CUDA memory
CUDA存储器类型:
每个线程拥有自己的register and loacal memory;
每个线程块拥有一块shared memory;
所有线程都可以访问global memory;
还有,可以被所有线程访问的只读存储器:constant memory and texture memory
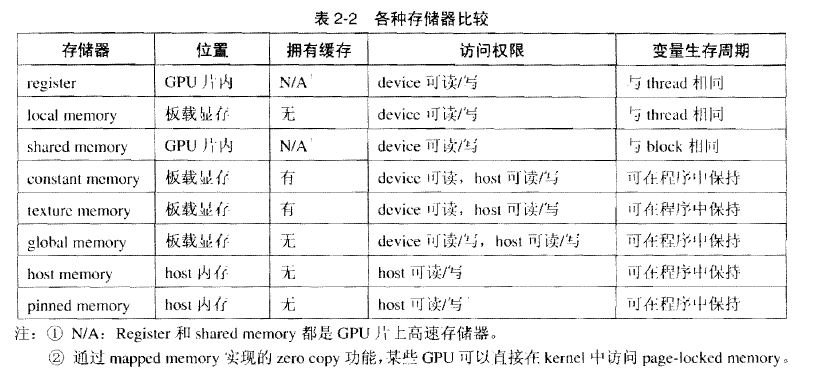
1、 寄存器Register
寄存器是GPU上的高速缓存器,其基本单元是寄存器文件,每个寄存器文件大小为32bit.
Kernel中的局部(简单类型)变量第一选择是被分配到Register中。
特点:每个线程私有,速度快。
2、 局部存储器 local memory
当register耗尽时,数据将被存储到local memory。如果每个线程中使用了过多的寄存器,或声明了大型结构体或数组,或编译器无法确定数组大小,线程的私有数据就会被分配到local memory中。
特点:每个线程私有;没有缓存,慢。
注:在声明局部变量时,尽量使变量可以分配到register。如:
unsigned int mt[3];
改为: unsigned int mt0, mt1, mt2;
3、 共享存储器 shared memory
可以被同一block中的所有线程读写
特点:block中的线程共有;访问共享存储器几乎与register一样快.

1 //u(i)= u(i)^2 + u(i-1)
2 //Static
3 __global__ example(float* u) {
4 int i=threadIdx.x;
5 __shared__ int tmp[4];
6 tmp[i]=u[i];
7 u[i]=tmp[i]*tmp[i]+tmp[3-i];
8 }
9
10 int main() {
11 float hostU[4] = {1, 2, 3, 4};
12 float* devU;
13 size_t size = sizeof(float)*4;
14 cudaMalloc(&devU, size);
15 cudaMemcpy(devU, hostU, size,
16 cudaMemcpyHostToDevice);
17 example<<<1,4>>>(devU, devV);
18 cudaMemcpy(hostU, devU, size,
19 cudaMemcpyDeviceToHost);
20 cudaFree(devU);
21 return 0;
22 }
23
24 //Dynamic
25 extern __shared__ int tmp[];
26
27 __global__ example(float* u) {
28 int i=threadIdx.x;
29 tmp[i]=u[i];
30 u[i]=tmp[i]*tmp[i]+tmp[3-i];
31 }
32
33 int main() {
34 float hostU[4] = {1, 2, 3, 4};
35 float* devU;
36 size_t size = sizeof(float)*4;
37 cudaMalloc(&devU, size);
38 cudaMemcpy(devU, hostU, size, cudaMemcpyHostToDevice);
39 example<<<1,4,size>>>(devU, devV);
40 cudaMemcpy(hostU, devU, size, cudaMemcpyDeviceToHost);
41 cudaFree(devU);
42 return 0;
43 }
4、 全局存储器 global memory
特点:所有线程都可以访问;没有缓存
//Dynamic
__global__ add4f(float* u, float* v) {
int i=threadIdx.x;
u[i]+=v[i];
}
int main() {
float hostU[4] = {1, 2, 3, 4};
float hostV[4] = {1, 2, 3, 4};
float* devU, devV;
size_t size = sizeof(float)*4;
cudaMalloc(&devU, size);
cudaMalloc(&devV, size);
cudaMemcpy(devU, hostU, size,
cudaMemcpyHostToDevice);
cudaMemcpy(devV, hostV, size,
cudaMemcpyHostToDevice);
add4f<<<1,4>>>(devU, devV);
cudaMemcpy(hostU, devU, size,
cudaMemcpyDeviceToHost);
cudaFree(devV);
cudaFree(devU);
return 0;
} //static
__device__ float devU[4];
__device__ float devV[4]; __global__ addUV() {
int i=threadIdx.x;
devU[i]+=devV[i];
} int main() {
float hostU[4] = {1, 2, 3, 4};
float hostV[4] = {1, 2, 3, 4};
size_t size = sizeof(float)*4;
cudaMemcpyToSymbol(devU, hostU, size, 0, cudaMemcpyHostToDevice);
cudaMemcpyToSymbol(devV, hostV, size, 0, cudaMemcpyHostToDevice);
addUV<<<1,4>>>();
cudaMemcpyFromSymbol(hostU, devU, size, 0, cudaMemcpyDeviceToHost);
return 0;
}
5、 常数存储器constant memory
用于存储访问频繁的只读参数
特点:只读;有缓存;空间小(64KB)
注:定义常数存储器时,需要将其定义在所有函数之外,作用于整个文件
1 __constant__ int devVar;
2 cudaMemcpyToSymbol(devVar, hostVar, sizeof(int), 0, cudaMemcpyHostToDevice)
3 cudaMemcpyFromSymbol(hostVar, devVar, sizeof(int), 0, cudaMemcpyDeviceToHost)
6、 纹理存储器 texture memory
是一种只读存储器,其中的数据以一维、二维或者三维数组的形式存储在显存中。在通用计算中,其适合实现图像处理和查找,对大量数据的随机访问和非对齐访问也有良好的加速效果。
特点:具有纹理缓存,只读。
CUDA memory的更多相关文章
- CUDA ---- Memory Model
Memory kernel性能高低是不能单纯的从warp的执行上来解释的.比如之前博文涉及到的,将block的维度设置为warp大小的一半会导致load efficiency降低,这个问题无法用war ...
