SQLServer存储引擎——01.数据库如何读写数据
一、引言
在SQL Server数据库中,数据是如何被读写的?日志里都有些什么?和数据页之间是什么关系?数据页又是如何存放数据的?索引又是用来干嘛的?
一起看看SQL Server的存储引擎。
二、SQL Server的存储引擎
大致分为以下几部分:
1. 数据库如何读写数据
2. 内存
3. 日志
4. 数据
5. 索引的结构和分类
6.索引的遍历和维护
下面一 一详细介绍:
1. 数据库如何读写数据
1.1. 数据读写流程简要
SQL Server作为一个关系型的数据库,自然也维持了事务的ACID特性,数据库的读写冲突由事务的隔离级别控制。无论有没有显式开启事务,事务都是存在的。
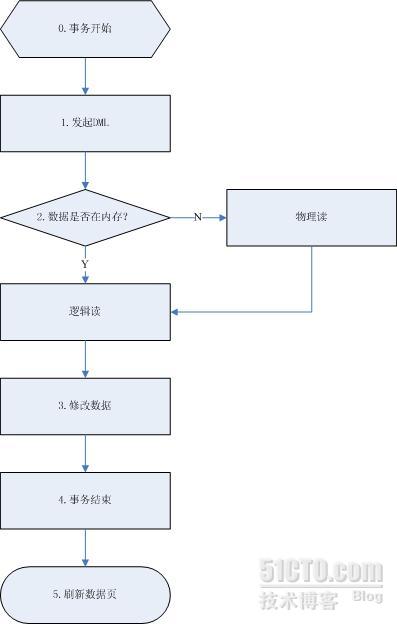
(1)事务开始
(1.1)所有DML语句必然是基于事务的,如果没有显式开启事务(即手动写下begin tran),则事务处理的最小单位是每一条DML语句,并自动提交事务。
(1.2)如果手动开启一个事务(begin tran),或开启隐式事务(set implicit_transactions on),才需要手动提交事务(commit tran),否则SQL Server自动提交事务。
(2)发起DML
(2.1)DML语句包括:insert、delete、update;
(2.2)DDL语句最终是被转化为对系统表的DML,在SQL SERVER中DDL语句也可以被回滚,比如:CREATE/ALTER/DROP/TRUNCATE,在ORACLE里是不可以的,另外SQL Server中的DCL语句:DENY,REVOKE,也可以被回滚;
(3)数据是否在内存
(3.1)在内存中使用hash算法查找数据,如果找到记为逻辑读;
(3.2)如果数据页不在内存中,则需要从磁盘上的数据文件中,读取相应的数据页到内存中,即物理读,物理读也会被记数为逻辑读,也就是说无论内存中有没有数据,逻辑读是一定有的。
(4)修改数据
(4.1)在SQL Server内存的数据缓冲区中将数据页修改,此时数据页称为脏页(Dirty Page);
(4.2)在SQL Server内存的日志缓冲区中记录REDO LOG,暂称为脏日志;
(5)事务结束
(5.1)提交(COMMIT),此时将当前事务的脏日志刷新到数据库的日志文件中,并打上事务结束标记(COMMIT),脏页有可能暂未被刷新到数据文件中;
事务日志结构如下(可通过log explorer等工具查看)
BEGIN TRAN
DML
COMMIT TRAN
(5.2)回滚(ROLLBACK),此时读REDO LOG得到反向DML操作,反向修改脏页,正向DML 与 反向DML都会被记录在数据库的日志文件中,并打上事务结束标记(ROLLBACK),同样,脏页有可能暂未被刷新到数据文件;
事务日志结构如下:
BEGIN TRAN
DML
反向DML
ROLLBACK TRAN
不难发现,SQL SERVER的日志容易成为一个瓶颈,因为在写的同时引入了读,即引入了竞争,而ORACLE用UNDO SEGMENT很好地避免了这个问题,REDO LOG永远只是在被串行写。
(6)刷新数据页
(6.1)SQL Server数据库遵循预写日志(WAL:Write-Ahead Logging)原则,因为关系型数据库是基于事务的,而日志正是事务ACID特性的保证,也是数据恢复的保证。
(6.2)检查点(Checkpoint),检查点周期性的将脏页刷新到数据库的数据文件中,最终在日志文件上打上检查点标记(Checkpoint),至此上面事务中修改的数据被正式写入 到磁盘上的数据文件中。
-------------------------------------------------------------------------------------------------------------------------------
1.2 数据读写流程深入
试想:
(1) 日志是不是一定要在COMMIT后才写到日志文件?如果有个很长很大的事务,那么提交日志时,日志从缓冲区被写入磁盘,岂不是要等很久?
