Sqoop Import HDFS
Sqoop import应用场景——密码访问
注:测试用表为本地数据库中的表
1.明码访问
sqoop list-databases \
--connect jdbc:mysql://202.193.60.117/dataweb \
--username root \
--password
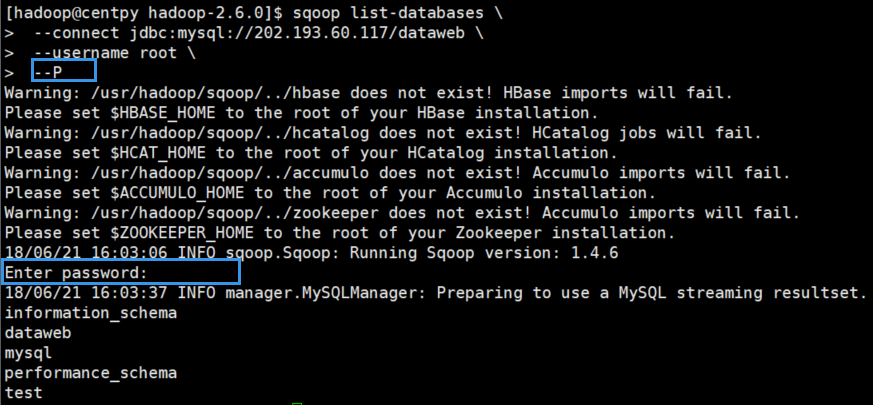
2.交互式密码
sqoop list-databases \
--connect jdbc:mysql://202.193.60.117/dataweb \
--username root \
--P
3.文件授权密码
sqoop list-databases \
--connect jdbc:mysql://202.193.60.117/dataweb \
--username root \
--password-file /usr/hadoop/.password
在运行之前先要在指定路径下创建.password文件。
[hadoop@centpy ~]$ cd /usr/hadoop/
[hadoop@centpy hadoop]$ ls
flume hadoop-2.6. sqoop
[hadoop@centpy hadoop]$ echo -n "20134997" > .password
[hadoop@centpy hadoop]$ ls -a
. .. flume hadoop-2.6. .password sqoop
[hadoop@centpy hadoop]$ more .password [hadoop@centpy hadoop]$ chmod 400 .password //根据官方文档说明赋予400权限
测试运行之后一定会报以下错误:
// :: WARN tool.BaseSqoopTool: Failed to load password file
java.io.IOException: The provided password file /usr/hadoop/.password does not exist!
at org.apache.sqoop.util.password.FilePasswordLoader.verifyPath(FilePasswordLoader.java:)
at org.apache.sqoop.util.password.FilePasswordLoader.loadPassword(FilePasswordLoader.java:)
at org.apache.sqoop.util.CredentialsUtil.fetchPasswordFromLoader(CredentialsUtil.java:)
at org.apache.sqoop.util.CredentialsUtil.fetchPassword(CredentialsUtil.java:)
at org.apache.sqoop.tool.BaseSqoopTool.applyCredentialsOptions(BaseSqoopTool.java:)
at org.apache.sqoop.tool.BaseSqoopTool.applyCommonOptions(BaseSqoopTool.java:)
at org.apache.sqoop.tool.ListDatabasesTool.applyOptions(ListDatabasesTool.java:)
at org.apache.sqoop.tool.SqoopTool.parseArguments(SqoopTool.java:)
at org.apache.sqoop.Sqoop.run(Sqoop.java:)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:)
at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:)
at org.apache.sqoop.Sqoop.main(Sqoop.java:)
Error while loading password file: The provided password file /usr/hadoop/.password does not exist!