- CUDA ---- Memory Access
Memory Access Patterns 大部分device一开始从global Memory获取数据,而且,大部分GPU应用表现会被带宽限制.因此最大化应用对global Memory带宽的使用 ...
- 并行程序设计---cuda memory
CUDA存储器模型: GPU片内:register,shared memory: host 内存: host memory, pinned memory. 板载显存:local memory,cons ...
- cuda培训素材
http://www.geforce.cn/hardware/desktop-gpus/geforce-gtx-480/architecture http://cache.baiducontent.c ...
- 详解第一个CUDA程序kernel.cu
CUDA是一个基于NVIDIA GPU的并行计算平台和编程模型,通过调用CUDA提供的API,可以开发高性能的并行程序.CUDA安装好之后,会自动配置好VS编译环境,按照UCDA模板新建一个工程&qu ...
- 2.2CUDA-Memory(存储)和bank-conflict
在CUDA基本概念介绍有简单介绍CUDA memory.这里详细介绍: 每一个线程拥有自己的私有存储器,每一个线程块拥有一块共享存储器(Shared memory):最后,grid中所有的线程都可以访 ...
- [源码解析] PyTorch 流水线并行实现 (2)--如何划分模型
[源码解析] PyTorch 流水线并行实现 (2)--如何划分模型 目录 [源码解析] PyTorch 流水线并行实现 (2)--如何划分模型 0x00 摘要 0x01 问题 0x01 自动平衡 1 ...
- 如何设计一个高内聚低耦合的模块——MegEngine 中自定义 Op 系统的实践经验
作者:褚超群 | 旷视科技 MegEngine 架构师 背景介绍 在算法研究的过程中,算法同学们可能经常会尝试定义各种新的神经网络层(neural network layer),比如 Layer No ...
- TensorRT 开始
TensorRT 是 NVIDIA 自家的高性能推理库,其 Getting Started 列出了各资料入口,如下: 本文基于当前的 TensorRT 8.2 版本,将一步步介绍从安装,直到加速推理自 ...
随机推荐
- 转 rac中并行 PARALLEL 的设置
sample 1: rac中并 行的设置 https://blog.csdn.net/wll_1017/article/details/8285574 我们的生产库一般在节点一上的压力比较大,在节点二 ...
- Dev Express Report 学习总结(一) 基础知识总结
Dev Express,一个非常优秀的报表控件.像其他报表一样,该报表也包括几个主要部分:Report Header,Page Header,Group Header,Detail,Group Foo ...
- 为什么 c++中函数模板和类模板的 声明与定义需要放到一起?
将模板的声明与定义写在一起实在很不优雅.尝试用“传统”方法,及在.h文件里声明,在.cpp文件里定义, 然后在main函数里包含.h头文件,这样会报链接错误.why!!!!!!!!!!!!! 这是因为 ...
- 多线程编程_CyclicBarrier
1.类说明: 一个同步辅助类,它允许一组线程互相等待,直到到达某个公共屏障点 (common barrier point).在涉及一组固定大小的线程的程序中,这些线程必须不时地互相等待,此时 Cycl ...
- readline的用法
with open(r'C:\Users\admin\pycdtest\wanyue\llduizhang_20180207\33_1517970821000304388_119061116',enc ...
- eclipse中使用git下载项目
准备工作: 目的:从远程仓库github上down所需的项目 eclipse使用git插件下载github上项目 eclipse版本:eclipse4.5 64位 jdk版本:jdk-1.7 64位 ...
- ecshop点击订购、加入按钮没反应的解决方法
今天做ecshop站的时候,测试数据,发现点击订购.加入按钮都没反应,网上搜索,有些人说是修改了common.js,我将原始版本复原也没反映.后来重新安装ecshop,仔细研究发现,原来头部文件pag ...
- log4net 基础
log4net:日志输出工具. 新建工程Log4NetDemo App.config配置如下: <?xml version="1.0" encoding="utf- ...
- 【第一篇笔记】C# 全局容错,全局异常
网上找到两个方式,一个简单的只是做个记录,另一个能像QQ一样提交到后台. 方法一: static class Program { /// <summary> /// 应用程序的主入口点. ...
- #if #endif #elif #undef
#define aaa //放在代码最前面 int a = 1; a = a + 1; #if !aaa {a = a + 1;}#elif !aaaaa {a=a+11;}#en ...