使用IDEA开发SPARK提交remote cluster执行
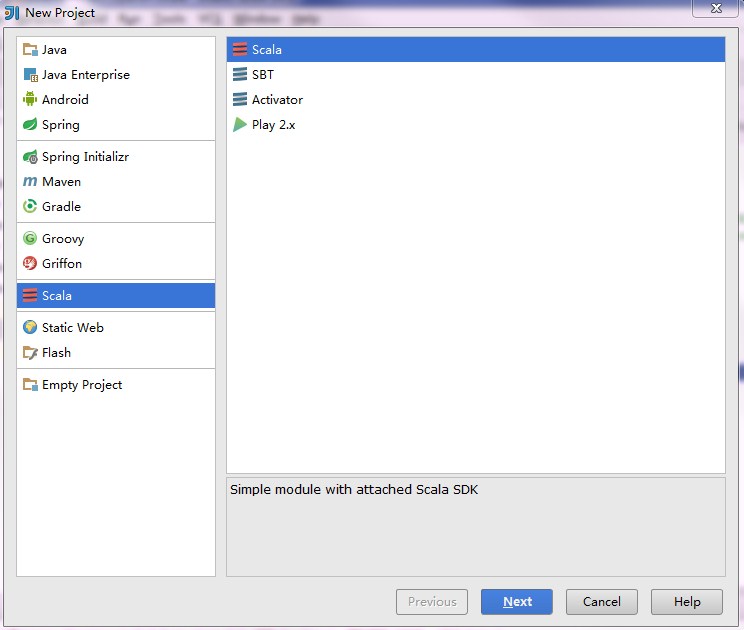
开发环境
使用IDEA开发spark应用
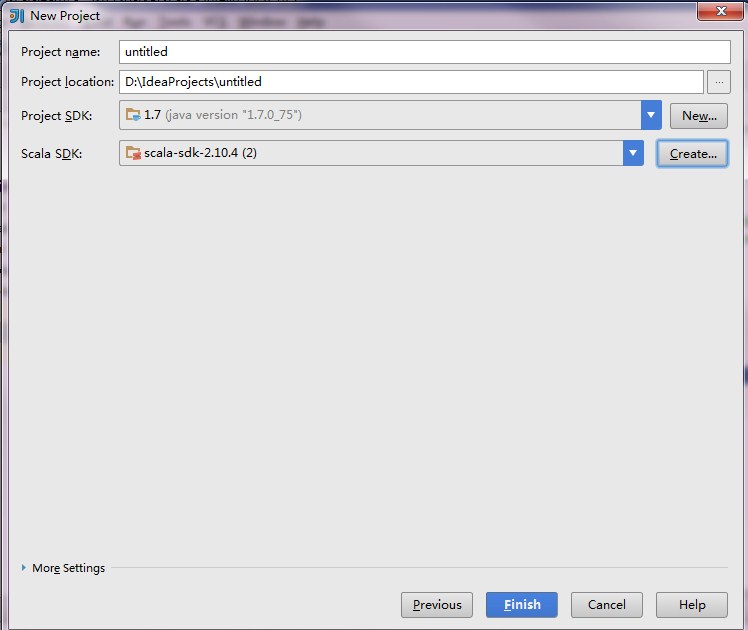

import scala.math.randomimport org.apache.spark._/** Computes an approximation to pi */object SparkPi{def main(args:Array[String]){val conf =newSparkConf().setAppName("Spark Pi").setMaster("spark://192.168.1.88:7077").set("spark.driver.host","192.168.1.129").setJars(List("D:\\IdeaProjects\\scalalearn\\out\\artifacts\\scalalearn\\scalalearn.jar"))val spark =newSparkContext(conf)val slices =if(args.length >0) args(0).toInt else2val n =100000* slicesval count = spark.parallelize(1 