Sqoop Import HDFS
Sqoop import应用场景——密码访问
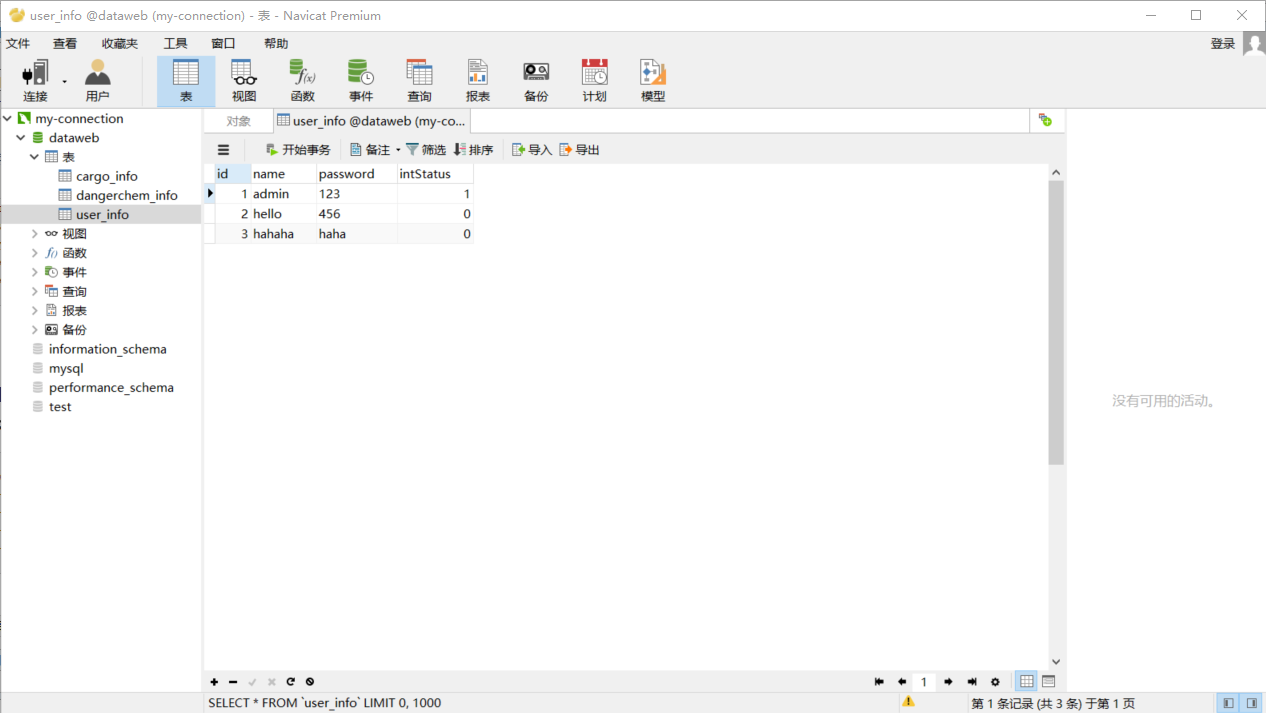
注:测试用表为本地数据库中的表
1.明码访问
sqoop list-databases \
--connect jdbc:mysql://202.193.60.117/dataweb \
--username root \
--password
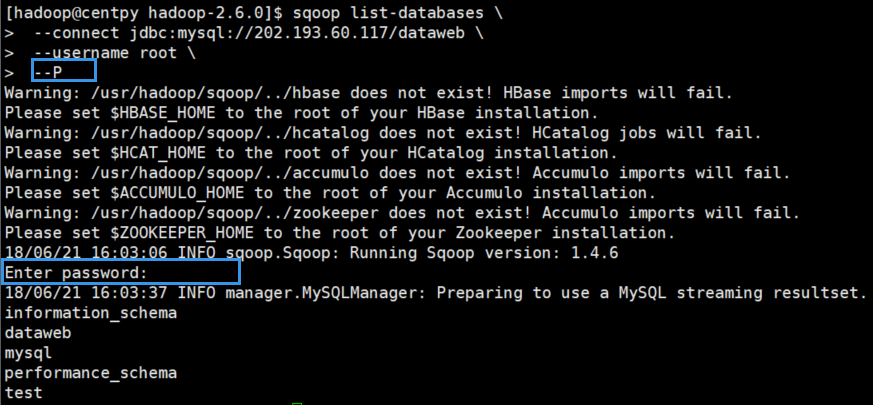
2.交互式密码
sqoop list-databases \
--connect jdbc:mysql://202.193.60.117/dataweb \
--username root \
--P
3.文件授权密码
sqoop list-databases \
--connect jdbc:mysql://202.193.60.117/dataweb \
--username root \
--password-file /usr/hadoop/.password
在运行之前先要在指定路径下创建.password文件。
[hadoop@centpy ~]$ cd /usr/hadoop/
[hadoop@centpy hadoop]$ ls
flume hadoop-2.6. sqoop
[hadoop@centpy hadoop]$ echo -n "20134997" > .password
[hadoop@centpy hadoop]$ ls -a
. .. flume hadoop-2.6. .password sqoop
[hadoop@centpy hadoop]$ more .password [hadoop@centpy hadoop]$ chmod 400 .password //根据官方文档说明赋予400权限
测试运行之后一定会报以下错误:
// :: WARN tool.BaseSqoopTool: Failed to load password file
java.io.IOException: The provided password file /usr/hadoop/.password does not exist!
at org.apache.sqoop.util.password.FilePasswordLoader.verifyPath(FilePasswordLoader.java:)
at org.apache.sqoop.util.password.FilePasswordLoader.loadPassword(FilePasswordLoader.java:)
at org.apache.sqoop.util.CredentialsUtil.fetchPasswordFromLoader(CredentialsUtil.java:)
at org.apache.sqoop.util.CredentialsUtil.fetchPassword(CredentialsUtil.java:)
at org.apache.sqoop.tool.BaseSqoopTool.applyCredentialsOptions(BaseSqoopTool.java:)
at org.apache.sqoop.tool.BaseSqoopTool.applyCommonOptions(BaseSqoopTool.java:)
at org.apache.sqoop.tool.ListDatabasesTool.applyOptions(ListDatabasesTool.java:)
at org.apache.sqoop.tool.SqoopTool.parseArguments(SqoopTool.java:)
