论文阅读《ActiveStereoNet:End-to-End Self-Supervised Learning for Active Stereo Systems》
本文出自谷歌与普林斯顿大学研究人员之手并发表于计算机视觉顶会ECCV2018。本文首次提出了应用于主动双目立体视觉的深度学习解决方案,并引入了一种新的重构误差,采用自监督的方法来解决缺少ground truth数据的问题,本文所提供的方法在许多方面表现出了最好的结果
Abstract
本文首次提出了第一个主动双目视觉系统的深度学习解决方案 ActiveStereoNet。由于缺乏 ground truth,本文采用了完全自监督的方法,即使如此,本方法也产生了 1/30 亚像素精度的深度数据。它克服了过度平滑的问题,保留了边缘,并且能有效处理遮挡。在本文中,引入了一种对噪声,无纹理区域和光照更加鲁棒的新的重建损失,它使用基于窗口的自适应支持权重的成本聚合来进行优化。这种成本聚合函数能够保留边缘并且使损失函数平滑,是使模型达到惊人结果的关键。最后,本文展示了如何在没有ground truth下对无效的区域,遮挡区域的预测进行end-to-end的训练。这部分对减少模糊和改善预测数据的连续性至关重要。
Introduction
深度传感器(Depth sensors)为许多难题提供了额外的3D信息,如非刚性重构(non-rigid reconstruction)、动作识别和参数跟踪,从而给计算机视觉带来了革新。虽然深度传感器技术有许多类型,但它们都有明显的局限性。例如,飞行时间系统(Time of flight systems)容易遭受运动伪影和多路径的干扰,结构光(structured light )容易受到环境光照和多设备干扰。在没有纹理的区域,需要昂贵的全局优化技术,特别是在传统的非学习方法中,passive stereo很难实现。
主动双目立体视觉(Active stereo)提供了一种潜在的解决方案:使用一对红外立体相机,使用一个伪随机模式,通过图案化的红外光源对场景进行纹理化(如图1所示)。通过合理选择传感波长,相机对捕获主动照明和被动光线的组合,提高了结构光的质量,同时在室内和室外场景中提供了强大的解决方案。虽然这项技术几十年前就提出了,但直到最近才出现在商业产品中。因此,从主动双目立体图像中推断深度的先前工作相对较少,并且尚未获得大规模的ground truth训练数据。
在主动双目立体成像系统中必须解决几个问题。有些问题是所有的双目系统问题共有的,例如,必须避免匹配被遮挡的像素,这会导致过度平滑、边缘变厚和/或轮廓边缘附近出现飞行像素。但是,其他一些问题是主动双目系统特有的,例如,它必须处理非常高分辨率的图像来匹配投影仪产生的高频模式;它必须避免由于这些高频模式的其他排列而产生的许多局部最小值;而且它还必须补偿附近和远处表面投影图案之间的亮度差异。此外,它不能接受ground truth深度的大型主动双目数据集的监督,因为没有可用的数据。
在这篇论文中,我们第一个提出了针对主动立体视觉系统的端到端深度学习方案。首先,本文提出了一种基于局部对比度归一化(local contrast normalization)的新的重建损耗,其从被动IR图像中去除低频分量并且局部地重新校准有源图像的强度以解决有源立体视觉系统中能量随距离的衰落的问题。 第二,我们提出了一种基于窗口的损耗聚合,其中每个像素具有自适应权重,以增加其可辨识性并降低立体对成本函数中局部最小值的影响。 最后,我们检测图像中的遮挡像素,并从损失计算中忽略它们。 这些新特性为训练期间的提高了收敛速度,并在测试时提高了预测的精度。大量实验表明,我们使用这些想法进行训练的网络优于以往有关主动立体匹配的研究。