为了解决该错误,我们需要将.password文件放到HDFS上面去,这样就能找到该文件了。
[hadoop@centpy hadoop]$ hdfs dfs -ls /
Found items
drwxr-xr-x - Zimo supergroup -- : /actor
drwxr-xr-x - Zimo supergroup -- : /counter
drwxr-xr-x - hadoop supergroup -- : /flume
drwxr-xr-x - hadoop hadoop -- : /hdfsOutput
drwxr-xr-x - Zimo supergroup -- : /join
drwxr-xr-x - hadoop supergroup -- : /maven
drwxr-xr-x - Zimo supergroup -- : /mergeSmallFiles
drwxrwxrwx - hadoop supergroup -- : /phone
drwxr-xr-x - hadoop hadoop -- : /test
drwx------ - hadoop hadoop -- : /tmp
drwxr-xr-x - hadoop hadoop -- : /weather
drwxr-xr-x - hadoop hadoop -- : /weibo
[hadoop@centpy hadoop]$ hdfs dfs -mkdir -p /user/hadoop
[hadoop@centpy hadoop]$ hdfs dfs -put .password /user/hadoop
[hadoop@centpy hadoop]$ hdfs dfs -chmod 400 /user/hadoop/.password
现在测试运行一下,注意路径改为HDFS上的/user/hadoop。
[hadoop@centpy hadoop-2.6.]$ sqoop list-databases --connect jdbc:mysql://202.193.60.117/dataweb --username root --password-file /user/hadoop/.password
Warning: /usr/hadoop/sqoop/../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /usr/hadoop/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/hadoop/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /usr/hadoop/sqoop/../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
// :: INFO sqoop.Sqoop: Running Sqoop version: 1.4.
// :: INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
information_schema
dataweb
mysql
performance_schema
test
可以看到成功了。
Sqoop import应用场景——导入全表
1.不指定目录
sqoop import \
--connect jdbc:mysql://202.193.60.117/dataweb \
--username root \
--password-file /user/hadoop/.password \
--table user_info
运行过程如下
// :: INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:
// :: INFO db.DBInputFormat: Using read commited transaction isolation
// :: INFO db.DataDrivenDBInputFormat: BoundingValsQuery: SELECT MIN(`id`), MAX(`id`) FROM `user_info`
// :: INFO mapreduce.JobSubmitter: number of splits:
// :: INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1529567189245_0001
// :: INFO impl.YarnClientImpl: Submitted application application_1529567189245_0001
// :: INFO mapreduce.Job: The url to track the job: http://centpy:8088/proxy/application_1529567189245_0001/
// :: INFO mapreduce.Job: Running job: job_1529567189245_0001
// :: INFO mapreduce.Job: Job job_1529567189245_0001 running in uber mode : false
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: Job job_1529567189245_0001 completed successfully
// :: INFO mapreduce.Job: Counters:
File System Counters
FILE: Number of bytes read=
FILE: Number of bytes written=
FILE: Number of read operations=
FILE: Number of large read operations=
FILE: Number of write operations=
HDFS: Number of bytes read=
HDFS: Number of bytes written=
HDFS: Number of read operations=
HDFS: Number of large read operations=
HDFS: Number of write operations=
Job Counters
Launched map tasks=
Other local map tasks=
Total time spent by all maps in occupied slots (ms)=
Total time spent by all reduces in occupied slots (ms)=
Total time spent by all map tasks (ms)=
Total vcore-seconds taken by all map tasks=
Total megabyte-seconds taken by all map tasks=
Map-Reduce Framework
Map input records=
Map output records=
Input split bytes=
Spilled Records=
Failed Shuffles=
Merged Map outputs=
GC time elapsed (ms)=
CPU time spent (ms)=
Physical memory (bytes) snapshot=
Virtual memory (bytes) snapshot=
Total committed heap usage (bytes)=
File Input Format Counters
Bytes Read=
File Output Format Counters
Bytes Written=
// :: INFO mapreduce.ImportJobBase: Transferred bytes in 54.3141 seconds (0.8101 bytes/sec)
// :: INFO mapreduce.ImportJobBase: Retrieved records.
再查看一下HDFS下的运行结果

[hadoop@centpy hadoop-2.6.]$ hdfs dfs -cat /user/hadoop/user_info/part-m-*
,admin,,
,hello,,
,hahaha,haha,
运行结果和数据库内容匹配。
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
Sqoop Import HDFS的更多相关文章
- (MySQL里的数据)通过Sqoop Import HDFS 里 和 通过Sqoop Export HDFS 里的数据到(MySQL)(五)
下面我们结合 HDFS,介绍 Sqoop 从关系型数据库的导入和导出 一.MySQL里的数据通过Sqoop import HDFS 它的功能是将数据从关系型数据库导入 HDFS 中,其流程图如下所示. ...
- Sqoop Export HDFS
Sqoop Export应用场景——直接导出 直接导出 我们先复制一个表,然后将上一篇博文(Sqoop Import HDFS)导入的数据再导出到我们所复制的表里. sqoop export \ -- ...