at org.apache.sqoop.Sqoop.run(Sqoop.java:)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:)
at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:)
at org.apache.sqoop.Sqoop.main(Sqoop.java:)
Error while loading password file: The provided password file /usr/hadoop/.password does not exist!
为了解决该错误,我们需要将.password文件放到HDFS上面去,这样就能找到该文件了。
[hadoop@centpy hadoop]$ hdfs dfs -ls /
Found items
drwxr-xr-x - Zimo supergroup -- : /actor
drwxr-xr-x - Zimo supergroup -- : /counter
drwxr-xr-x - hadoop supergroup -- : /flume
drwxr-xr-x - hadoop hadoop -- : /hdfsOutput
drwxr-xr-x - Zimo supergroup -- : /join
drwxr-xr-x - hadoop supergroup -- : /maven
drwxr-xr-x - Zimo supergroup -- : /mergeSmallFiles
drwxrwxrwx - hadoop supergroup -- : /phone
drwxr-xr-x - hadoop hadoop -- : /test
drwx------ - hadoop hadoop -- : /tmp
drwxr-xr-x - hadoop hadoop -- : /weather
drwxr-xr-x - hadoop hadoop -- : /weibo
[hadoop@centpy hadoop]$ hdfs dfs -mkdir -p /user/hadoop
[hadoop@centpy hadoop]$ hdfs dfs -put .password /user/hadoop
[hadoop@centpy hadoop]$ hdfs dfs -chmod 400 /user/hadoop/.password
现在测试运行一下,注意路径改为HDFS上的/user/hadoop。
[hadoop@centpy hadoop-2.6.]$ sqoop list-databases --connect jdbc:mysql://202.193.60.117/dataweb --username root --password-file /user/hadoop/.password
Warning: /usr/hadoop/sqoop/../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /usr/hadoop/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/hadoop/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /usr/hadoop/sqoop/../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
// :: INFO sqoop.Sqoop: Running Sqoop version: 1.4.