Method
现在来介绍ActiveStereoNet的网络结构和主要训练过程。算法的输入是一对矫正过的同步采集的IR图像, 输出是一对同原始分辨率的视差图像。在本实验中采用1280*720的图像。相机的焦距和两个相机间的基线假设已知。因此,深度的预测问题转化为了同一扫描线上的视差问题。给定视差 ,则深度是Z=bf/d。因为缺乏ground truth数据,本算的主要挑战是在没有直接监督的情况下,训练一个对遮挡和光照变化鲁棒的端对端网络。下面是算法细节:
Network Architecture
现在,在大部分视觉任务中,网络结构的选择和设计是最重要的,需要花费大量的精力。但是在本文中,最重要的问题是训练一个给定的网络结构,特别是,因为是无监督的网络,设计一个好的损失函数对总体的精度影响最大。因此,在本文中采用了谷歌另一篇论文 StereoNet 的网络结构,这个结构在被动的双目视觉系统中有很好的表现。而且,该结构在高配GPU下能对全分辨图像做到60HZ, 能达到实时性的要求。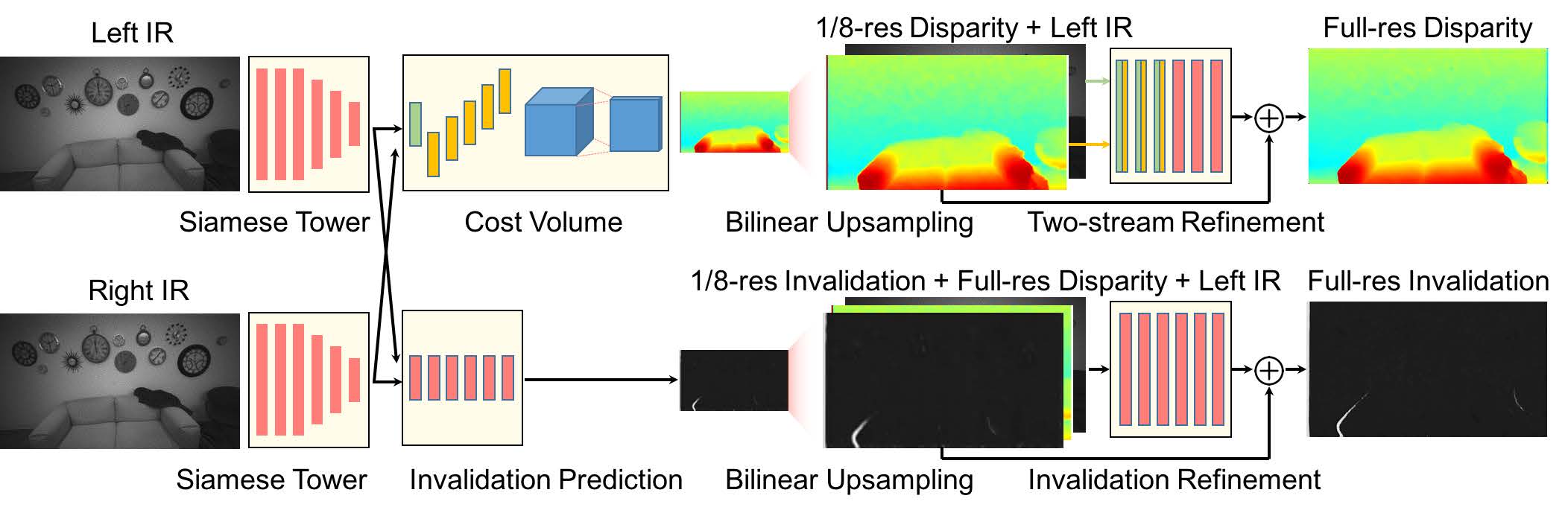
---------------------
作者:古安
来源:CSDN
原文:https://blog.csdn.net/goodanchor/article/details/81557631
版权声明:本文为博主原创文章,转载请附上博文链接!
论文阅读《ActiveStereoNet:End-to-End Self-Supervised Learning for Active Stereo Systems》的更多相关文章
- 《Deep Learning of Graph Matching》论文阅读
1. 论文概述 论文首次将深度学习同图匹配(Graph matching)结合,设计了end-to-end网络去学习图匹配过程. 1.1 网络学习的目标(输出) 是两个图(Graph)之间的相似度矩阵 ...
- Deep Learning of Graph Matching 阅读笔记
Deep Learning of Graph Matching 阅读笔记 CVPR2018的一篇文章,主要提出了一种利用深度神经网络实现端到端图匹配(Graph Matching)的方法. 该篇文章理 ...
- Deep Reinforcement Learning for Dialogue Generation 论文阅读
本文来自李纪为博士的论文 Deep Reinforcement Learning for Dialogue Generation. 1,概述 当前在闲聊机器人中的主要技术框架都是seq2seq模型.但 ...
- Deep Learning 33:读论文“Densely Connected Convolutional Networks”-------DenseNet 简单理解
一.读前说明 1.论文"Densely Connected Convolutional Networks"是现在为止效果最好的CNN架构,比Resnet还好,有必要学习一下它为什么 ...
