sql多行多列重复
在sql的查询中我们会遇到查询的结果比如这样的:
查询这张表的sql语句:
select r.ROLE_NAME,u.USERID,u.USERNAME,u.TrueName from BASE_USERINFOR u left join BASE_USERROLE ur on u.USERID=ur.USER_ID
left join BASE_ROLEINFOR r on r.ROLE_ID=ur.ROLE_ID
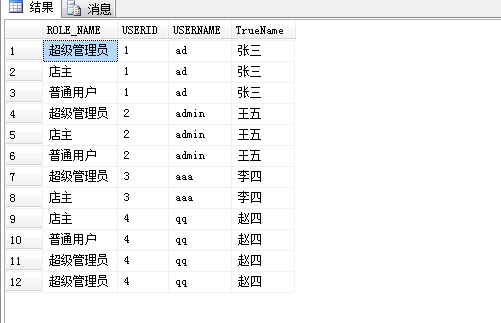
就拿钱三行来说就一个ROLE_NAME不一样其他的列的数值都是一样的难道我们就要这样的结果,就算我们要这样的结果但是当我们想要在前台这样显示一个页面的时候我们怎么办
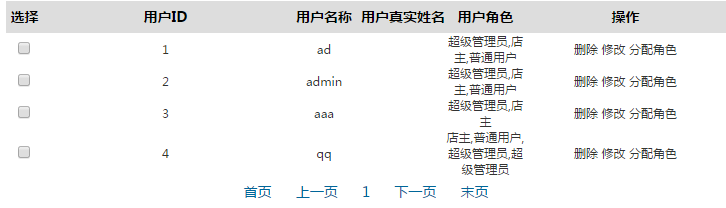
这样的话我们该怎么去查询该怎么组合,把它分开来查询当然也能解决,但是想想那样我们要查询多少次要连接数据库对少次。
这样想想就觉得很麻烦当然想想也知道这样做肯定是降低了程序的执行效率。所以我们就应该想另一种方法怎样查询一次就可以变成这种效果。
想想看我们查询的结果是一张表那我们就看这张表的XML文件的组成是什么样的
查看表的组成的XML文件的sql语句:
select * from (select r.ROLE_NAME,u.USERID,u.USERNAME,u.TrueName from BASE_USERINFOR u left join BASE_USERROLE ur on u.USERID=ur.USER_ID
left join BASE_ROLEINFOR r on r.ROLE_ID=ur.ROLE_ID) t for XML path
查出表的XML文件的组成
想想看如果我们可以替换XML文件的组成的话我们是不是就可以改变表的结构了
我们先看一个简单的表,多行的重复是怎么合并的
select * from table1
查询结果:

看看这样的一个简单的表我们是怎样合并相同的列的
第一步:当然是查看表的XML文件看看表是怎样组成的
select * from table1 for XML path;
查询的结果:
<row>
<uid>1</uid>
<rname>管理员</rname>
</row>
<row>
<uid>1</uid>
<rname>店主</rname>
</row>
<row>
<uid>1</uid>
<rname>买家</rname>
</row>
<row>
<uid>2</uid>
<rname>店主</rname>
</row>
<row>
<uid>2</uid>
<rname>店主</rname>
</row>
根据查询的结果我们不难看出表的组成的简单结构,可能是数据库自己定义好的也可能是我们在查询的时候自动生成的,不管是定义好的还是自己生成的我们先看看是否可以改变表的组成结构如果可以的话我们是不是就可以改变我们想要的结构呢?
第二步:改变表的组成结构
select * from table1 for XML path;
还是这句语句既然可以查询表的XML文件组成那是否可以改变表的XML文件的组成呢。试试就知道了(程序就是你想的再多不如你敲几行代码一试)
select * from table1 for XML path('a');
我们这样写语句看看我们的表的XML文件的组成变成了什么样:
<a>
<uid>1</uid>
<rname>管理员</rname>
</a>
<a>
<uid>1</uid>
<rname>店主</rname>
</a>
<a>
<uid>1</uid>
<rname>买家</rname>
</a>
<a>
<uid>2</uid>
<rname>店主</rname>
</a>
<a>
<uid>2</uid>
<rname>店主</rname>
</a>
比较两次的查询结果看看我们的表的XML文件发生了什么变化:
select * from table1 for XML path; XML文件:
<row>
<uid>1</uid>
<rname>管理员</rname>
</row> select * from table1 for XML path('a'); XML文件的组成:
<a>
<uid>1</uid>
<rname>管理员</rname>
</a>
可以产出<row>标签变成了<a>,那么我们把path('a')中的a去掉会变成什么样:
查询语句:
select * from table1 for XML path('');
查询结果:
<uid>1</uid>
<rname>管理员</rname>
<uid>1</uid>
<rname>店主</rname>
<uid>1</uid>
<rname>买家</rname>
<uid>2</uid>
<rname>店主</rname>
<uid>2</uid>
<rname>店主</rname>
比较两次的查询结果:
select * from table1 for XML path('a');
查询结果:
<a>
<uid>1</uid>
<rname>管理员</rname>
</a>
select * from table1 for XML path('');
查询结果:
<uid>1</uid>
<rname>管理员</rname>
可以看出<a>去掉了,我们想要的是什么是用户的角色那我们就要角色看看:
第三步:去掉多余的行
select rname from table1 for XML path('');
查询的结果:
<rname>管理员</rname>
<rname>店主</rname>
<rname>买家</rname>
<rname>店主</rname>
<rname>店主</rname>
当然这仍然不是我们想要的结果我们想要的里面的数据,所以我们需要去掉<rname>标签:
第四步:去掉不要的标签:
select rname+',' from table1 for XML path('');
查询的结果:
管理员,店主,买家,店主,店主,
这就是我们想要的结果了,结果是拿到了但是我们想要的是什么效果啊,先看看我们们想要的表是什么样的