// :: INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
information_schema
dataweb
mysql
performance_schema
test
可以看到成功了。
Sqoop import应用场景——导入全表
1.不指定目录
sqoop import \
--connect jdbc:mysql://202.193.60.117/dataweb \
--username root \
--password-file /user/hadoop/.password \
--table user_info
运行过程如下
// :: INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:
// :: INFO db.DBInputFormat: Using read commited transaction isolation
// :: INFO db.DataDrivenDBInputFormat: BoundingValsQuery: SELECT MIN(`id`), MAX(`id`) FROM `user_info`
// :: INFO mapreduce.JobSubmitter: number of splits:
// :: INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1529567189245_0001
// :: INFO impl.YarnClientImpl: Submitted application application_1529567189245_0001
// :: INFO mapreduce.Job: The url to track the job: http://centpy:8088/proxy/application_1529567189245_0001/
// :: INFO mapreduce.Job: Running job: job_1529567189245_0001
// :: INFO mapreduce.Job: Job job_1529567189245_0001 running in uber mode : false
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: Job job_1529567189245_0001 completed successfully
// :: INFO mapreduce.Job: Counters:
File System Counters
FILE: Number of bytes read=
FILE: Number of bytes written=
FILE: Number of read operations=
FILE: Number of large read operations=
FILE: Number of write operations=
HDFS: Number of bytes read=
HDFS: Number of bytes written=
HDFS: Number of read operations=
HDFS: Number of large read operations=
HDFS: Number of write operations=
Job Counters
Launched map tasks=
Other local map tasks=
Total time spent by all maps in occupied slots (ms)=
Total time spent by all reduces in occupied slots (ms)=
Total time spent by all map tasks (ms)=
Total vcore-seconds taken by all map tasks=
Total megabyte-seconds taken by all map tasks=
Map-Reduce Framework
Map input records=
Map output records=
Input split bytes=
Spilled Records=
Failed Shuffles=
Merged Map outputs=
GC time elapsed (ms)=
CPU time spent (ms)=
Physical memory (bytes) snapshot=
Virtual memory (bytes) snapshot=
Total committed heap usage (bytes)=
File Input Format Counters
Bytes Read=
File Output Format Counters
Bytes Written=
// :: INFO mapreduce.ImportJobBase: Transferred bytes in 54.3141 seconds (0.8101 bytes/sec)
// :: INFO mapreduce.ImportJobBase: Retrieved records.
再查看一下HDFS下的运行结果

[hadoop@centpy hadoop-2.6.]$ hdfs dfs -cat /user/hadoop/user_info/part-m-*
,admin,,
,hello,,
,hahaha,haha,
运行结果和数据库内容匹配。
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
Sqoop Import HDFS的更多相关文章
- (MySQL里的数据)通过Sqoop Import HDFS 里 和 通过Sqoop Export HDFS 里的数据到(MySQL)(五)
下面我们结合 HDFS,介绍 Sqoop 从关系型数据库的导入和导出 一.MySQL里的数据通过Sqoop import HDFS 它的功能是将数据从关系型数据库导入 HDFS 中,其流程图如下所示. ...
- Sqoop Export HDFS
Sqoop Export应用场景——直接导出 直接导出 我们先复制一个表,然后将上一篇博文(Sqoop Import HDFS)导入的数据再导出到我们所复制的表里. sqoop export \ -- ...