- Deep Learning 26:读论文“Maxout Networks”——ICML 2013
论文Maxout Networks实际上非常简单,只是发现一种新的激活函数(叫maxout)而已,跟relu有点类似,relu使用的max(x,0)是对每个通道的特征图的每一个单元执行的与0比较最大化 ...
- Discriminative Learning of Deep Convolutional Feature Point Descriptors 论文阅读笔记
介绍 该文提出一种基于深度学习的特征描述方法,并且对尺度变化.图像旋转.透射变换.非刚性变形.光照变化等具有很好的鲁棒性.该算法的整体思想并不复杂,使用孪生网络从图块中提取特征信息(得到一个128维的 ...
- Sequence to Sequence Learning with Neural Networks论文阅读
论文下载 作者(三位Google大佬)一开始提出DNN的缺点,DNN不能用于将序列映射到序列.此论文以机器翻译为例,核心模型是长短期记忆神经网络(LSTM),首先通过一个多层的LSTM将输入的语言序列 ...
- Deep Learning 24:读论文“Batch-normalized Maxout Network in Network”——mnist错误率为0.24%
读本篇论文“Batch-normalized Maxout Network in Network”的原因在它的mnist错误率为0.24%,世界排名第4.并且代码是用matlab写的,本人还没装caf ...
- Deep Learning 25:读论文“Network in Network”——ICLR 2014
论文Network in network (ICLR 2014)是对传统CNN的改进,传统的CNN就交替的卷积层和池化层的叠加,其中卷积层就是把上一层的输出与卷积核(即滤波器)卷积,是线性变换,然后再 ...
- Deep Learning 28:读论文“Multi Column Deep Neural Network for Traffic Sign Classification”-------MCDNN 简单理解
读这篇论文“ Multi Column Deep Neural Network for Traffic Sign Classification”是为了更加理解,论文“Multi-column Deep ...
随机推荐
- eclipse debug的时候提示debug Edit Source Lookup path
原因可能是代码资源包未加载到debug的路径中,解决方法如下: Debug 视图下 ->在调试的线程上 右键单击 ->选择Edit Source Lookup Path ->选择Ad ...
- vscode快捷键(lua开发)
快速定位行:ctrl+g 查找:ctrl+f 格式化代码:ctrl+alt+f 快速查找到当前复制内容的第一次出现的位置ctrl+d 其他常用不一一列举了
- 简洁又快速地处理集合——Java8 Stream(上)
Java 8 发布至今也已经好几年过去,如今 Java 也已经向 11 迈去,但是 Java 8 作出的改变可以说是革命性的,影响足够深远,学习 Java 8 应该是 Java 开发者的必修课. 今天 ...
- Flash的选择
算起来自己接触Flash接近4年了. 最開始的2.0,做button,做动画,做导航. 后来用3.0做动画,做相冊.做毕业设计,做课件. 然后到公司做2.0的动画,模板开发,效果设计. 似乎又回到了原 ...
- 6 Javascript:函数
函数 函数是面向任务的. 当我们面临一个须要可问题的时候.往往无处下手.这时候.须要将问题分解为多个任务,从而逐一击破. 这里就须要函数的帮助. 语法 function Name() { Body() ...
- 精简Linux文件路径
精简Linux的文件路径: ..回退的功能 .留在当前文件夹 //仅仅保留一个/ abc/..要返回. 报错 删除最后一个/ 主要思路: 用栈记录路径的起始位置,讨论/后的不同情况就可以: #incl ...
- [Phonegap+Sencha Touch] 移动开发19 某些安卓手机上弹出消息框 点击后不消失的解决的方法
Ext.Msg.alert等弹出框在某些安卓手机上,点击确定后不消失. 原因是: 消息框点击确定后有一段css3 transform动画,动画完毕后才会隐藏(display:none). 有些奇葩手机 ...
- Rails中关联数据表的添加操作(嵌套表单)
很早就听说有Web敏捷开发这回事,最近终于闲了下来,可以利用业余的时间学些新东西,入眼的第一个东东自然是Ruby on Rails.Rails中的核心要素也就是MVC.ORM这些了,因此关于Rails ...
- [BZOJ 3365] Distance Statistics
[题目链接] https://www.lydsy.com/JudgeOnline/problem.php?id=3365 [算法] 点分治 [代码] #include <algorithm> ...
- 18. 4Sum[M]四数之和
题目 Given an array nums of n integers and an integer target, are there elements a, b, c and d in nums ...