这是我们想要的表,但是怎么组成呢?
再看看我们原来的表:

想想看我们应该把这张表变形:
uid是多行的那我们就先不看rname这一列,我们先进行分组:
第五步:分组
根据uId进行分组
select uid from table1 group by uid
结果:

好,最重要的一步来了:
我们怎么把管理员,店主,买家,放在对应uid为1的一行,怎么把店主,店主,放在对应的uid为2的一行后面
第六步:合并:
也就是在这个表的后面添加一列。这样就简单了
select uid,(这一列就是rname)from table1 t group by uid;
那我们就增加一列:
上面我们的查询时查询所有的列现在我们加上条件:
select rname+',' from table1 t1 where t1.uid=1 for XML path('');
查询结果:
管理员,店主,买家,
这不就是我们想要的嘛,只要把条件改变一下就可以了嘛,现在我们进行合并也就是增加一列。
select uid,(这一列就是rname)from table1 t group by uid;
增加rname这一列:
select uid,(select rname+',' from table1 t1 where t1.uid=t.uid for XML path('')) as rname from table1 t group by uid;
我们看看这个语句的查询结果是什么?
select uid,(select rname+',' from table1 t1 where t1.uid=t.uid for XML path('')) as rolenames from table1 t group by uid;
结果:

这就是我们想要的结果了。
好了简单表的组成会了我们来点复杂的
继续完成我们刚开始提出的问题:
合成这张表试试看
查询语句:
select r.ROLE_NAME,u.USERID,u.USERNAME,u.TrueName from BASE_USERINFOR u left join BASE_USERROLE ur on u.USERID=ur.USER_ID
left join BASE_ROLEINFOR r on r.ROLE_ID=ur.ROLE_ID

我们该怎么合并这张表呢。仔细想想看其实道理是一样的我们直接把这张表当让是table1表,在往刚刚的sql语句一套不就行了
看看刚才的sql语句:
select uid,(select rname+',' from table1 t1 where t1.uid=t.uid for XML path('')) as rolenames from table1 t group by uid;
看看哪里用到了table1我们改变一下就行了
select uid,(select rname+',' from (table1表) t1 where t1.uid=t.uid for XML path('')) as rolenames from (table1表) t group by uid;
再根据我们的表看一看也就是改变一下查询的列的问题:
我们改变一下
select USERID,(select t.ROLE_NAME+',' from (table1表))t where t.USERID=t1.USERID for XML path('')) as RoleName from(table1表)t1 group by USERID,TrueName,USERNAME
好了把我们的“table1表”放进去,执行一下看看什么结果
select USERID,(select t.ROLE_NAME+',' from
(select r.ROLE_NAME,u.USERID,u.USERNAME,u.TrueName from BASE_USERINFOR u
left join BASE_USERROLE ur on u.USERID=ur.USER_ID
left join BASE_ROLEINFOR r on r.ROLE_ID=ur.ROLE_ID) t where t.USERID=t1.USERID for XML path('')) as RoleName from
(select r.ROLE_NAME,u.USERID,u.USERNAME,u.TrueName from BASE_USERINFOR u
left join BASE_USERROLE ur on u.USERID=ur.USER_ID
left join BASE_ROLEINFOR r on r.ROLE_ID=ur.ROLE_ID) t1 group by USERID
查询结果:

可是跟上面的表比较一下我们的表少了几列所以我们要把少的几列加上:
select USERID,TrueName,USERNAME,(select t.ROLE_NAME+',' from
(select r.ROLE_NAME,u.USERID,u.USERNAME,u.TrueName from BASE_USERINFOR u
left join BASE_USERROLE ur on u.USERID=ur.USER_ID
left join BASE_ROLEINFOR r on r.ROLE_ID=ur.ROLE_ID) t where t.USERID=t1.USERID for XML path('')) as RoleName from
(select r.ROLE_NAME,u.USERID,u.USERNAME,u.TrueName from BASE_USERINFOR u
left join BASE_USERROLE ur on u.USERID=ur.USER_ID
left join BASE_ROLEINFOR r on r.ROLE_ID=ur.ROLE_ID) t1 group by USERID,TrueName,USERNAME
看看查询的结果是不是我们想要的