to n, slices).map { i =>val x = random *2-1val y = random *2-1if(x*x + y*y <1)1else0}.reduce(_ + _)println("Pi is roughly "+4.0* count / n)spark.stop()}}
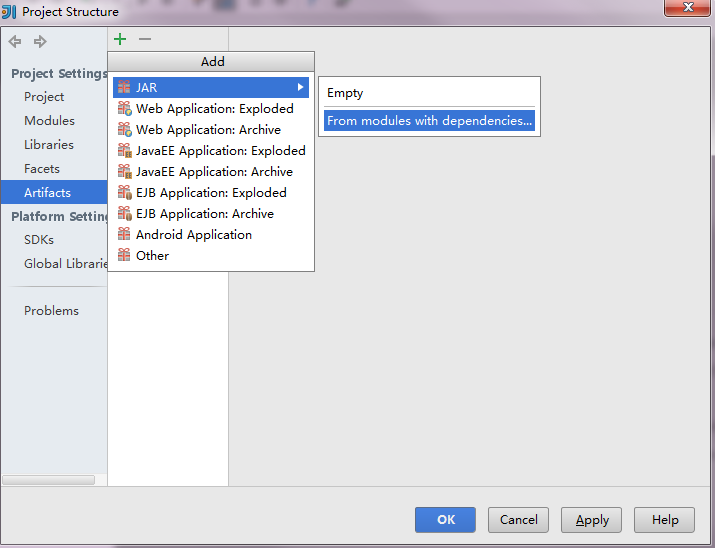
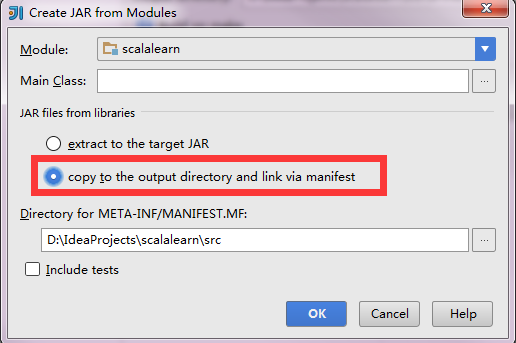
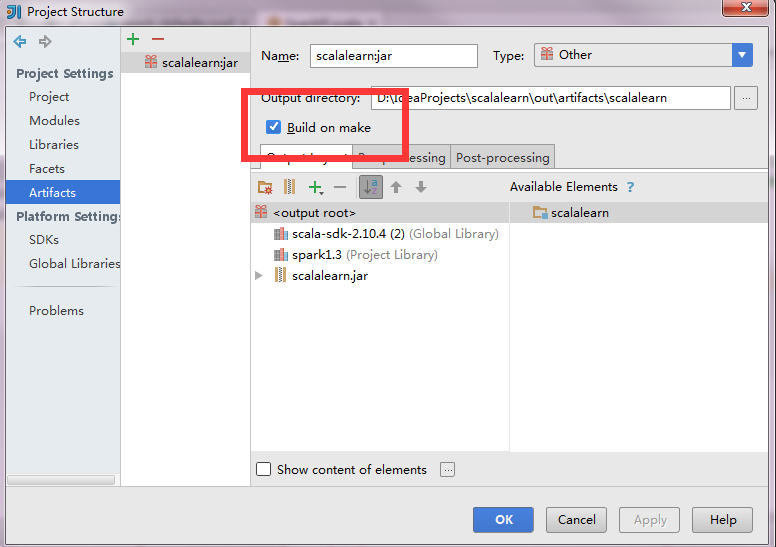
向远程spark集群提交应用
使用IDEA开发SPARK提交remote cluster执行的更多相关文章
- Spark进阶之路-Spark提交Jar包执行
Spark进阶之路-Spark提交Jar包执行 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在实际开发中,使用spark-submit提交jar包是很常见的方式,因为用spark ...
- 基于Livy的Spark提交平台搭建与开发
为了方便使用Spark的同学提交任务以及加强任务管理等原因,经调研采用Livy比较靠谱,下图大致罗列一下几种提交平台的差别. 本文会以基于mac的单机环境搭建一套Spark+Livy+Hadoop来展 ...