- (MySQL里的数据)通过Sqoop Import Hive 里 和 通过Sqoop Export Hive 里的数据到(MySQL)
Sqoop 可以与Hive系统结合,实现数据的导入和导出,用户需要在 sqoop-env.sh 中添加HIVE_HOME的环境变量. 具体,见我的如下博客: hadoop2.6.0(单节点)下Sqoo ...
- (MySQL里的数据)通过Sqoop Import HBase 里 和 通过Sqoop Export HBase 里的数据到(MySQL)
Sqoop 可以与HBase系统结合,实现数据的导入和导出,用户需要在 sqoop-env.sh 中添加HBASE_HOME的环境变量. 具体,见我的如下博客: hadoop2.6.0(单节点)下Sq ...
- Hive学习之七《 Sqoop import 从关系数据库抽取到HDFS》
一.什么是sqoop Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql.postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL ...
- MSBI BigData demo—sqoop import
--sp_readerrorlog 读取错误的信息记录 exec sys.sp_readerrorlog 0, 1, 'listening'查看端口号 首先hadoop环境要配置完毕,并检验可以正常启 ...
- Hadoop生态组件Hive,Sqoop安装及Sqoop从HDFS/hive抽取数据到关系型数据库Mysql
一般Hive依赖关系型数据库Mysql,故先安装Mysql $: yum install mysql-server mysql-client [yum安装] $: /etc/init.d/mysqld ...
- 通过sqoop将hdfs数据导入MySQL
简介:Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql.postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracl ...
- 使用sqoop往hdfs中导入数据供hive使用
sqoop import -fs hdfs://x.x.x.x:8020 -jt local --connect "jdbc:oracle:thin:@x.x.x.x:1521:testdb ...
随机推荐
- Scala总结
Scala总结 ===概述 scala是一门以Java虚拟机(JVM)为目标运行环境并将面向对象和函数式编程的最佳特性结合在一起的静态类型编程语言. scala是纯粹的面向对象的语言.java虽然是面 ...
- JAVA 1.7并发之Fork/Join框架
在之前的博文里有说过executor框架,其实Fork/Join就是继承executor的升级版啦 executor用于创建一个线程池,但是需要手动的添加任务,如果需要将大型任务分治,显然比较麻烦 而 ...
- UML核心元素--参与者
定义:参与者是在系统之外与系统交互的某人或某事物.参与者在建模过程中处于核心地位. 1.系统之外:系统之外的定义说明在参与者和系统之间存在明确的边界,参与者只能存在于边界之外,边界之内的所有人和事务都 ...
- C# 播放音乐
用 .NET 自带的类库 System.Media 下面的 SoundPlayer 来播放音乐的方式,此种方式使用托管代码,应该是更为可取的方式吧 使用起来非常简单,下面稍作说明: . 支持同步.异步 ...
- IOS的设计模式
对象创建 原型(Prototype) 使用原型实例指定创建对象的种类,并通过复制这个原型创建新的对象. NSArray *array = [[NSArray alloc] initWithObject ...
- MySQL绿色版的安装步骤
由于工作需要最近要开始研究MySQL了(看来学习都是逼出来的),本人对mysql没有研究,可以说一个小白. 下面就从安装开始吧,虽然网上关于这方面的东西很多,还是需要自己把操作过程写下来. 1.数据库 ...
- 使用DOS指修改文件名
需求:将文件名中的特殊字符#和~去掉 文件夹路径如下: 开始->运行->在对话框中输入字母“cmd”,进入dos模式 输入命令行“cd c:\test”然后回车,再输入命令行“dir /b ...
- how to download a file with Nodejs(without using third-party libraries)用node下载文件
创建HTTP GET请求并将其管理response到可写文件流中: var http = require('http'); var fs = require('fs'); var file = fs. ...
- Flask17 Flask_Script插件的使用
1 什么是Flask_Script 可以对flask应用做一些统一的操作 flask_script官网:点击前往 2 安装flask_script pip install -i https://pyp ...
- Python最小二乘法解非线性超定方程组
求解非线性超定方程组,网上搜到的大多是线性方程组的最小二乘解法,对于非线性方程组无济于事. 这里分享一种方法:SciPy库的scipy.optimize.leastsq函数. import numpy ...