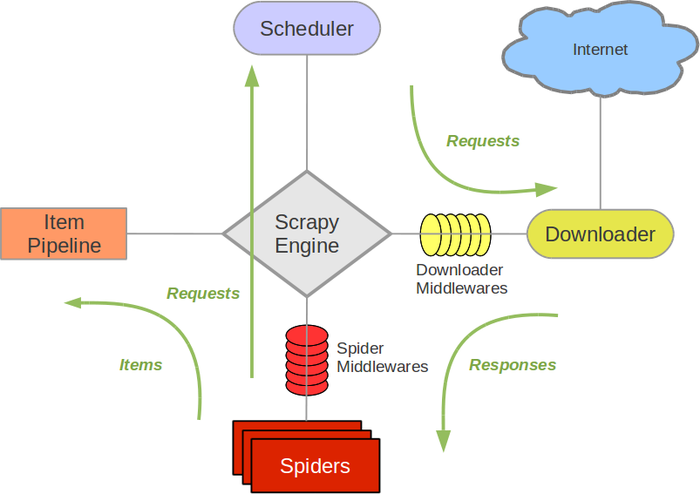
- Engine(引擎):负责 Spider(爬虫)、Item Pipeline(管道)、Downloader(下载器)、Scheduler(调度器)中的通讯和数据传递。
- Scheduler:接受 Engine 发送过来的 Request 请求,按照一定方式入队,再交给 Downloader 下载。可实现去重。Scheduler 的请求队列为空时,程序才会终止。
- Downloader:下载 Engine 发送(中间通过Scheduler)的所有 Requests 请求,并将其获取到的 Responses 交还给 Engine,由 Engine 交给 Spider 处理。
- Spider:处理所有 Responses ①提取 Item 字段需要的数据,交给 Pipeline 存储 ②将需要跟进的 URL 提交给 Engine,再进入 Scheduler。
- Item Pipeline:负责处理 Spider 提取到的 Item,并进行后期处理,例如分析过滤数据,按自己定制的格式保存到 json、数据库等。
- Downloader Middlewares:自定义扩展下载功能,例如给每个 Request 加代理、User-Agent 等。
- Spider Middlewares:自定义扩展 Engine 和 Spider 中间的通信,例如进入 Spider 的 Responses、从 Spider 出去的Requests。用处不大,大部分爬虫功能在 Spider 里实现。
二、Scrapy 安装
1、Windows
- pip install scrapy
2、Linux
- 安装非 python 依赖:sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
- sudo pip install scrapy
三、官方文档
四、
【Python】Scrapy基础的更多相关文章
- python scrapy 基础
scrapy是用python写的一个库,使用它可以方便的抓取网页. 主页地址http://scrapy.org/ 文档 http://doc.scrapy.org/en/latest/index.ht ...
- 0.Python 爬虫之Scrapy入门实践指南(Scrapy基础知识)
目录 0.0.Scrapy基础 0.1.Scrapy 框架图 0.2.Scrapy主要包括了以下组件: 0.3.Scrapy简单示例如下: 0.4.Scrapy运行流程如下: 0.5.还有什么? 0. ...
- python scrapy 抓取脚本之家文章(scrapy 入门使用简介)
老早之前就听说过python的scrapy.这是一个分布式爬虫的框架,可以让你轻松写出高性能的分布式异步爬虫.使用框架的最大好处当然就是不同重复造轮子了,因为有很多东西框架当中都有了,直接拿过来使用就 ...
- Python——Scrapy初学
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架.可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中.Scrapy最初是为了页面抓取(更确切来说, 网络抓取)所设计的,也 ...
- python scrapy版 极客学院爬虫V2
python scrapy版 极客学院爬虫V2 1 基本技术 使用scrapy 2 这个爬虫的难点是 Request中的headers和cookies 尝试过好多次才成功(模拟登录),否则只能抓免费课 ...
- python Scrapy安装和介绍
python Scrapy安装和介绍 Windows7下安装1.执行easy_install Scrapy Centos6.5下安装 1.库文件安装yum install libxslt-devel ...
- Python.Scrapy.14-scrapy-source-code-analysis-part-4
Scrapy 源代码分析系列-4 scrapy.commands 子包 子包scrapy.commands定义了在命令scrapy中使用的子命令(subcommand): bench, check, ...
- Python.Scrapy.11-scrapy-source-code-analysis-part-1
Scrapy 源代码分析系列-1 spider, spidermanager, crawler, cmdline, command 分析的源代码版本是0.24.6, url: https://gith ...
- Python文件基础
===========Python文件基础========= 写,先写在了IO buffer了,所以要及时保存 关闭.关闭会自动保存. file.close() 读取全部文件内容用read,读取一行用 ...
- python scrapy cannot import name xmlrpc_client的解决方案,解决办法
安装scrapy的时候遇到如下错误的解决办法: "python scrapy cannot import name xmlrpc_client" 先执行 sudo pip unin ...
随机推荐
- Python strip()与lstrip()、rstrip()
.strip()方法可以根据条件遍历字符串中的字符并一一去除 默认去除字符串中的头尾空格 “ Alins ”.“ AA BB CC ”用了之后就是 “Alins”.“AA BB CC” ...
- 小程序 components 下的组件引入字体图标时样式不生效
在组件内的样式在引入一遍 字体图标样式, pages 下的组件不受影响,全局引入字体图标样式即刻,不需要再次引入
- Numpy 和 Matplotlib库的学习笔记
Numpy介绍 一个用python实现的科学计算,包括:1.一个强大的N维数组对象Array:2.比较成熟的(广播)函数库:3.用于整合C/C++和Fortran代码的工具包:4.实用的线性代数.傅里 ...
- springboot整合mybatis(使用MyBatis Generator)
引入依赖 <dependencies> <dependency> <groupId>org.springframework.boot</groupId> ...
- 【shell】awk按域去除重复行
首先解释一下什么叫“按域去除重复行”: 有的时候我们需要去除的重复行并不是整行都重复,两行的其中一列的元素相同我们有的时候就需要认定这两行重复,因此有了今天的内容. 去除重复行shell有一个原生命令 ...
- CSS3@media媒体查询
CSS3@media媒体查询 定义 media媒体查询, 当文档宽度变化时, 就可以根据文档宽度的变化来运用样式,不同的宽度应用不同的样式 使用 @media 查询,你可以针对不同的媒体类型定义不同的 ...
- Client does not support authentication
Navicat 11 连MySQL 8.0.16 报 Client does not support authentication........ 解决: alter user 'fabu'@'%' ...
- 2600 Phrases for Effective Performance Reviews
Adaptability and Change Management Skills 适应与变革管理技能能够接受频繁的任务转换.员工适应经常在不停的切换于不同的任务中,就是正常的,就是能够正常切换自己分 ...
- VMware下liunx虚拟机仅主机模式上网
VMware上的配置 虚拟网络编辑器上的仅主机模式设置 可以自定义虚拟机的网段,我设置的是192.168.137.0 选择对应网卡的联网方式为仅主机模式 配置虚拟机网卡,主要是按虚拟网卡编辑器中设置的 ...
- C#线程同步(2)- 临界区&Monitor
文章原始出处 http://xxinside.blogbus.com/logs/46740731.html 预备知识:C#线程同步(1)- 临界区&Lock 监视器(Monitor)的概念 可 ...