- 大数据笔记(二十八)——执行Spark任务、开发Spark WordCount程序
一.执行Spark任务: 客户端 1.Spark Submit工具:提交Spark的任务(jar文件) (*)spark提供的用于提交Spark任务工具 (*)example:/root/traini ...
- Spark教程——(11)Spark程序local模式执行、cluster模式执行以及Oozie/Hue执行的设置方式
本地执行Spark SQL程序: package com.fc //import common.util.{phoenixConnectMode, timeUtil} import org.apach ...
- 【原创】大叔经验分享(19)spark on yarn提交任务之后执行进度总是10%
spark 2.1.1 系统中希望监控spark on yarn任务的执行进度,但是监控过程发现提交任务之后执行进度总是10%,直到执行成功或者失败,进度会突然变为100%,很神奇, 下面看spark ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- spark提交命令 spark-submit 的参数 executor-memory、executor-cores、num-executors、spark.default.parallelism分析
转载:https://blog.csdn.net/zimiao552147572/article/details/96482120 nohup spark-submit --master yarn - ...
- spark提交应用的方法(spark-submit)
参考自:https://spark.apache.org/docs/latest/submitting-applications.html 常见的语法: ./bin/spark-submit \ ...
- FusionInsight大数据开发---Spark应用开发
Spark应用开发 要求: 了解Spark基本原理 搭建Spark开发环境 开发Spark应用程序 调试运行Spark应用程序 YARN资源调度,可以和Hadoop集群无缝对接 Spark适用场景大多 ...
随机推荐
- 【剑指offer】以o(1)复杂度删除啊链表的节点,C++实现(链表)
0.简介 本文是牛客网<剑指offer>刷题笔记. 1.题目 在O(1)时间内删除链表节点. 2.思路 前提条件:删除的节点在链表上:边界条件:链表 ...
- 461. Hamming Distance Add to List
// 快速法求1的个数 int BitCount2(unsigned int n) { unsigned ; ; n; ++c) { n &= (n -) ; // 清除最低位的1 } ret ...
- webpack 故障处理
Webpack 的配置比较复杂,很容出现错误,下面是一些通常的故障处理手段. 一般情况下,webpack 如果出问题,会打印一些简单的错误信息,比如模块没有找到.我们还可以通过参数 --display ...
- 设置Qt应用程序图标及应用程序名 【转载】
一直以来很纠结给qt应用程序添加图标问题,在网上收过一次,但是感觉不够完整,现将自己的实现过程记录下,以便以后查看: 通过网上的例子知道qt助手中有相关说明: Setting the Applicat ...
- redis之 centos 6.7 下安装 redis-3.2.5
前期准备:1. 操作系统需要安装 gcc 包 与 TCL 库, 通过配置本地 yum 源 ,yum -y install gcc . yum -y install tcl安装2. 下载 redis ...
- java编程思想第八章多态
前言: 封装:通过合并特征和行为创建新的数据类型. 实现隐藏:通过将细节“私有化”,把接口和实现分离. 多态:消除类型间的耦合关系.也称作动态绑定,后期绑定或运行时绑定. 8.1再论向上转型: 对象既 ...
- pt-query-digest工具的功能介绍了:
Ok,可以查看 pt-query-digest工具的功能介绍了: [root@472322 percona-toolkit-2.2.5]# pt-query-digest --help pt-quer ...
- AFN 请求数据https
第一步: 导入afn库 第二步: 在pch中添加 #import <SystemConfiguration/SystemConfiguration.h> #import <Mobil ...
- (转)C#程序开发中经常遇到的10条实用的代码
原文地址:http://www.cnblogs.com/JamesLi2015/p/3147986.html 1 读取操作系统和CLR的版本 OperatingSystem os = System.E ...
- Solaris与Windows Active Directory集成
通过Solaris与Active Directory的集成,Solaris可以使用Windows 2003 R2/ 2008 Active Directory来进行用户登录验证.以下是简要配置过程. ...