(2) 数据是不是一定要在日志提交后,发生了CHECKPOINT,才写到数据文件?如果日志一直没提交,那么数据缓冲区岂不是很拥挤?
考虑到这2点,SQL Server还会通过Log Writer/Lazy Writer不定时的刷新日志/数据到磁盘,至于日志和数据的一致性,在启动或者数据库还原时,SQL Server会去做检查,也即是我们常说的前滚(REDO)和回滚(UNDO)。

(1)SQL SERVER MEMORY
(1.1) SQL SERVER 占用服务器内存的一部分,非SQL SERVER 占用的内存,供操作系统及服务器上的其他应用程序使用;
(1.2) SQL SERVER 内存结构可分为两大块,关于内存结构参见下面说的内存部分,图中仅标出Buffer Pool中的数据及日志缓存;
(2) 事务结束
(2.1)事务结束的前提是日志缓存成功写入到日志文件中,此时,数据库才会返回事务结束的响应。也就是说客户端收到COMMIT/ROLLBACK语句运行成功的消息时,日志已被成功写入日志文件(数据还不定是否被写入数据文件);
(2.2)日志缓存并不是一定要等到事务结束时才刷新到日志文件的。
(3) LOG WRITER
(3.1)当遇到长事务时,不必等到发出事务结束命令,LOG WRITER也会周期性地将脏日志刷新到日志文件,以保证用户发出COMMIt时快速响应并结束;
(3.2)微软公司并没有公布SQL SERVER除去COMMIT外,LOG WRITER将脏日志刷新到日志文件的周期,这里可以参考ORACLE的,每3秒;或者日志缓冲区1/3满;或者包含1M的脏日志。
(4) LAZY WRITER
(4.1)LAZY WRITER周期性扫描缓存(默认1s),维护自由页面列表(free page),根据LRU算法将已刷新到磁盘的页释放;
(4.2)如果是脏页则刷新到磁盘(这时事务可能还未提交),同样也是先将日志刷新到日志文件中,然后再将脏页刷新到数据文件中,最终内存页释放并加入自由页面列表;
(5)CHECKPOINT
(5.1)CHECKPOINT同LAZY WRITER一样也会刷新脏页到数据文件中(只刷新已提交的事务数据),但不会维护内存自由页面列表;
(5.2)可以设置SP_CONFIGURE ‘RECOVERY INTERVAL’选项来改变CHECKPOINT发生的频率,默认为1分钟一次。
小结:可以发现,数据和日志被写入数据/日志文件,并不是同步的。有可能写入/提交了日志,数据没有写入磁盘;有可能写入了数据,事务未被提交;
(1) 针对有完整事务日志,数据未被写入磁盘的情况,启动/还原数据库时,SQL SERVER做前滚(REDO);
(2) 针对有数据写入数据文件,日志未完整提交的事务,启动/还原数据库时,SQL SERVER做回滚(UNDO)。
SQLServer存储引擎——01.数据库如何读写数据的更多相关文章
- SQLServer存储引擎——03.日志
3. SQLServer存储引擎之日志篇 (3.1)日志结构 (3.1.1)物理日志 (0)物理日志即数据库的.ldf文件, 当然后缀名是可以自定义的,默认是.ldf (1)一个SqlServer数据 ...
- SQLServer存储引擎——02.内存
SQLServer存储引擎之内存篇: (1)SQL SERVER 内存结构 SQL SERVER 内存结构简图 SQL SERVER 内存空间主要可分为两部分: (1.1)可执行代码(E ...
- SQLServer存储引擎——05.索引的结构和分类
5. SQLServer存储引擎——索引的结构和分类 关系型数据库中以二维表来表达关系模型,表中的数据以页的形式存储在磁盘上,在SQL SERVER中,数据页是磁盘上8k的连续空间,那么,一个表的所有 ...
- mysql数据库 myisam数据存储引擎 表由于索引和数据导致的表损坏 的修复 和检查
一.mysqlcheck 进行表的检查和修复 1.检查mysqlisam存储引擎表的状态 #mysqlcheck -uuser -ppassword database table -c #检查单 ...