在这里一定要注意一下group by 后面的语句,虽然我们写那么多的分组条件就只是第一个条件及作用我们仍然要写因为只有这样我们在查询的时候才可以去查询想要的列。
所以当你想要的查询其他的列的时候你就需要在group by 后面加上此列。
sql多行多列重复的更多相关文章
- sql的行转列(PIVOT)与列转行(UNPIVOT) webapi 跨域问题 Dapper 链式查询 扩展 T4 代码生成 Demo (抽奖程序)
sql的行转列(PIVOT)与列转行(UNPIVOT) 在做数据统计的时候,行转列,列转行是经常碰到的问题.case when方式太麻烦了,而且可扩展性不强,可以使用 PIVOT,UNPIVOT比 ...
- Sql Server 行转列
--摘自百度 PIVOT用于将列值旋转为列名(即行转列),在SQL Server 2000可以用聚合函数配合CASE语句实现 PIVOT的一般语法是:PIVOT(聚合函数(列) FOR 列 in (… ...
- sql的行转列(PIVOT)与列转行(UNPIVOT)
在做数据统计的时候,行转列,列转行是经常碰到的问题.case when方式太麻烦了,而且可扩展性不强,可以使用 PIVOT,UNPIVOT比较快速实现行转列,列转行,而且可扩展性强 一.行转列 1.测 ...
- 做图表统计你需要掌握SQL Server 行转列和列转行
说在前面 做一个数据统计和分析的项目,每天面对着各种数据,经过存储过程从源表计算汇总后需要写入中间结果表以提高数据使用效率,那么此时就需要用到行转列和列转行. 1.列转行 数据经过计算加工后会直接生成 ...
- SQL Server 行转列重温
转载自http://www.cnblogs.com/kerrycode/ 行转列,列转行是我们在开发过程中经常碰到的问题.行转列一般通过CASE WHEN 语句来实现,也可以通过 SQL SERVER ...
- sql server 行转列(转载)
SQL Server中行列转换 Pivot UnPivot PIVOT用于将列值旋转为列名(即行转列),在SQL Server 2000可以用聚合函数配合CASE语句实现 PIVOT的一般语法是:PI ...
- sql server 行转列解决方案
主要应用case语句来解决行转列的问题 行转列问题主要分为两类 1)简单的行转列问题: 示例表: id sid course result 1 2005001 语文 ...
- sql server 行转列 Pivot UnPivot
SQL Server中行列转换 Pivot UnPivot 本文转自:张志涛 原文地址: http://www.cnblogs.com/zhangzt/archive/2010/07/29/17878 ...
- 【转载】SQL Server行转列,列转行
行转列,列转行是我们在开发过程中经常碰到的问题.行转列一般通过CASE WHEN 语句来实现,也可以通过 SQL SERVER 2005 新增的运算符PIVOT来实现.用传统的方法,比较好理解.层次清 ...
随机推荐
- 2018-2019-1 20189201《Linux内核原理与分析》第三周作业
写作业之前,写了时光博物馆参观感受.1978-2018 40年的改革开放历程. 一.C语言中内嵌汇编语言的写法 内嵌汇编的语法如下: asm volatile ( 汇编语句模版: 输出部分: 输入部分 ...
- C# 接口属性的定义&get、set访问器的简单应用
using System; using System.Collections.Generic; using System.Linq; using System.Text; namespace 接口 ...
- 动态规划——Best Time to Buy and Sell Stock III
题意:用一个数组表示股票每天的价格,数组的第i个数表示股票在第i天的价格. 如果最多进行两次交易,但必须在买进一只股票前清空手中的股票,求最大的收益. 示例 1:Input: [3,3,5,0,0,3 ...
- MyBatis(三)MyBatis的增删改查
(1)接口中编写方法 public Emp getEmp(Integer id); public void addEmp(Emp emp); public void deleteEmp(Integer ...
- js的一些
// 1 定时器参数问题 无限个参数 /*setTimeout(function(num1,num2,num3,num4){ alert(num1+num2+num3+num4) },1000,1,2 ...
- Node.js_ express.Router 路由器_模块化管理路由
路由器 express.Router 路由器 模块化管理 路由 基本使用: 路由模块 1. 引入 express const express = require('express'); 其他相关模块 ...
- nginx/php的redis模块扩展
redis模块介绍 redis2-nginx-module 可以实现 Nginx 以非阻塞方式直接防问远方的 Redis 服务,可以启用强大的 Redis 连接池功能,进而实现更多的连接与更快速的访问 ...
- ajax 传递中文字符参数 问题
使用ajax 传递中文字符串时, 服务端会接收不到预期的 中文字符. 此时,需要对 js中的中文字符参数进行 编码, 到达服务端后, 再为其解码 即可. 前端: var url = '....'; ...
- linux下压缩解压缩命令
zip/gzip 命令 linux zip命令参数列表: -a 将文件转成ASCII模式 -F 尝试修复损坏的压缩文件 -h 显示帮助界面 -m 将文件压缩之后,删除源文件 -n 特定字符串 ...
- 洛谷P1115 最大字段和【线性dp】
题目:https://www.luogu.org/problemnew/show/P1115 题意: 求给定数组的最大区间和. 思路: $dp[i][0]$表示以1~i的数组,不选i的最大字段和.$d ...