- (MySQL里的数据)通过Sqoop Import Hive 里 和 通过Sqoop Export Hive 里的数据到(MySQL)
Sqoop 可以与Hive系统结合,实现数据的导入和导出,用户需要在 sqoop-env.sh 中添加HIVE_HOME的环境变量. 具体,见我的如下博客: hadoop2.6.0(单节点)下Sqoo ...
- (MySQL里的数据)通过Sqoop Import HBase 里 和 通过Sqoop Export HBase 里的数据到(MySQL)
Sqoop 可以与HBase系统结合,实现数据的导入和导出,用户需要在 sqoop-env.sh 中添加HBASE_HOME的环境变量. 具体,见我的如下博客: hadoop2.6.0(单节点)下Sq ...
- Hive学习之七《 Sqoop import 从关系数据库抽取到HDFS》
一.什么是sqoop Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql.postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL ...
- MSBI BigData demo—sqoop import
--sp_readerrorlog 读取错误的信息记录 exec sys.sp_readerrorlog 0, 1, 'listening'查看端口号 首先hadoop环境要配置完毕,并检验可以正常启 ...
- Hadoop生态组件Hive,Sqoop安装及Sqoop从HDFS/hive抽取数据到关系型数据库Mysql
一般Hive依赖关系型数据库Mysql,故先安装Mysql $: yum install mysql-server mysql-client [yum安装] $: /etc/init.d/mysqld ...
- 通过sqoop将hdfs数据导入MySQL
简介:Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql.postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracl ...
- 使用sqoop往hdfs中导入数据供hive使用
sqoop import -fs hdfs://x.x.x.x:8020 -jt local --connect "jdbc:oracle:thin:@x.x.x.x:1521:testdb ...
随机推荐
- puppet前端管理工具foreman-proxy bind 127.0.0.1:8443问题解决
最近在玩foreman,发现部署foreman-proxy的时候,总是出现8443bind在127.0.0.1端口,导致无法访问的情况. 如下图: 经过strace -o log.txt bin/sm ...
- Python:模块详解及import本质
转于:http://www.cnblogs.com/itfat/p/7481972.html 博主:东大网管 一.定义: 模块:用来从逻辑上组织python代码(变量,函数,类,逻辑:实现一个功能), ...
- 配置IIS服务:无法找到该页 您正在搜索的页面可能已经删除、更名或暂时不可用。
1.配置IIS服务器时,在默认网站创建虚拟目录XXX.然后右击启动页面.aspx,“浏览” 2. 出现错误: 无法找到该页 您正在搜索的页面可能已经删除.更名或暂时不可用. ------------ ...
- oop的方式来操纵时间
减少return 减少传参. 主要是在调用上比以前强大很多,以前很怕操作时间,在一堆函数中传来传去.这个调用爽. class DatetimeConverter: DATETIME_FORMATTER ...
- NET项目中分页方法
/// <summary> /// 获得查询分页数据 /// </summary> public DataSet GetList(int pageSize, int pageI ...
- AngularJs(Part 9)--AngularJS 表单
AngularJS 表单 AngularJS使用了MVX的结构,我们可以是传统的表单更加强大.比如过去我们得自己写一大堆验证,比过过去我们得自己转换用户的输入, 现在这些工作全部可以交给Ang ...
- jdk 安装及环境变量配置
一.jdk安装及基础配置,转自文章来源:http://www.cnblogs.com/smyhvae/p/3788534.html 1.jdk下载及安装 下载网站:http://www.oracle. ...
- jquery 选择器的总结
元素选择 $("input") id选择 $('#id') class选择 $('.id') 属性选择 $('[prop]')或者$('[prop=“value1”]')或者$(' ...
- hdu1054
/* [题意] 给定一棵树,标记一节点,则与该节点所连的边都被标记,问最少需要标记多少个节点使得所有边都被标记: 或者说给定一个树型城堡,在交叉路口放一个士兵,则与该路口相连的路都被守住, 问最少需要 ...
- htmlparser API
htmlparser所有的filter htmlparser所有的Tags htmlparser API: http://htmlparser.sourceforge.net/javadoc/inde ...