- SQLServer存储引擎——04.数据
4. SQL SERVER存储引擎之数据篇 (4.1)文件 (0)主数据文件.mdf初始文件大小至少为3MB,次要数据文件.ndf初始大小,同日志文件一样至少为512KB: (1)SQL SERVER ...
- Android数据存储引擎---SQLite数据库
目标:是否可以在PC端桌面上使用SQLite数据库制作一个财务文件? 目录: 来源: 实践: 总结和比较: SQLite数据简介 是什么,内部结构是怎样的,数据库和表的关系是什么 有什么用 常用的操作 ...
- Learning-MySQL【2】:MySQL存储引擎及数据库的操作管理
一.存储引擎 存储引擎实际上就是如何存储数据.如何为存储的数据建立索引和如何更新.查询数据.存储引擎也可以称为表类型. MySQL提供了插件式(pluggable)的存储引擎,存储引擎是基于表的.同一 ...
- MySQL存储引擎及数据库的操作管理
一.存储引擎 存储引擎实际上就是如何存储数据.如何为存储的数据建立索引和如何更新.查询数据.存储引擎也可以称为表类型. MySQL提供了插件式(pluggable)的存储引擎,存储引擎是基于表的.同一 ...
- 使用SQL-Server分区表功能提高数据库的读写性能
首先祝大家新年快乐,身体健康,万事如意. 一般来说一个系统最先出现瓶颈的点很可能是数据库.比如我们的生产系统并发量很高在跑一段时间后,数据库中某些表的数据量会越来越大.海量的数据会严重影响数据库的读写 ...
随机推荐
- Windbg内核调试之一: Vista Boot Config设置
Windbg进行内核调试,需要一些基本的技巧和设置,在这个系列文章中,我将使用Windbg过程中所遇到的一些问题和经验记录下来,算是对Kernel调试的一个总结,同时也是学习Windows系统内核的另 ...
- hdu 4336 Card Collector —— Min-Max 容斥
题目:http://acm.hdu.edu.cn/showproblem.php?pid=4336 bzoj 4036 的简单版,Min-Max 容斥即可. 代码如下: #include<cst ...
- centos6.5 安装gcc 4.9.0
wget http://gcc.skazkaforyou.com/releases/gcc-4.9.0/gcc-4.9.0.tar.gz // 下载源码 tar -zxvf gcc-4.9.0 cd ...
- Azure的CentOS上安装LIS (Linux Integration Service)
Azure上虚拟化技术都是采用的Hyper-v,每台Linux虚拟机都安装了LIS(Linux Integration Service).LIS的功能是为VM提供各种虚拟设备的驱动.所以LIS直接影响 ...
- centos 虚拟机联网
在windows主机安装centos虚拟机后,遇到虚拟机连接外网问题. 解决方案:http://blog.csdn.net/pang040328/article/details/12427359 经过 ...
- HTTP-Runoob:HTTP请求方法
ylbtech-HTTP-Runoob:HTTP请求方法 1.返回顶部 1. HTTP请求方法 根据HTTP标准,HTTP请求可以使用多种请求方法. HTTP1.0定义了三种请求方法: GET, PO ...
- Javascript ——Navigator对象
见 <Javascript 高级程序设计 第二版> P172 一.检测插件: 1.获取所有插件名称: 非IE浏览器:根据plugins数组, function getplugins() { ...
- form(去掉关闭按钮,禁止调整大小)
禁止Form窗口调整大小方法:FormBorderStyle 设为FixedSingle: 不能使用最大化窗口: MaximuzeBox 设为False: 不能使用最小化窗口: MinimizeB ...
- FFmpeg for Android compiled with x264, libass, fontconfig, freetype and fribidi
android下打算使用ffmpeg的 drawtext ,不过需要 --enable-libfreetype 但是freetype是个第三方库,所以需要先编译freetype,然后再编译ffmpe ...
- mybatis中in查询
xml配置 : <select id="selectPostIn" resultType="dasyskjcdtblVo"> SELECT SYS_ ...